Libsvm在matlab环境下使用指南
一、安装
http://www.csie.ntu.edu.tw/~cjlin/libsvm/matlab/。在这个地址上可以下的包含matlab接口的源程序。下载完后可以放到放到任意的盘上解压,最好建一个专门来放matlab程序的文件夹。打开matlab,在matlab的面板上找到set path选项(不同版本不一样R2010b在file菜单下),将刚下载的libsvm整个目录都添加到matlab的搜索路径里。然后将当前路径定位到libsvm/matlab目录下(在current floder(matlab界面中间上方可以设置))。如果你的电脑是64位一般不需要编译生成mex文件,因为文件已经提前编译好了。如果是32位的话,那么需要点击make.m文件运行编译生成mex文件。这一步有可能不成功,可以输入mex-setup查看选择C++编译器,如果找不到编译器,那么下载安装visual studio。成功编译完成后,在任意的matlab程序中都可以使用libsvm了。
二、使用
在使用之前,要对libsvm做一个了解,而最好的资料自然是libsvm种README文件了。README文件包含了介绍,安装,SVM返回的模型参数,以及例子等。Libsvm主要用了两个函数svmtrain,svmpredict,如果你在用的时候忘了具体的参数,可以在matlab命令提示符下输入函数名就有相关的提示。
用法:1.model = svmtrain(training_label_vector, training_instance_matrix [, 'libsvm_options']);
(1)training_label_vector, training_instance_matrix :
training_label_vector和training_instance_matrix就是要训练的标签和特征了。training_label_vector一般以列向量的形式存放的,每个元素即每行代表一个instance(一般是特征)的标签。而training_instance_matrix也类似每行代表一个instance.
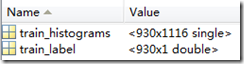
如图所示,上面变量代表有930个instance来训练,每个instance1116维,下面是对于instance的标签。
(2)Libsvm_options:
怎么选择呢?libsvm_options:重要的是-t,以及交叉验证时的-v
-s svm类型:SVM设置类型,一般默认0不用设置
0 -- C-SVC(多类分类) 1 --v-SVC(多类分类) 2 –一类SVM 3 -- e –SVR 4 -- v-SVR
-t 核函数类型:核函数设置类型(默认2)
0 –线性:u'v 1 –多项式:(r*u'v + coef0)^degree 2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(r*u'v + coef0)
-d degree:核函数中的degree设置(针对多项式核函数)(默认3)
-g r(gama):核函数中的gamma函数设置(针对多项式/rbf/sigmoid核函数)(默认1/ k)
-r coef0:核函数中的coef0设置(针对多项式/sigmoid核函数)((默认0)
-c cost:设置C-SVC,e -SVR和v-SVR的参数(损失函数)(默认1)
-n nu:设置v-SVC,一类SVM和v- SVR的参数(默认0.5)
-p p:设置e -SVR 中损失函数p的值(默认0.1)
-m cachesize:设置cache内存大小,以MB为单位(默认40)
-e eps:设置允许的终止判据(默认0.001)
-h shrinking:是否使用启发式,0或1(默认1)
-wi weight:设置第几类的参数C为weight*C(C-SVC中的C)(默认1)
-v n: n-fold交互检验模式,n为fold的个数,必须大于等于2
(3)返回的model:
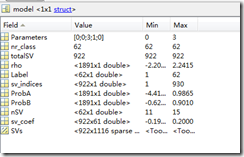
如上图 -Parameters: 参数。
-nr_class: 类的数目。
-totalSV:总的支持向量数目。
-rho: -判决函数wx+b的b。
-Label: 每个类的标签。
-ProbA: 成对的概率信息,如果b是 0则为空。
-ProbB: 成对的概率信息,如果b是 0则为空。
-nSV: 每个类的支持向量
-sv_coef:判决函数的系数
-SVs:支持向量。
如果指定了'-v',那么就实施了交叉验证,而且返回是交叉验证的正确率。
用法:
2. [predicted_label, accuracy, decision_values/prob_estimates] = svmpredict(testing_label_vector, testing_instance_matrix, model [, 'libsvm_options']);
(1)esting_label_vector, testing_instance_matrix:
类似于svmtrain
(2)libsvm_options:
-b 概率估计:默认0,1表示估计。(需要在使用时显式表现)
(3)predicted_label, accuracy, decision_values/prob_estimates:
predicted_label: SVM 预测输出向量。类似于输入的label
accuracy: 向量包括正确率,均方误差,方相关系数.
decision_values:每行是预测k(k-1)/2二类SVMs的结果
prob_estimates: 每行包括k个值代表每类中测试数据所占的概率。
三、核函数
核函数的 目的是将特征向量映射到高维空间。SVM通过在高维空间寻找最大的间距的分类超平面。
目的是将特征向量映射到高维空间。SVM通过在高维空间寻找最大的间距的分类超平面。
核函数总共有以下4种,我们要了解在什么情况下用哪一种核函数。

一般情况下,首选RBF核,它能够把样本以非线性的方式映射到高维空间,所以能够处理类标签和特征不是线性关系的情况。线性核只是RBF的一种特殊情况。
但是有些情况下RBF核并不适用,比如特征的数量特别大的时候,一般仅仅使用线性核。
四、调参-交叉验证和网格搜索
RBF核中有两个参数需要确定  。我们并不知道怎么样的是最适用于给定的问题的。最常用的方式就是交叉验证即把训练的数据分成两部分,把一部分当成知道的,另一部分是不知道的。比如在v-fold 交叉验证中,先把训练数据分成v个相同大小的子集。然后用v-1子集的训练数据训练分类器,用剩下一个子集来测试分类器。交叉验证能够解决过拟合的问题。要怎么利用交叉验证来选取最好的呢?一般是利用网格搜索,己将组成的坐标系分成一系列网格。然后用网格上点(即对于一个个)做交叉验证,取使最后交叉验证的正确率最高的参来做为最终的参数。
。我们并不知道怎么样的是最适用于给定的问题的。最常用的方式就是交叉验证即把训练的数据分成两部分,把一部分当成知道的,另一部分是不知道的。比如在v-fold 交叉验证中,先把训练数据分成v个相同大小的子集。然后用v-1子集的训练数据训练分类器,用剩下一个子集来测试分类器。交叉验证能够解决过拟合的问题。要怎么利用交叉验证来选取最好的呢?一般是利用网格搜索,己将组成的坐标系分成一系列网格。然后用网格上点(即对于一个个)做交叉验证,取使最后交叉验证的正确率最高的参来做为最终的参数。
ps:什么时候用RBF,什么时候用线性核
1.样本数量远远小于特征数时
比如训练和测试数据有二三十个而特征维数有好几千时,采用线性核是最好的,不需要映射数据。
2.样本数量和特征数都非常大时
可以利用另一工具箱LIBLINEAR,或者用线性核
3.样本数量远远大于特征数时
用非线性核是最好的了。
参考文献:http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf
Libsvm在matlab环境下使用指南的更多相关文章
- libSVM笔记之(一)在matlab环境下安装配置libSVM
本文为原创作品,转载请注明出处 欢迎关注我的博客:http://blog.csdn.net/hit2015spring和http://www.cnblogs.com/xujianqing 台湾林智仁教 ...
- Windows环境下Anaconda安装TensorFlow的避坑指南
最近群里聊天时经常会提到DL的东西,也有群友在学习mxnet,但听说坑比较多.为了赶上潮流顺便避坑,我果断选择了TensorFlow,然而谁知一上来就掉坑里了…… 我根据网上的安装教程,默认安装了最新 ...
- 写给大忙人的CentOS 7下最新版(6.2.4)ELK+Filebeat+Log4j日志集成环境搭建完整指南
现在的公司由于绝大部分项目都采用分布式架构,很早就采用ELK了,只不过最近因为额外的工作需要,仔细的研究了分布式系统中,怎么样的日志规范和架构才是合理和能够有效提高问题排查效率的.经过仔细的分析和研究 ...
- 第十八篇 Linux环境下常用软件安装和使用指南
提醒:如果之后要安装virtualenvwrapper的话,可以直接跳到安装virtualenvwrapper的方法,而不需要先安装好virtualenv 安装virtualenv和生 ...
- Libsvm的MATLAB调用和交叉验证
今天听了一个师兄的讲课,才发现我一直在科研上特别差劲,主要表现在以下几个方面,(现在提出也为了督促自己在以后的学习工作道路上能够避免这些问题) 1.做事情总是有头无尾,致使知识点不能一次搞透,每次在用 ...
- .Net环境下的缓存技术介绍 (转)
.Net环境下的缓存技术介绍 (转) 摘要:介绍缓存的基本概念和常用的缓存技术,给出了各种技术的实现机制的简单介绍和适用范围说明,以及设计缓存方案应该考虑的问题(共17页) 1 概念 ...
- .Net环境下的缓存技术介绍
.Net环境下的缓存技术介绍 摘要: 介绍缓存的基本概念和常用的缓存技术,给出了各种技术的实现机制的简单介绍和适用范围说明,以及设计缓存方案应该考虑的问题(共17页) 1 概念 1.1 ...
- [转载]SharePoint 2013测试环境安装配置指南
软件版本 Windows Server 2012 标准版 SQL Server 2012 标准版 SharePoint Server 2013 企业版 Office Web Apps 2013 备注: ...
- Win7环境下VS2010配置Cocos2d-x-2.1.4最新版本号的开发环境
写这篇博客时2D游戏引擎Cocos2d-x的最新版本号为2.1.4,记得非常久曾经使用博客园博主子龙山人的一篇博文<Cocos2d-x win7+vs2010配置图文具体解释(亲測)>成功 ...
随机推荐
- js 判断是否为数组
http://www.jb51.net/article/79939.htm Object.prototype.toString.call([1,2,3,4]) == '[object Array]'
- grub手动引导win7
grub>rootnoverify (hd0,0)--->win7系统安装盘号 grub > chainloader +1 grub > makeactive ---& ...
- python C example:encode mp3 code
#include <stdio.h> #include <stdlib.h> #include <lame.h> #define INBUFSIZE 4096 #d ...
- Vue 组件5 高级异步组件
自2.3.0起,异步组件的工厂函数也可以返回一个如下的对象. const AsyncComp = () => ({ // 需要加载的组件. 应当是一个 Promise component: im ...
- hdu1018 Big Number 斯特林公式 求N!的位数。
Big Number Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total ...
- qt 4.8.5 vs 2012编译
Download Qt 4.8.3 source code from http://qt-project.org/downloads Go to mkspecs\win32-msvc2010. Ope ...
- IE6鼠标悬停Bug
当鼠标放置于某个文字链接之上,文字或文字背景改变为其他颜色或样式的效果是我们最经常见到的鼠标悬停效果.在CSS中,这个效果靠伪元素:hover来实现,只不过在文字链接中:hover被应用在了锚点元素& ...
- ORA-06519: 检测到活动的自治事务处理,已经回退
写了一个函数,由于在定义时加入了 create or replace function F_计算结果(In_参数 varchar2) return number is --使用自治事务PRAGMA A ...
- Hibernate一对多映射列表实例(使用xml文件)
如果持久化类具有包含实体引用的列表(List)对象,则需要使用一对多关联来映射列表元素. 在这里,我们使用论坛应用场景,在论坛中一个问题有多个答案. 在这种情况下,一个问题可以有多个答案,每个答案可能 ...
- Cobbler简介
Cobbler is a Linux provisioning server that facilitates and automates the network-based system insta ...