缓存淘汰算法 (http://flychao88.iteye.com/blog/1977653)
1. LRU
1.1. 原理
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
1.2. 实现
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
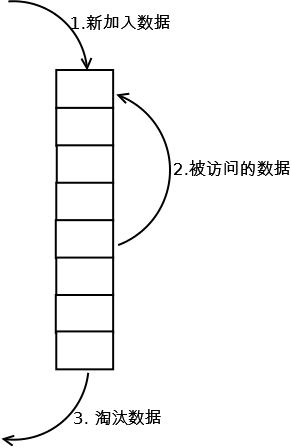
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
1.3. 分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
2. LRU-K
2.1. 原理
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
2.2. 实现
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下:
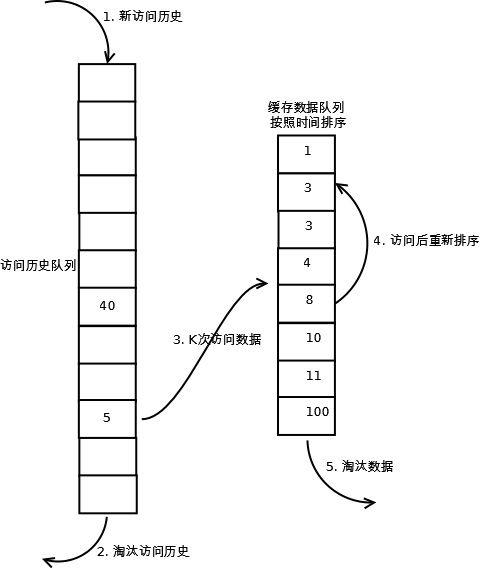
1. 数据第一次被访问,加入到访问历史列表;
2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
4. 缓存数据队列中被再次访问后,重新排序;
5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
2.3. 分析
【命中率】
LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
【代价】
由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多;当数据量很大的时候,内存消耗会比较可观。
LRU-K需要基于时间进行排序(可以需要淘汰时再排序,也可以即时排序),CPU消耗比LRU要高。
3. Two queues(2Q)
3.1. 原理
Two queues(以下使用2Q代替)算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。
3.2. 实现
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。详细实现如下:
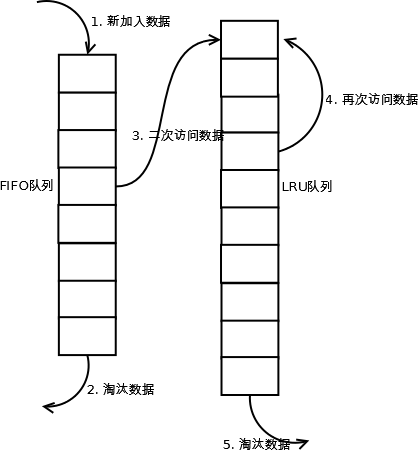
1. 新访问的数据插入到FIFO队列;
2. 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
3. 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;
4. 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
5. LRU队列淘汰末尾的数据。
注:上图中FIFO队列比LRU队列短,但并不代表这是算法要求,实际应用中两者比例没有硬性规定。
3.3. 分析
【命中率】
2Q算法的命中率要高于LRU。
【复杂度】
需要两个队列,但两个队列本身都比较简单。
【代价】
FIFO和LRU的代价之和。
2Q算法和LRU-2算法命中率类似,内存消耗也比较接近,但对于最后缓存的数据来说,2Q会减少一次从原始存储读取数据或者计算数据的操作。
4. Multi Queue(MQ)
4.1. 原理
MQ算法根据访问频率将数据划分为多个队列,不同的队列具有不同的访问优先级,其核心思想是:优先缓存访问次数多的数据。
4.2. 实现
MQ算法将缓存划分为多个LRU队列,每个队列对应不同的访问优先级。访问优先级是根据访问次数计算出来的,例如
详细的算法结构图如下,Q0,Q1....Qk代表不同的优先级队列,Q-history代表从缓存中淘汰数据,但记录了数据的索引和引用次数的队列:
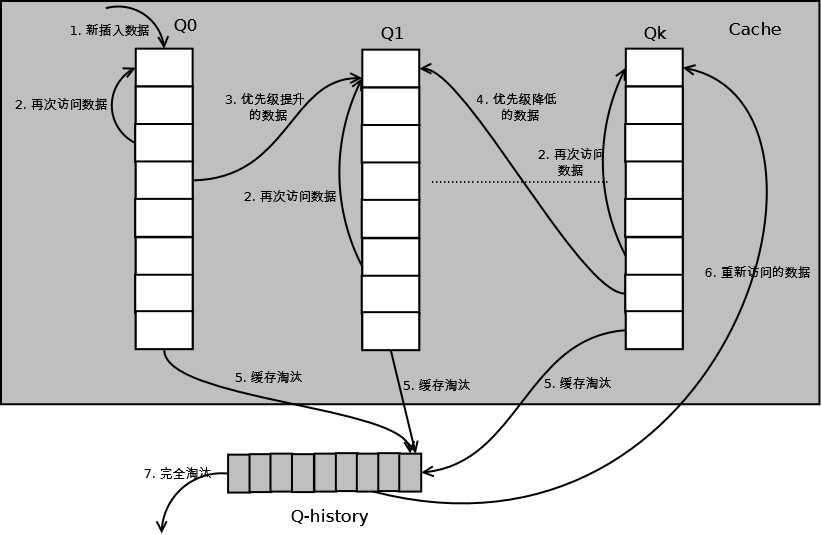
如上图,算法详细描述如下:
1. 新插入的数据放入Q0;
2. 每个队列按照LRU管理数据;
3. 当数据的访问次数达到一定次数,需要提升优先级时,将数据从当前队列删除,加入到高一级队列的头部;
4. 为了防止高优先级数据永远不被淘汰,当数据在指定的时间里访问没有被访问时,需要降低优先级,将数据从当前队列删除,加入到低一级的队列头部;
5. 需要淘汰数据时,从最低一级队列开始按照LRU淘汰;每个队列淘汰数据时,将数据从缓存中删除,将数据索引加入Q-history头部;
6. 如果数据在Q-history中被重新访问,则重新计算其优先级,移到目标队列的头部;
7. Q-history按照LRU淘汰数据的索引。
4.3. 分析
【命中率】
MQ降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
MQ需要维护多个队列,且需要维护每个数据的访问时间,复杂度比LRU高。
【代价】
MQ需要记录每个数据的访问时间,需要定时扫描所有队列,代价比LRU要高。
注:虽然MQ的队列看起来数量比较多,但由于所有队列之和受限于缓存容量的大小,因此这里多个队列长度之和和一个LRU队列是一样的,因此队列扫描性能也相近。
5. LRU类算法对比
由于不同的访问模型导致命中率变化较大,此处对比仅基于理论定性分析,不做定量分析。
|
对比点 |
对比 |
|
命中率 |
LRU-2 > MQ(2) > 2Q > LRU |
|
复杂度 |
LRU-2 > MQ(2) > 2Q > LRU |
|
代价 |
LRU-2 > MQ(2) > 2Q > LRU |
实际应用中需要根据业务的需求和对数据的访问情况进行选择,并不是命中率越高越好。例如:虽然LRU看起来命中率会低一些,且存在”缓存污染“的问题,但由于其简单和代价小,实际应用中反而应用更多。
java中最简单的LRU算法实现,就是利用jdk的LinkedHashMap,覆写其中的removeEldestEntry(Map.Entry)方法即可
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
import java.util.ArrayList;
import java.util.Collection;
import java.util.LinkedHashMap;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.Map;
/** * 类说明:利用LinkedHashMap实现简单的缓存, 必须实现removeEldestEntry方法,具体参见JDK文档
*
* @author dennis
*
* @param <K>
* @param <V>
*/ public class LRULinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private final int maxCapacity;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
private final Lock lock = new ReentrantLock();
public LRULinkedHashMap(int maxCapacity) {
super(maxCapacity, DEFAULT_LOAD_FACTOR, true);
this.maxCapacity = maxCapacity;
}
@Override protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
return size() > maxCapacity;
}
@Override public boolean containsKey(Object key) {
try {
lock.lock();
return super.containsKey(key);
} finally {
lock.unlock();
}
}
@Override public V get(Object key) {
try {
lock.lock();
return super.get(key);
} finally {
lock.unlock();
}
}
@Override public V put(K key, V value) {
try {
lock.lock();
return super.put(key, value);
} finally {
lock.unlock();
}
}
public int size() {
try {
lock.lock();
return super.size();
} finally {
lock.unlock();
}
}
public void clear() {
try {
lock.lock();
super.clear();
} finally {
lock.unlock();
}
}
public Collection<Map.Entry<K, V>> getAll() {
try {
lock.lock();
return new ArrayList<Map.Entry<K, V>>(super.entrySet());
} finally {
lock.unlock();
}
}
} |
基于双链表 的LRU实现:
传统意义的LRU算法是为每一个Cache对象设置一个计数器,每次Cache命中则给计数器+1,而Cache用完,需要淘汰旧内容,放置新内容时,就查看所有的计数器,并将最少使用的内容替换掉。
它的弊端很明显,如果Cache的数量少,问题不会很大, 但是如果Cache的空间过大,达到10W或者100W以上,一旦需要淘汰,则需要遍历所有计算器,其性能与资源消耗是巨大的。效率也就非常的慢了。
它的原理: 将Cache的所有位置都用双连表连接起来,当一个位置被命中之后,就将通过调整链表的指向,将该位置调整到链表头的位置,新加入的Cache直接加到链表头中。
这样,在多次进行Cache操作后,最近被命中的,就会被向链表头方向移动,而没有命中的,而想链表后面移动,链表尾则表示最近最少使用的Cache。
当需要替换内容时候,链表的最后位置就是最少被命中的位置,我们只需要淘汰链表最后的部分即可。
上面说了这么多的理论, 下面用代码来实现一个LRU策略的缓存。
我们用一个对象来表示Cache,并实现双链表,
- public class LRUCache {
- /**
- * 链表节点
- * @author Administrator
- *
- */
- class CacheNode {
- ……
- }
- private int cacheSize;//缓存大小
- private Hashtable nodes;//缓存容器
- private int currentSize;//当前缓存对象数量
- private CacheNode first;//(实现双链表)链表头
- private CacheNode last;//(实现双链表)链表尾
- }
public class LRUCache {
/**
* 链表节点
* @author Administrator
*
*/
class CacheNode {
……
}
private int cacheSize;//缓存大小
private Hashtable nodes;//缓存容器
private int currentSize;//当前缓存对象数量
private CacheNode first;//(实现双链表)链表头
private CacheNode last;//(实现双链表)链表尾
}
下面给出完整的实现,这个类也被Tomcat所使用( org.apache.tomcat.util.collections.LRUCache),但是在tomcat6.x版本中,已经被弃用,使用另外其他的缓存类来替代它。
- public class LRUCache {
- /**
- * 链表节点
- * @author Administrator
- *
- */
- class CacheNode {
- CacheNode prev;//前一节点
- CacheNode next;//后一节点
- Object value;//值
- Object key;//键
- CacheNode() {
- }
- }
- public LRUCache(int i) {
- currentSize = 0;
- cacheSize = i;
- nodes = new Hashtable(i);//缓存容器
- }
- /**
- * 获取缓存中对象
- * @param key
- * @return
- */
- public Object get(Object key) {
- CacheNode node = (CacheNode) nodes.get(key);
- if (node != null) {
- moveToHead(node);
- return node.value;
- } else {
- return null;
- }
- }
- /**
- * 添加缓存
- * @param key
- * @param value
- */
- public void put(Object key, Object value) {
- CacheNode node = (CacheNode) nodes.get(key);
- if (node == null) {
- //缓存容器是否已经超过大小.
- if (currentSize >= cacheSize) {
- if (last != null)//将最少使用的删除
- nodes.remove(last.key);
- removeLast();
- } else {
- currentSize++;
- }
- node = new CacheNode();
- }
- node.value = value;
- node.key = key;
- //将最新使用的节点放到链表头,表示最新使用的.
- moveToHead(node);
- nodes.put(key, node);
- }
- /**
- * 将缓存删除
- * @param key
- * @return
- */
- public Object remove(Object key) {
- CacheNode node = (CacheNode) nodes.get(key);
- if (node != null) {
- if (node.prev != null) {
- node.prev.next = node.next;
- }
- if (node.next != null) {
- node.next.prev = node.prev;
- }
- if (last == node)
- last = node.prev;
- if (first == node)
- first = node.next;
- }
- return node;
- }
- public void clear() {
- first = null;
- last = null;
- }
- /**
- * 删除链表尾部节点
- * 表示 删除最少使用的缓存对象
- */
- private void removeLast() {
- //链表尾不为空,则将链表尾指向null. 删除连表尾(删除最少使用的缓存对象)
- if (last != null) {
- if (last.prev != null)
- last.prev.next = null;
- else
- first = null;
- last = last.prev;
- }
- }
- /**
- * 移动到链表头,表示这个节点是最新使用过的
- * @param node
- */
- private void moveToHead(CacheNode node) {
- if (node == first)
- return;
- if (node.prev != null)
- node.prev.next = node.next;
- if (node.next != null)
- node.next.prev = node.prev;
- if (last == node)
- last = node.prev;
- if (first != null) {
- node.next = first;
- first.prev = node;
- }
- first = node;
- node.prev = null;
- if (last == null)
- last = first;
- }
- private int cacheSize;
- private Hashtable nodes;//缓存容器
- private int currentSize;
- private CacheNode first;//链表头
- private CacheNode last;//链表尾
- }<br style="margin: 0px; padding: 0px;"><br style="margin: 0px; padding: 0px;">
public class LRUCache {
/**
* 链表节点
* @author Administrator
*
*/
class CacheNode {
CacheNode prev;//前一节点
CacheNode next;//后一节点
Object value;//值
Object key;//键
CacheNode() {
}
}
public LRUCache(int i) {
currentSize = 0;
cacheSize = i;
nodes = new Hashtable(i);//缓存容器
}
/**
* 获取缓存中对象
* @param key
* @return
*/
public Object get(Object key) {
CacheNode node = (CacheNode) nodes.get(key);
if (node != null) {
moveToHead(node);
return node.value;
} else {
return null;
}
}
/**
* 添加缓存
* @param key
* @param value
*/
public void put(Object key, Object value) {
CacheNode node = (CacheNode) nodes.get(key);
if (node == null) {
//缓存容器是否已经超过大小.
if (currentSize >= cacheSize) {
if (last != null)//将最少使用的删除
nodes.remove(last.key);
removeLast();
} else {
currentSize++;
}
node = new CacheNode();
}
node.value = value;
node.key = key;
//将最新使用的节点放到链表头,表示最新使用的.
moveToHead(node);
nodes.put(key, node);
}
/**
* 将缓存删除
* @param key
* @return
*/
public Object remove(Object key) {
CacheNode node = (CacheNode) nodes.get(key);
if (node != null) {
if (node.prev != null) {
node.prev.next = node.next;
}
if (node.next != null) {
node.next.prev = node.prev;
}
if (last == node)
last = node.prev;
if (first == node)
first = node.next;
}
return node;
}
public void clear() {
first = null;
last = null;
}
/**
* 删除链表尾部节点
* 表示 删除最少使用的缓存对象
*/
private void removeLast() {
//链表尾不为空,则将链表尾指向null. 删除连表尾(删除最少使用的缓存对象)
if (last != null) {
if (last.prev != null)
last.prev.next = null;
else
first = null;
last = last.prev;
}
}
/**
* 移动到链表头,表示这个节点是最新使用过的
* @param node
*/
private void moveToHead(CacheNode node) {
if (node == first)
return;
if (node.prev != null)
node.prev.next = node.next;
if (node.next != null)
node.next.prev = node.prev;
if (last == node)
last = node.prev;
if (first != null) {
node.next = first;
first.prev = node;
}
first = node;
node.prev = null;
if (last == null)
last = first;
}
private int cacheSize;
private Hashtable nodes;//缓存容器
private int currentSize;
private CacheNode first;//链表头
private CacheNode last;//链表尾
}
缓存淘汰算法 (http://flychao88.iteye.com/blog/1977653)的更多相关文章
- 缓存淘汰算法--LRU算法(转)
(转自:http://flychao88.iteye.com/blog/1977653) 1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访 ...
- 04 | 链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是+LRU+缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 数据结构与算法之美 06 | 链表(上)-如何实现LRU缓存淘汰算法
常见的缓存淘汰策略: 先进先出 FIFO 最少使用LFU(Least Frequently Used) 最近最少使用 LRU(Least Recently Used) 链表定义: 链表也是线性表的一种 ...
- 图解缓存淘汰算法二之LFU
1.概念分析 LFU(Least Frequently Used)即最近最不常用.从名字上来分析,这是一个基于访问频率的算法.与LRU不同,LRU是基于时间的,会将时间上最不常访问的数据淘汰;LFU为 ...
- 缓存淘汰算法之FIFO
前段时间去网易面试,被这个问题卡住,先做总结如下: 常用缓存淘汰算法 FIFO类:First In First Out,先进先出.判断被存储的时间,离目前最远的数据优先被淘汰. LRU类:Least ...
- 链表:如何实现LRU缓存淘汰算法?
缓存淘汰策略: FIFO:先入先出策略 LFU:最少使用策略 LRU:最近最少使用策略 链表的数据结构: 可以看到,数组需要连续的内存空间,当内存空间充足但不连续时,也会申请失败触发GC,链表则可 ...
- 《数据结构与算法之美》 <04>链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是 LRU 缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 昨天面试被问到的 缓存淘汰算法FIFO、LRU、LFU及Java实现
缓存淘汰算法 在高并发.高性能的质量要求不断提高时,我们首先会想到的就是利用缓存予以应对. 第一次请求时把计算好的结果存放在缓存中,下次遇到同样的请求时,把之前保存在缓存中的数据直接拿来使用. 但是, ...
- 链表(上):如何实现LRU缓存淘汰算法?
一.什么是链表 和数组一样,链表也是一种线性表. 从内存结构来看,链表的内存结构是不连续的内存空间,是将一组零散的内存块串联起来,从而进行数据存储的数据结构. 链表中的每一个内存块被称为节点Node. ...
随机推荐
- OC - 30.如何封装自定义布局
概述 对于经常使用的控件或类,通常将其分装为一个单独的类来供外界使用,以此达到事半功倍的效果 由于分装的类不依赖于其他的类,所以若要使用该类,可直接将该类拖进项目文件即可 在进行分装的时候,通常需要用 ...
- Java学习笔记——动态代理
所谓动态,也就是说这个东西是可变的,或者说不是一生下来就有的.提到动态就不得不说静态,静态代理,个人觉得是指一个代理在程序中是事先写好的,不能变的,就像上一篇"Java学习笔记——RMI&q ...
- PHP做支付宝即时到账需注意
注意:1按照人家的参数规则,规范填写参数列表:2商家信息填写正确:3然后提交走后注意此时告别了咱们的服务器,将在咱们服务器的订单信息提交到了支付宝服务器,然后支付宝服务器进行支付宝支付流程,当如果支付 ...
- 【转】 C语言自增自减运算符深入剖析
转自:http://bbs.csdn.net/topics/330189207 C语言的自增++,自减--运算符对于初学者来说一直都是个难题,甚至很多老手也会产生困惑,最近我在网上看到一个问题:#in ...
- DBCONN
package Ulike_servlet; //将该类保存到com.tools包中import java.sql.Connection;import java.sql.DriverManager;i ...
- 在easyui dialog的子页面内如何关闭弹窗
因项目需要在dialog中添加滚动条,所以就在div中加了iframe: <div id="applyRefundDialog" style="display:no ...
- css去除webkit内核的默认样式
做移动端的朋友应该知道,iphone的默认按钮是个很恶心的圆角,select下拉框也有默认样式无法修改. 这时候可以用到 -webkit-appearance:none //去除默认样 在按钮和sel ...
- PHP随机生成指定时间段的指定个数时间
/** * 生成某个范围内的随机时间 * @param <type> $begintime 起始时间 格式为 Y-m-d H:i:s * @param <type> $endt ...
- kafka笔记-Kafka在zookeeper中的存储结构【转】
参考链接:apache kafka系列之在zookeeper中存储结构 http://blog.csdn.net/lizhitao/article/details/23744675 1.topic注 ...
- 重构oceanbase的一个函数
我去,今天读了一下ob的源码,感觉有点乱啊!!!好吧,当作练手,我重构了一个函数 void* ObMySQLCallback::decode(easy_message_t* m) { uint32_t ...