使用Spark SQL的基础是“注册”(Register)若干表,表的一个重要组成部分就是模式,Spark SQL提供两种选项供用户选择:
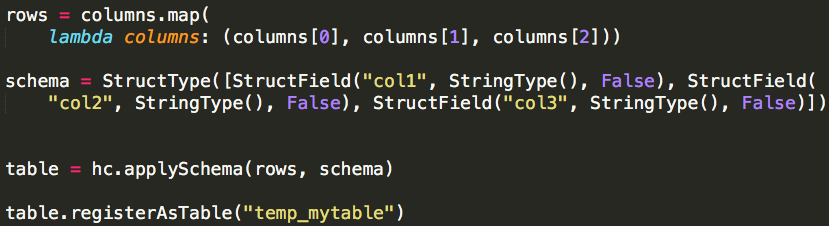
(1)applySchema
applySchema的方式需要用户编码显示指定模式,优点:数据类型明确,缺点:多表时有一定的代码工作量。
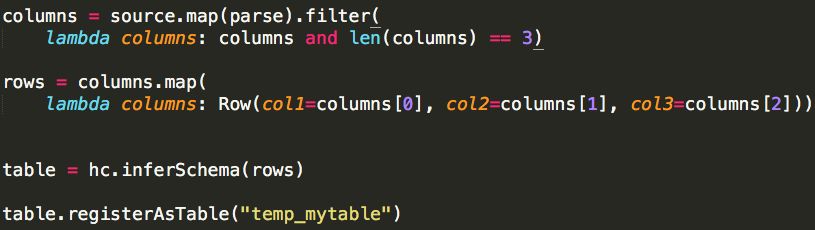
(2)inferSchema
inferSchema的方式无需用户编码显示指定模式,而是系统自动推断模式,代码比较简洁,但既然是推断,就可能出现推断错误(即与用户期望的数据类型不匹配的情况),所以我们需要对其推断过程有清晰的认识,才能在实际应用中更好的应用。
本文仅仅针对Python(spark-1.5.1)进行介绍,推断过程是依赖SQLContext(HiveContext是SQLContext的子类) inferSchema实现的:
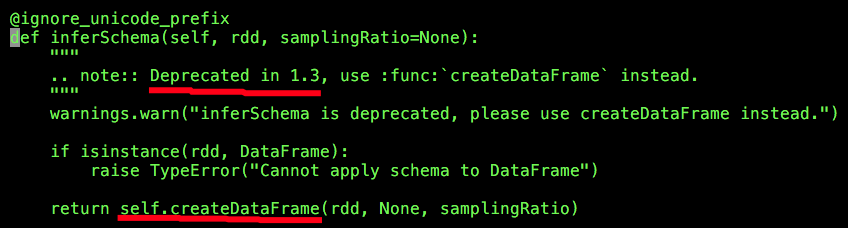
SQLContext inferSchema已经在1.3版本中被弃用,取而代之的是createDataFrame,inferSchema仍然可以在1.5.1版本中被使用,其实际执行过程就是SQLContext createDataFrame,这里需要注意一个参数samplingRation,它的默认值为None,后续会讨论它的具体作用。
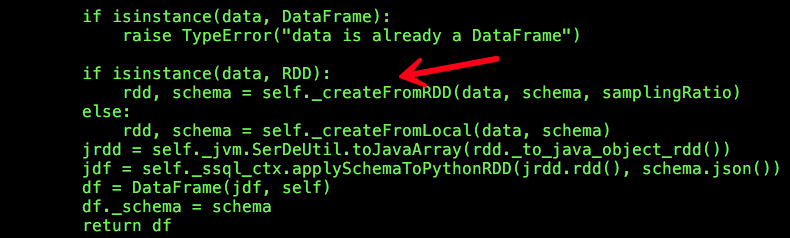
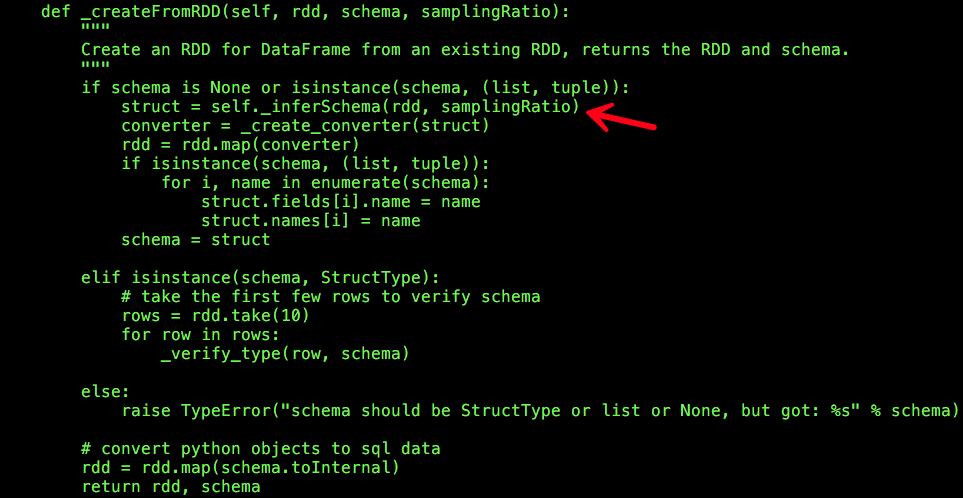
这里我们仅仅考虑从RDD推断数据类型的情况,也就是isinstance(data, RDD)为True的情况,代码执行流程转入SQLContext _createFromRDD:
从上述的代码调用逻辑可以看出,schema为None,代码执行流程转入SQLContext _inferSchema:
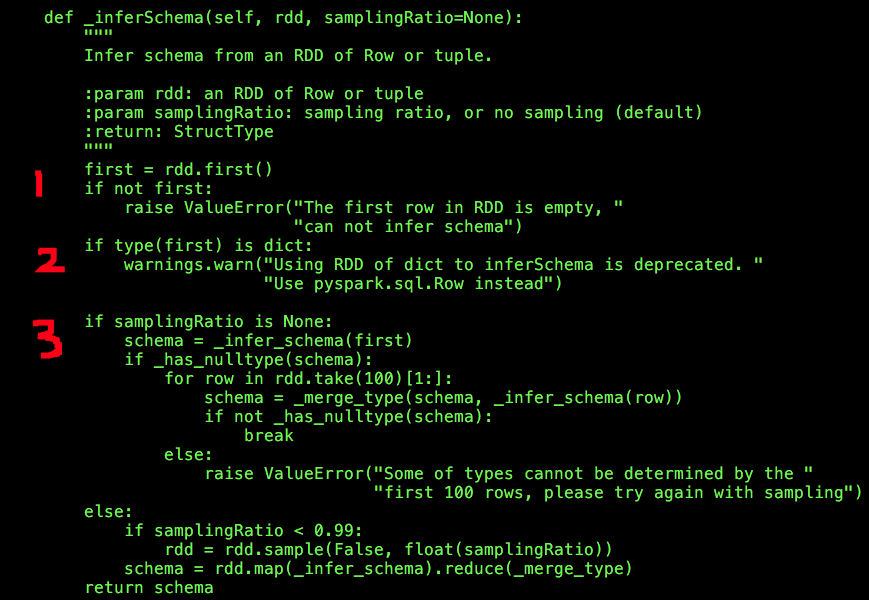
SQLContext _inferSchema的主要流程大致分为三步:
第一步:获取RDD的第一行记录first,而且要求first不能为空值(注意不是None);
第二步:如果first的类型为“dict”,会输出一条警告信息:推断模式时建议RDD的元素类型为Row(pyspark.sql.Row),dict已被弃用;
第三步:如果samplingRatio为None,则直接使用first(也就是RDD的第一条记录)推断模式;如果samplingRation不为None,则根据该值“筛选”数据推断模式。
我们将着重介绍第三步的实现逻辑。
1. samplingRatio is None
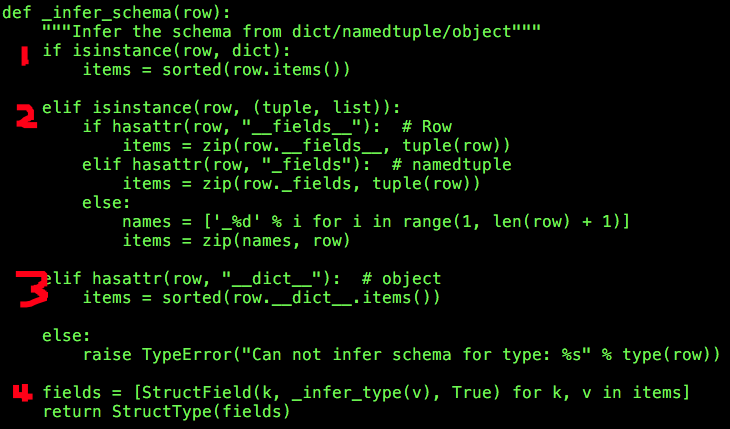
_infer_schema使用一行记录row(也就是RDD的第一行记录)推断模式,大致分为四个步骤:
(1)如果记录row的数据类型为dict;
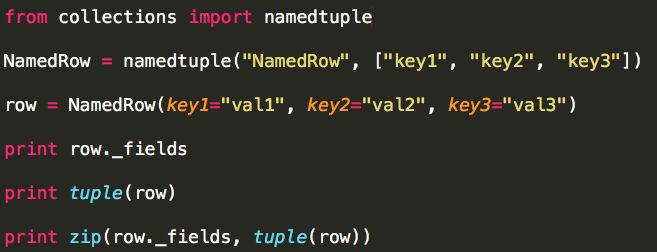
由此我们可以得出items实际就是一个键值对列表,其中键值对也可以理解为(列名,列值);之所以要进行排序操作(sorted)是为了保证列名顺序的一致性(dict.items()并不负责返回的列表元素顺序)。
(2)如果记录row的数据类型为tuple或list,可以细分为三种情况:
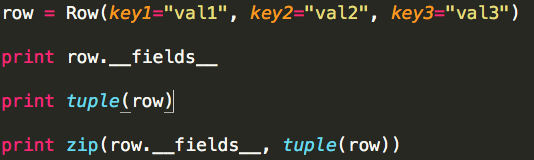
a. row的数据类型为Row,模拟处理过程:
b. row的数据类型为namedtuple,模拟处理过程:
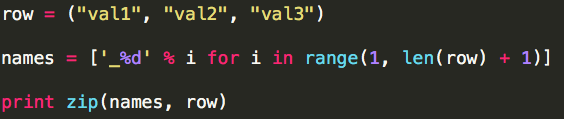
c. row的数据类型为其它(tuple or tuple),模拟处理过程:
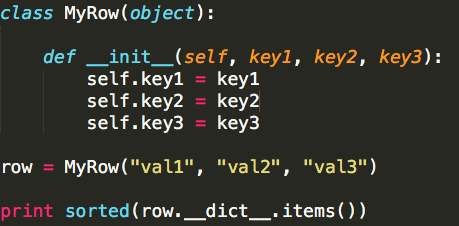
(3)如果记录row的数据类型为object;
由(1)、(2)、(3)可以看出,它们最终的逻辑是一致的,就是将记录row转换为一个键值对列表;如果(1)、(2)、(3)均不匹配,则认为无法推断,抛出异常即可。
(4)创建模式(StructType)
items中的每一个键值对会对应着形成一个StructField,StructField用于描述一个列的模式,它接收三个参数:列名、列类型、可否包含None;列名就是“键”,列类型则需要根据“值”推断(_infer_type),这里默认设置可以包含None。
迭代items中的这些键值对会形成一个StructField列表,最后通过StructType创建模式。
这是根据RDD的一行记录创建模式的过程,这其中还没有涉及具体的数据类型是如何被推断的,我们还需要看一下_infer_type:
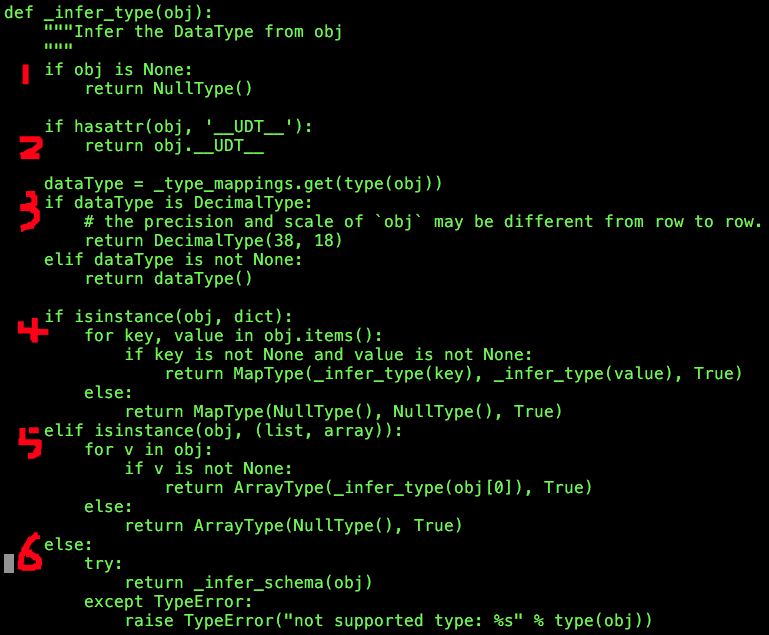
_infer_type就是根据传入的obj来推断类型的,返回值为类型实例,需要处理以下六种情况:
(1)如果obj为None,则类型为NullType;
(2)真的没有理解,不解释;
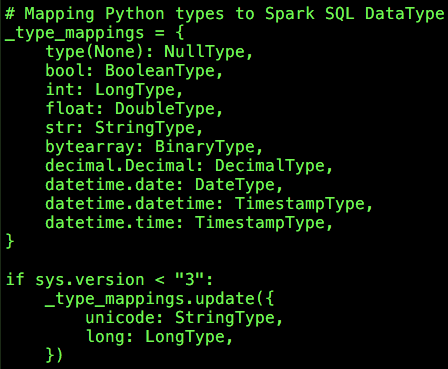
(3)尝试根据type(obj)直接从_type_mappings中获取对应的类型信息dataType,_type_mappings就是一个字典,预先保留着一些Python类型与Spark SQL数据类型的对应关系,如下:
如果dataType不为None,则直接返回相应类型的实例即可;需要特殊处理的是DecimalType,考虑到实际数据中可能存在precision和scale不一致的情况,这里统一处理为precision:38,scale:18;如果dataType为None,则表明obj为复合数据类型(数组、字典、结构体)。
(4)如果obj的数据类型为dict,我们需要分别推断它的键类型(递归调用_infer_type)、值类型(递归调用_infer_type),然后构造MapType实例并返回;
推断键、值类型时,仅仅选取某一个键值对:它的键、值均不为None,如果存在多个这样的键值对,则选取是随机的,取决于dict.items();如果找不到这样的键值对,则认为键、值的类型均为NullType。
(5)如果obj的数据类型为list或array,则选取其中某一个不为None的元素推断其类型(递归调用_infer_type);如果找不到不为None的元素,则认为元素类型为NullType;最后构造ArrayType实例并返回;
(6)如果(1)、(2)、(3)、(4)、(5)均无法完成推断,则我们认为obj可能(仅仅是可能)是一个结构体类型(StructType),使用_infer_schema推断其类型;
2. samplingRatio is not None
samplingRatio为None时,则仅仅选取RDD的第一行记录参与推断,这就对这一行记录的“质量”提出很高的要求,某些情况下它无法代表全局,此时我们可以通过显示设置samplingRatio,“筛选”足够多的数据参与推断过程。
如果samplingRatio的值小于0.99,则使用RDD sample API根据samplingRatio“筛选”部分数据(rdd)参与推断;否则整个RDD(rdd)的所有记录参与推断。
推断过程可以简单理解为两步:
(1)对于RDD中的每一行记录通过方法_infer_schema推断出一个类型(map);
(2)将这些类型进行聚合(reduce)。
我们着重看一下聚合的实现逻辑:
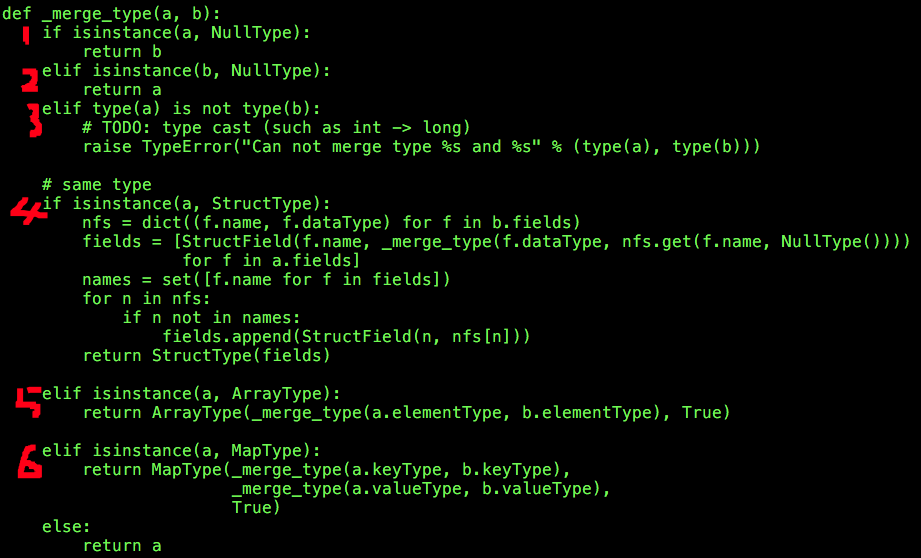
聚合的实现逻辑由方法_merge_type完成,需要处理六种情况:
(1)如果a是NullType的实例,则返回b的类型;
(2)如果a不是NullType的实例,b是NullType的实例,则返回a的类型;
(3)如果a和b的类型不相同,则抛出异常;
以下处理过程基于a和b的类型相同。
(4)如果a的类型为StructType(结构体),则以a中的各个元素为模板合并类型(递归调用_merge_type),并追加b-a(差集)的元素(类型);
(5)如果a的类型为ArrayType(数组),则合并(递归调用_merge_type)两者的元素类型即可;
(6)如果a的类型为MapType(字典),则需要分别合并两者的键类型(递归调用_merge_type)、值类型(递归调用_merge_type)。
个人觉得目前的类型聚合逻辑过于简单,实际使用意义不大。
- Spark SQL inferSchema实现原理探微(Python)【转】
使用Spark SQL的基础是“注册”(Register)若干表,表的一个重要组成部分就是模式,Spark SQL提供两种选项供用户选择: (1)applySchema applySche ...
- 第7章 Spark SQL 的运行原理(了解)
第7章 Spark SQL 的运行原理(了解) 7.1 Spark SQL运行架构 Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析.绑定.优化.执行.Spark SQL会先将 ...
- 7. Spark SQL的运行原理
7.1 Spark SQL运行架构 Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析.绑定.优化.执行.Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule) ...
- 【原创】大叔经验分享(15)spark sql limit实现原理
之前讨论过hive中limit的实现,详见 https://www.cnblogs.com/barneywill/p/10109217.html下面看spark sql中limit的实现,首先看执行计 ...
- Spark SQL / Catalyst 内部原理 与 RBO
原创文章,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/spark/rbo/ 本文所述内容均基于 2018年9月10日 Spark ...
- Spark学习之路(八)—— Spark SQL 之 DataFrame和Dataset
一.Spark SQL简介 Spark SQL是Spark中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将SQL查询与Spark程序无缝混合,允许您使用SQL或DataFrame AP ...
- Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
一.Spark SQL简介 Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 Da ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- 【原创 Hadoop&Spark 动手实践 10】Spark SQL 程序设计基础与动手实践(下)
[原创 Hadoop&Spark 动手实践 10]Spark SQL 程序设计基础与动手实践(下) 目标: 1. 深入理解Spark SQL 程序设计的原理 2. 通过简单的命令来验证Spar ...
随机推荐
- PHP之APC缓存详细介绍
1.APC缓存简介 APC,全称是Alternative PHP Cache,官方翻译叫"可选PHP缓存".它为我们提供了缓存和优化PHP的中间代码的框架. APC的缓存分两部分: ...
- PHP in_array不兼容问题
做过日本的手机端,就因为in_array这个方法在我的环境下没有问题 结果到日本那边就是出问题,一直纠结的我啊,现在特贴出当初的兼容方法 function in_into($key,$array){ ...
- [配置文件] C#修改App.config,Web.config文件帮助类,ConfigHelper (转载)
点击下载 ConfigHelper-sufei.rar 主要功能如下 .根据Key取Value值 .根据Key修改Value .添加新的Key ,Value键值对 .根据Key删除项 /// < ...
- 一个jquery的图片下拉列表 ddSlick
[ddSlick]http://designwithpc.com/Plugins/ddSlick How to use with JSON data Include the plugin javasc ...
- 简单的背包问题(入门)HDU2602 HDU2546 HDU1864
动态规划,我一直都不熟悉,因为体量不够,所以今天开始努力地学习学习. 当然背包从01开始,先选择了一个简单的经典的背包HDU2602. Many years ago , in Teddy's home ...
- 关于 const 成员函数
成员函数如果是const意味着什么? 有两个流行概念:物理常量性和逻辑常量性. C++对常量性的定义采用的是物理常量性概念,即const 成员函数不可以更改对象内任何non-static成员变量.例如 ...
- java设计模式——接口模式
java将接口的概念提升为独立的结构,体现了接口与实现分离.java接口允许多个类提供相同的功能,也允许一个同时实现多个接口.java的接口与抽象类十分相似.java与抽象类中的区别: 1.一个类可以 ...
- Git (2)
要使用Git首先遇到的问题是怎么把文件加到库中. 很简单. 新建一个目录,然后git init. 完成上述工作之后的唯一改动是在当前目录下生成了一个.git的子目录.这个子目录是一个集中的数据库,包含 ...
- 【原创】win7同局域网下共享文件
本文章用于解决win7局域网共享文件问题: 首先保证两台机器可以ping通: 检测方法: win+R输入cmd打开命令行,输入ping 对方主机ip 不知对方ip可以在在命令行中输入ipconfig ...
- 17173php招聘
学历要求:大专工作经历:4年↑薪资待遇:面议工作地点:北京市 资深PHP工程师岗位职责\\\"1.独立负责公司互联网产品的开发与测试2.主导负责相关系统维护,确保系统运行稳定可靠3.主导推动 ...