论文阅读笔记(二十)【AAAI2019】:Spatial and Temporal Mutual Promotion for Video-Based Person Re-Identification
Introduction
(1)Motivation:
作者考虑到空间上的噪声可以通过时间信息进行弥补,其原因为:不同帧的相同区域可能是相似信息,当一帧的某个区域存在噪声或者缺失,可以用其它帧的相同区域进行弥补。
(2)Contribution:
① 不直接使用帧提取的特征信息,而是提出一个改进循环单元(refining recurrent unit,RRU),来修复缺失或噪声;
② 介绍一种时空线索集成模块(spatial-temporal clues integration module,STIM),来提取时空信息;
③ 提出多层训练目标来提高RRU和STIM的能力。
Method
(1)框架:
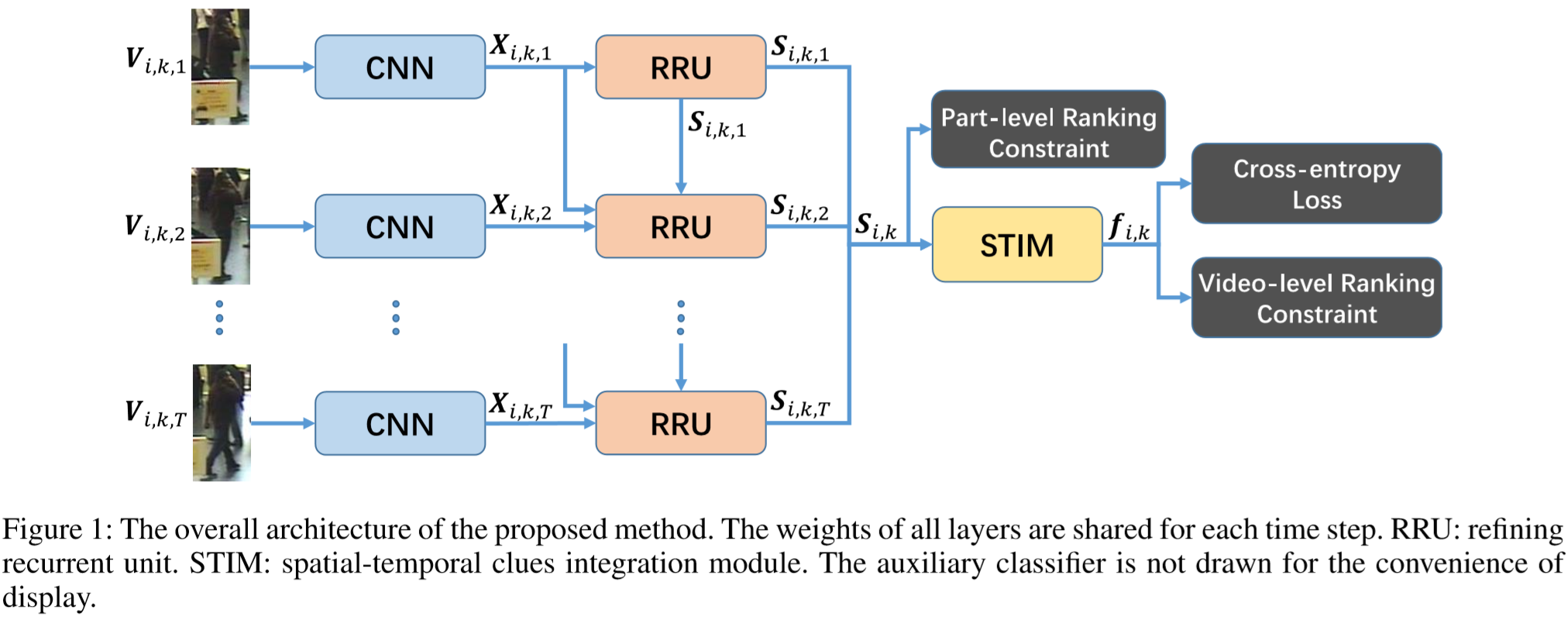
定义: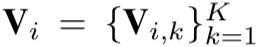 表示行人 i 的 K 个视频序列,采用 Inception-v3 (2016年Szegedy提出)作为特征提取模块的主干网络,通过CNN提取出的特征为
表示行人 i 的 K 个视频序列,采用 Inception-v3 (2016年Szegedy提出)作为特征提取模块的主干网络,通过CNN提取出的特征为 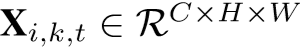 ,再传入RRU模块得到改进特征 Si,k,最后传入 STIM模块僧改成最终的视频级特征表示
,再传入RRU模块得到改进特征 Si,k,最后传入 STIM模块僧改成最终的视频级特征表示 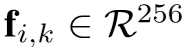 。
。
(2)改进循环单元(RRU):
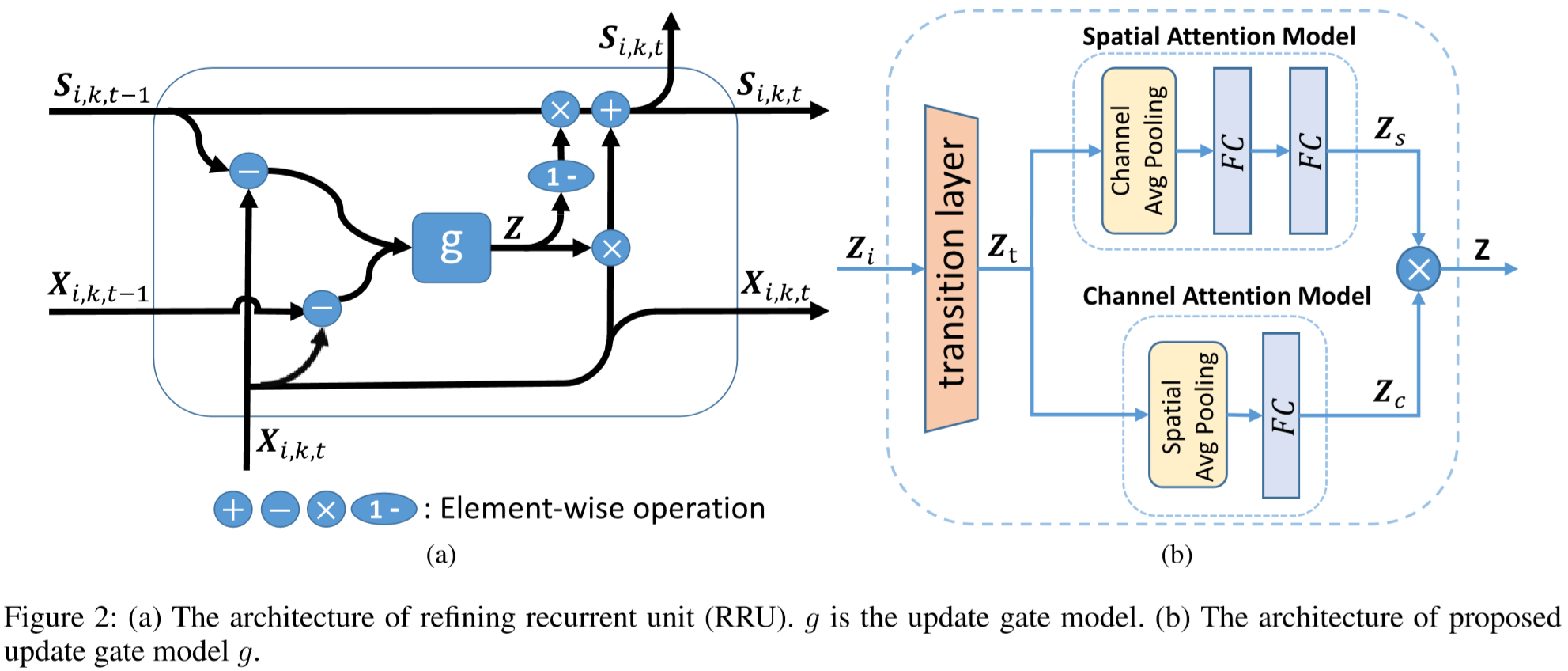
使用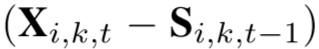 作为 g 模块的输入,来衡量两帧的样貌差异(我的理解:特征S相当于特征X弥补上缺失),使用
作为 g 模块的输入,来衡量两帧的样貌差异(我的理解:特征S相当于特征X弥补上缺失),使用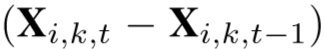 作为 g 的另一个输入,来衡量动作捕捉。
作为 g 的另一个输入,来衡量动作捕捉。
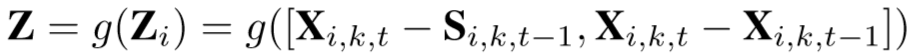 ,其中
,其中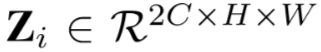 。
。
首先通过过渡层(transition layer),其包含256个filter 1*1的卷积层,得到  ;
;
上层为空间感知模块,首先使用通道交叉平均池化获得每个空间位置的全局感知,再通过两个全连接层,得到: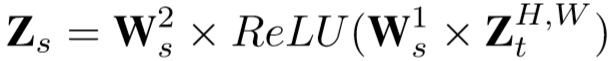 ,
,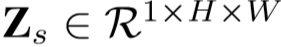 ,
,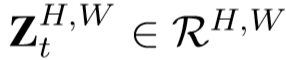 ;
;
下层为通道感知模块,首先使用空间平均池化来获得每个通道的全局感知,再通过一个全连接层,得到: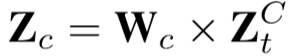 ,
,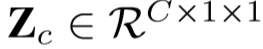 ,
,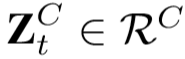 ;
;
将两者进行乘法操作,再用sigmoid约束至[0, 1]之间,即: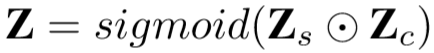 ,
,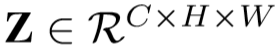 。
。
最终特征输出: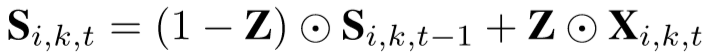 ,
,
Z 的每一个位置表示该位置特征的可信值。其值高,则表示该位置的特征有较高的质量,应当保留;其值低,则表示该位置应当被前帧特征所替补。(两帧差别小的地方直接用上一帧,差别大的地方用当前帧)
(3)时空线索集成模块(STIM):
STIM 包含了两个3D卷积模块和一个平均池化层,每个3D卷积模块包含了三个操作:3D卷积层(包含256个filter)+ 3D BN层 + ReLU层。第一个3D卷积模块的kernel size为 1*1*1,用来降低特征维度;第二个3D卷积模块的kernel size为3*3*3,用来捕捉行人的肢体移动,并输出特征: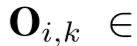
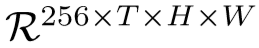 。最后通过时空平均池化,得到最终特征表述:
。最后通过时空平均池化,得到最终特征表述: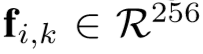 ,即:
,即:

(3)多层训练目标:
训练目标函数: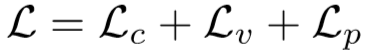
① 第一项为两个交叉熵损失,详情参照Szegedy提出的Inception-v3模型,该模型包含identity classifier 和 auxiliary classifier 两个分类器,作者对identify classifier的全连接层进行了修改,采用了Zhong提出的classifier模块,包含了512结点的全连接层、BN、ReLU、Dropout、FC、Softmax层。
② 第二项为视频级约束,采用Hermans等人提出的batch hard三元组损失,具体为:
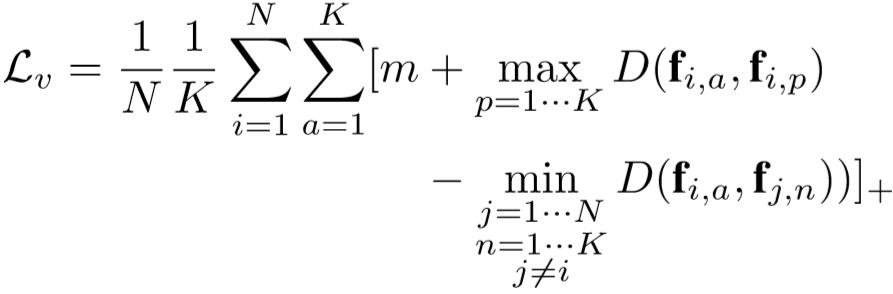
③ 第三项为区域级约束,将特征S划分成行,获得行级特征(上述特征f忽略了不同区域的空间变化 ):

其中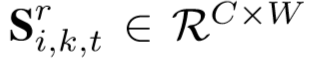 为
为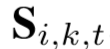 的第 r 行,得到的区域特征向量为:
的第 r 行,得到的区域特征向量为: ,
,
定义如下损失函数:
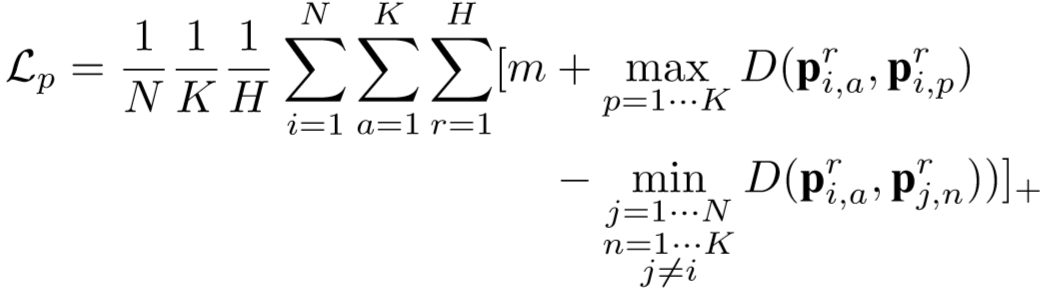
Experiments
(1)实验设置:
① 数据集:iLIDS-VID、PRID-2011、MARS;
② 参数设置:帧大小 299*299,N = 10,K = 2,T = 8,m = 0.4,dropout rate = 0.5,learning rate = 0.01,weight decay = 5 * 10^-4,momentum = 0.9
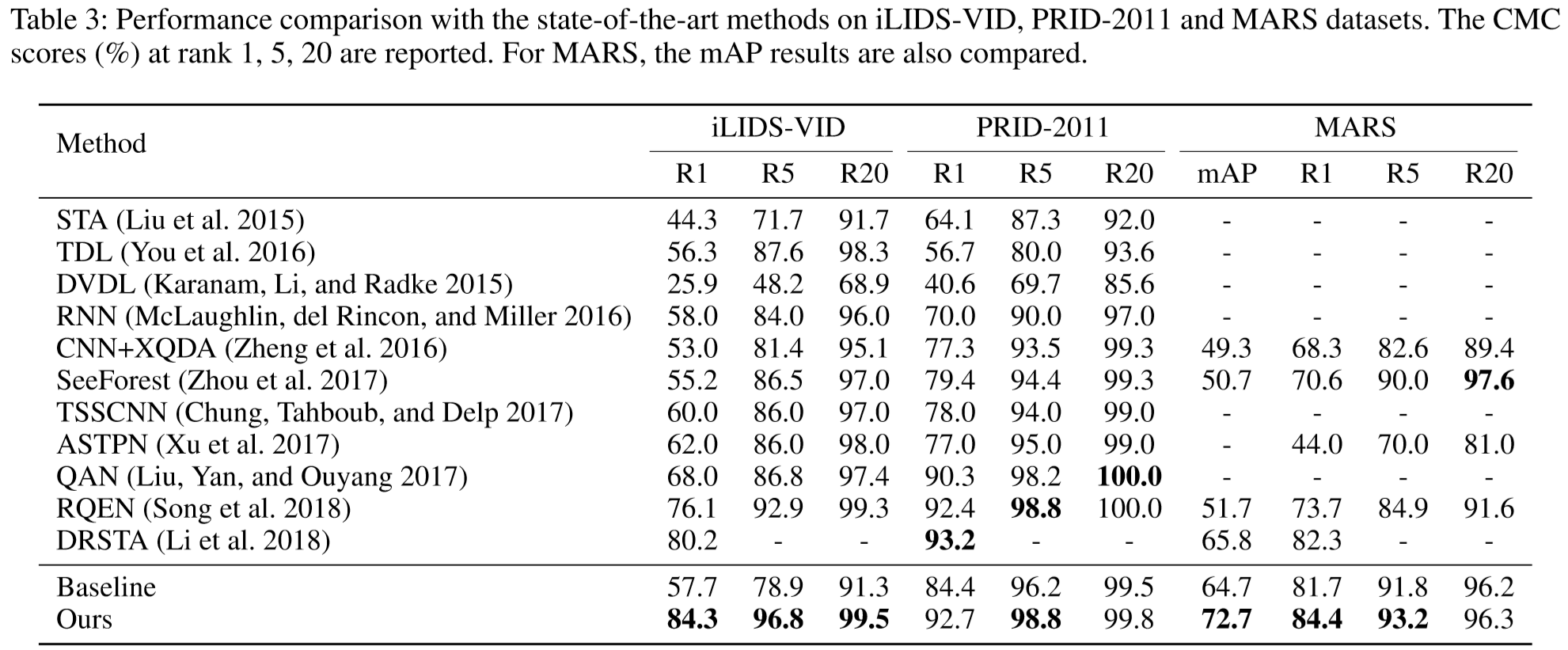
(2)实验结果:


论文阅读笔记(二十)【AAAI2019】:Spatial and Temporal Mutual Promotion for Video-Based Person Re-Identification的更多相关文章
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
- 论文阅读笔记二十九:SSD: Single Shot MultiBox Detector(ECCV2016)
论文源址:https://arxiv.org/abs/1512.02325 tensorflow代码:https://github.com/balancap/SSD-Tensorflow 摘要 SSD ...
- 论文阅读笔记二十八:You Only Look Once: Unified,Real-Time Object Detection(YOLO v1 CVPR2015)
论文源址:https://arxiv.org/abs/1506.02640 tensorflow代码:https://github.com/nilboy/tensorflow-yolo 摘要 该文提出 ...
- 论文阅读笔记二十六:Fast R-CNN (ICCV2015)
论文源址:https://arxiv.org/abs/1504.08083 参考博客:https://blog.csdn.net/shenxiaolu1984/article/details/5103 ...
- 论文阅读笔记二十二:End-to-End Instance Segmentation with Recurrent Attention(CVPR2017)
论文源址:https://arxiv.org/abs/1605.09410 tensorflow 代码:https://github.com/renmengye/rec-attend-public 摘 ...
- 论文阅读笔记二十:LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation(CVPR2017)
源文网址:https://arxiv.org/abs/1707.03718 tensorflow代码:https://github.com/luofan18/linknet-tensorflow 基于 ...
- 论文阅读笔记(十)【CVPR2016】:Recurrent Convolutional Network for Video-based Person Re-Identification
Introduction 该文章首次采用深度学习方法来解决基于视频的行人重识别,创新点:提出了一个新的循环神经网络架构(recurrent DNN architecture),通过使用Siamese网 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- 论文阅读笔记(十二)【CVPR2018】:Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning
Introduction (1)Motivation: 大量标记数据成本过高,采用半监督的方式只标注一部分的行人,且采用单样本学习,每个行人只标注一个数据. (2)Method: 对没有标记的数据生成 ...
随机推荐
- winform应用如何发布(不用打包)、并提醒用户自动更新
环境:VS2019 community C# winform 应用程序 设计应用程序界面 编写对应代码 使用PS设计程序标识ICON F4打开属性: 设置ICON 设置背景 打开项目属性 打开“发 ...
- Go语言实现:【剑指offer】二叉搜索树的第k个的结点
该题目来源于牛客网<剑指offer>专题. 给定一棵二叉搜索树,请找出其中的第k小的结点.例如,(5,3,7,2,4,6,8) 中,按结点数值大小顺序第三小结点的值为4. Go语言实现: ...
- 文件传输协议-FTP
一.FTP概述 FTP(File Transfer Protocol 文件传输协议)C/S结构的应用层协议.由服务端和客户端两个部分共同实现文件传输功能 FTP服务器普遍部署于内网中,具有容易部署.方 ...
- [Effective Java 读书笔记] 第二章 创建和销毁对象 第五条
第五条 避免创建不必要的对象 书中一开始举例: String s = new String("stringette"); // don't do this //应该使用下面,只会创 ...
- 论文翻译:2018_Artificial Bandwidth Extension with Memory Inclusion using Semi-supervised Stacked Auto-encoders
论文地址:使用半监督堆栈式自动编码器实现包含记忆的人工带宽扩展 作者:Pramod Bachhav, Massimiliano Todisco and Nicholas Evans 博客作者:凌逆战 ...
- python爬虫实战:基础爬虫(使用BeautifulSoup4等)
以前学习写爬虫程序时候,我没有系统地学习爬虫最基本的模块框架,只是实现自己的目标而写出来的,最近学习基础的爬虫,但含有完整的结构,大型爬虫含有的基础模块,此项目也有,“麻雀虽小,五脏俱全”,只是没有考 ...
- python随用随学20200220-异步IO
啥是异步IO 众所周知,CPU速度太快,磁盘,网络等IO跟不上. 而程序一旦遇到IO的时候,就需要等IO完成才能进行才能进行下一步的操作. 严重拖累了程序速度. 因为一个IO操作就阻塞了当前线程,导致 ...
- HA: Dhanush Vulnhub Walkthrough
靶机下载链接: https://www.vulnhub.com/entry/ha-dhanush,396/ 主机扫描: 主机端口扫描: HTTP目录爬取 使用dirb dirsearch 爬取均未发现 ...
- djinn:1 Vulnhub Walkthrough
靶机下载链接: https://download.vulnhub.com/djinn/djinn.ova 主机端口扫描: FTP发现一些文件提示 1337端口是一个游戏,去看下 哈哈有点难,暂时放弃, ...
- docker jenkins 安装
1:官方教程 https://jenkins.io/zh/doc/book/installing/ 2:拉取jenkins镜像 docker pull jenkinsci/blueocean 3:输入 ...