Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的。从bottom得到一个blob数据输入,运算后,从top输入一个blob数据。在运算过程中,没有改变数据的大小,即输入和输出的数据大小是相等的。
输入:n*c*h*w
输出:n*c*h*w
常用的激活函数有sigmoid, tanh,relu等,下面分别介绍。
1、Sigmoid
对每个输入数据,利用sigmoid函数执行操作。这种层设置比较简单,没有额外的参数。
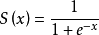
层类型:Sigmoid
示例:
layer {
name: "encode1neuron"
bottom: "encode1"
top: "encode1neuron"
type: "Sigmoid"
}
2、ReLU / Rectified-Linear and Leaky-ReLU
ReLU是目前使用最多的激活函数,主要因为其收敛更快,并且能保持同样效果。
标准的ReLU函数为max(x, 0),当x>0时,输出x; 当x<=0时,输出0
f(x)=max(x,0)
层类型:ReLU
可选参数:
negative_slope:默认为0. 对标准的ReLU函数进行变化,如果设置了这个值,那么数据为负数时,就不再设置为0,而是用原始数据乘以negative_slope
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
RELU层支持in-place计算,这意味着bottom的输出和输入相同以避免内存的消耗。
3、TanH / Hyperbolic Tangent
利用双曲正切函数对数据进行变换。
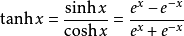
层类型:TanH
layer {
name: "layer"
bottom: "in"
top: "out"
type: "TanH"
}
4、Absolute Value
求每个输入数据的绝对值。
f(x)=Abs(x)
层类型:AbsVal
layer {
name: "layer"
bottom: "in"
top: "out"
type: "AbsVal"
}
5、Power
对每个输入数据进行幂运算
f(x)= (shift + scale * x) ^ power
层类型:Power
可选参数:
power: 默认为1
scale: 默认为1
shift: 默认为0
layer {
name: "layer"
bottom: "in"
top: "out"
type: "Power"
power_param {
power: 2
scale: 1
shift: 0
}
}
6、BNLL
binomial normal log likelihood的简称
f(x)=log(1 + exp(x))
层类型:BNLL
layer {
name: "layer"
bottom: "in"
top: "out"
type: “BNLL”
}
Caffe学习系列(4):激活层(Activiation Layers)及参数的更多相关文章
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
- Caffe学习系列(21):caffe图形化操作工具digits的安装与运行
经过前面一系列的学习,我们基本上学会了如何在linux下运行caffe程序,也学会了如何用python接口进行数据及参数的可视化. 如果还没有学会的,请自行细细阅读: caffe学习系列:http:/ ...
随机推荐
- 关于OC中直接打印结构体,点(CGRect,CGSize,CGPoint,UIOffset)等数据类型
关于OC直接打印结构体,点(CGRect,CGSize,CGPoint,UIOffset)等数据类型,我们完全可以把其转换为OC对象来进项打印调试,而不必对结构体中的成员变量进行打印.就好比我们可以使 ...
- iOS-UICollectionView的简单使用(原创)
前言 UICollectionView是一种新的数据展示方式,简单来说可以把他理解成多列的UITableView(请一定注意这是UICollectionView的最最简单的形式).如果你用过iBook ...
- Qt安装后配置环境变量(Mac)
打开终端需要打开配置文件(注意这里不是bash_profile而是 .bash_profile,我开始少了".") 如果bash_profile文件不存在,就会自动创建,然后需要输 ...
- android 之 桌面的小控件AppWidget
AppWidget是创建的桌面窗口小控件,在这个小控件上允许我们进行一些操作(这个视自己的需要而定).作为菜鸟,我在这里将介绍一下AppWeight的简单使用. 1.在介绍AppWidget之前,我们 ...
- C++中static用法总结
1用于局部变量 C++中局部变量有三种: (1)auto:此关键词常常省略.auto type a 常常简写为type a. 如: int a=auto int a 存储在内存的栈中,只在此局部区域有 ...
- Effective Java 07 Avoid finallizers
NOTE Never do anything time-critical in a finalizer. Never depend on a finalizer to update critical ...
- 【故障处理】CRS-1153错误处理
[故障处理]CRS-1153错误处理 1 CRS-1153: There was an error setting Oracle Clusterware to rolling patch mode. ...
- lucene索引
一.lucene索引 1.文档层次结构 索引(Index):一个索引放在一个文件夹中: 段(Segment):一个索引中可以有很多段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一 ...
- Linux dsh
一.简介 目前在企业网络中越来越多的出现Linux服务器,而如何方便高效的管理大量的Linux服务器是系统管理员非常关心的一个问题,而dsh正是一个通过命令行有效地管理大量Linux的工具. 二. ...
- TCP连接与关闭
1.建立连接协议(三次握手) (1)客户端发送一个带SYN标志的TCP报文到服务器.这是三次握手过程中的报文1. (2) 服务器端回应客户端的,这是三次握手中的第2个报文,这个报文同时带ACK标志和S ...