大数据基础环境--jdk1.8环境安装部署
1、环境说明
1.1、机器配置说明
本次集群环境为三台linux系统机器,具体信息如下:
| 主机名称 | IP地址 | 操作系统 |
|---|---|---|
| hadoop1 | 10.0.0.20 | CentOS Linux release 7.2.1511 |
| hadoop2 | 10.0.0.21 | CentOS Linux release 7.2.1511 |
| hadoop3 | 10.0.0.22 | CentOS Linux release 7.2.1511 |
1.2、操作系统详情
本文档全程使用root用户进行操作:
[root@hadoop1 ~]# uname -r
3.10.0-327.22.2.el7.x86_64
[root@hadoop1 ~]# sestatus
SELinux status: disabled
[root@hadoop1 ~]# systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: inactive (dead)
[root@hadoop1 ~]# cat /etc/hosts
127.0.0.1 localhost
10.0.0.20 hadoop1
10.0.0.21 hadoop2
10.0.0.22 hadoop3
1.3、安装上传下载及批量管理服务工具
[root@hadoop1 ~]# yum install pssh lrzsz -y
2、ssh互信配置
Hadoop运行过程中需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH来启动和停止各个DataNode上的各种守护进程的;故在节点之间执行操作无需ssh密码交互验证,使用无密码公钥形式。
ssh-keygen
ssh-copy-id 127.0.0.1
scp -rp ~/.ssh/ hadoop2:/root/
scp -rp ~/.ssh/ hadoop3:/root/
3、jdk安装部署
3.1、下载jdk
下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
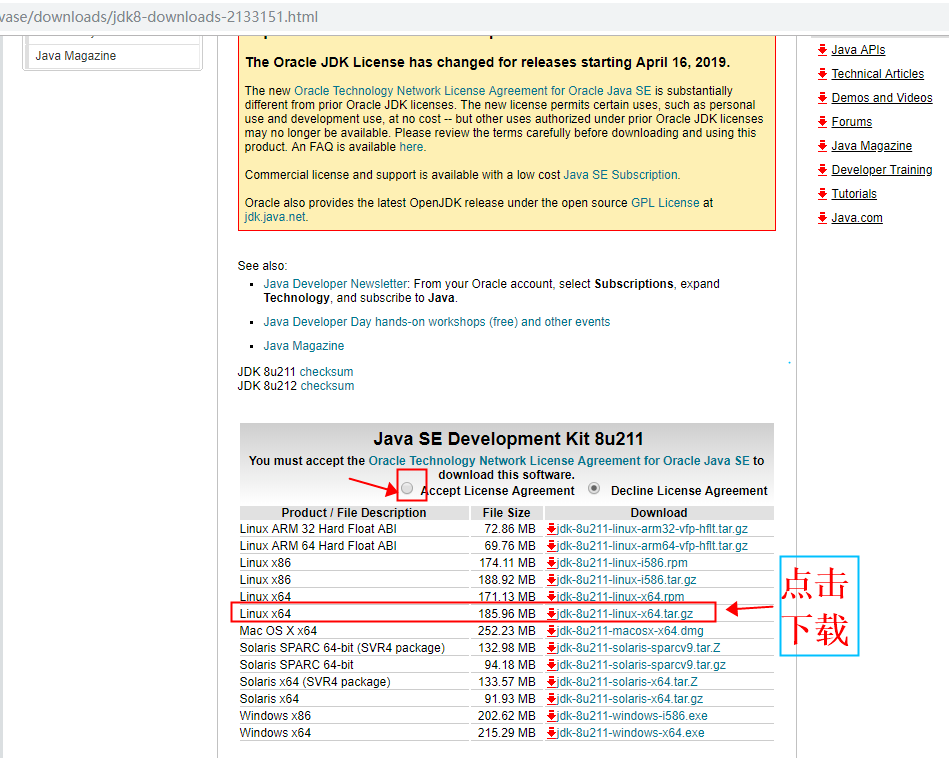
3.2、解压安装
把下载的jdk包上传到服务器中(使用rz命令上传):
tar -zxvf jdk-8u211-linux-x64.tar.gz -C /usr/local/
scp -r /usr/local/jdk1.8.0_211/ hadoop2:/usr/local/
scp -r /usr/local/jdk1.8.0_211/ hadoop3:/usr/local/
3.3、配置环境变量
添加环境变量到"/etc/profile.d/"目录:
#vim /etc/profile.d/java.sh
export JAVA_HOME=/usr/local/jdk1.8.0_211
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
验证操作:
[root@hadoop1 ~]# source /etc/profile.d/java.sh
[root@hadoop1 ~]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
3.4、传输其他机器
cd /etc/profile.d/
scp -p java.sh hadoop2:/etc/profile.d/
scp -p java.sh hadoop2:/etc/profile.d/
大数据基础环境--jdk1.8环境安装部署的更多相关文章
- 大数据学习之hdfs集群安装部署04
1-> 集群的准备工作 1)关闭防火墙(进行远程连接) systemctl stop firewalld systemctl -disable firewalld 2)永久修改设置主机名 vi ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- 在ConoHa上Centos7环境下源码安装部署LNMP
本文记录了从源码,在Centos 7上手动部署LNMP环境的过程,为了方便以后对nginx和mariadb进行升级,这里采用yum的方式进行安装. 1.建立运行网站和数据库的用户和组 groupadd ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 大数据基础-2-Hadoop-1环境搭建测试
Hadoop环境搭建测试 1 安装软件 1.1 规划目录 /opt [root@host2 ~]# cd /opt [root@host2 opt]# mkdir java [root@host2 o ...
- 大数据高可用集群环境安装与配置(04)——安装JAVA运行环境
Hadoop运行在java环境,所以在安装Hadoop之前,需要安装好jdk 提前下载好jdk安装包(jdk-8u161-linux-x64.tar.gz),将它上传到指定的安装目录当中,然后运行安装 ...
- 大数据高可用集群环境安装与配置(02)——配置ntp服务
NTP服务概述 NTP服务器[Network Time Protocol(NTP)]是用来使计算机时间同步化的一种协议,它可以使计算机对其服务器或时钟源(如石英钟,GPS等等)做同步化,它可以提供高精 ...
- Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
随机推荐
- Flutter pubspec.yaml配置文件
name: flutter_app1 # 应用名称 description: A new Flutter application. # 应用描述 # The following defines the ...
- LOJ6252. 「CodePlus 2017 11 月赛」大吉大利,晚上吃鸡! 最短路+bitset
题目传送门 https://loj.ac/problem/6252 https://lydsy.com/JudgeOnline/problem.php?id=5109 题解 首先跑最短路,只保留 \( ...
- Ubuntu16.04安装x11VNC远程桌面
1. 安装x11vnc sudo apt-get install x11vnc 2. 设置密码 x11vnc -storepasswd 3. 修改配置文件 sudu vim /lib/systemd/ ...
- 一款易用、高可定制的vue翻页组件
一款易用.高可定制的vue翻页组件 在线体验:pages.cixi518.com 使用 npm i vo-pages --save vo-pages组件父元素必须设置固定高度并填写属性overflow ...
- DELPHI 10 SEATTLE 在OSX上安装PASERVER
旧版本的DELPHI在安装目录下里的PASERVER目录有安装文件,但奇怪在这个SEATTLE上的PASERVER目录下只有一个EXE程序的安装程序,显然不能安装到OSX里,需要在Embarcad ...
- HttpClient之EntityUtils工具类
今天看到tttpclient-tutorial上面有这样一句话-----非常的不推荐使用EntityUtils,除非知道Entity是来自可信任的Http Server 而且还需要知道它的最大长度.文 ...
- 4412 GPIO初始化
一.GPIO的初始化 • 在内核源码目录下使用命令“ls drivers/gpio/*.o”,可以看到“gpioexynos4”被编译进了内核.通过搜索*.o文件,可以知道内核编译内哪些文件.针对的看 ...
- JS中数据结构之散列表
散列是一种常用的数据存储技术,散列后的数据可以快速地插入或取用.散列使用的数据 结构叫做散列表.在散列表上插入.删除和取用数据都非常快. 下面的散列表是基于数组进行设计的,数组的长度是预先设定的,如有 ...
- 【LeetCode 85】最大矩形
题目链接 [题解] 把所有的"1"矩形分成m类. 第j类的矩形.他的右边界跟第j列紧靠. 那么. 我们设f[i][j]表示(i,j)这个点往左最长能延伸多少个数目的"1& ...
- cannot access Input/output error
ls: cannot access Input/output errorls: cannot open directory .: Input/output error 硬盘故障,只读或只写,你可以d ...