Kaggle之泰坦尼克号幸存预测估计
上次已经讲了怎么下载数据,这次就不说废话了,直接开始。首先导入相应的模块,然后检视一下数据情况。对数据有一个大致的了解之后,开始进行下一步操作。

一、分析数据
1、Survived 的情况
train_data['Survived'].value_counts()

2、Pclass 和 Survived 之间的关系
train_data.groupby('Pclass')['Survived'].mean()

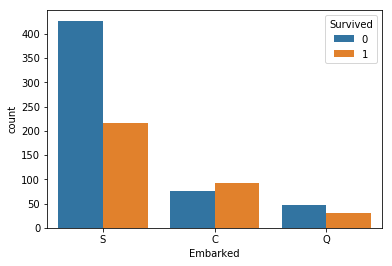
3、Embarked 和 Survived 之间的关系
train_data.groupby('Embarked')['Survived'].value_counts()
sns.countplot('Embarked',hue='Survived',data=train_data)
二、特征处理
先将 label 提取出来,然后将 train 和 test 合并起来一起处理。
y_train = train_data.pop('Survived').astype(str).values
data = pd.concat((train_data, test_data), axis=0)
1、对 numerical 数据进行处理
(1)SibSp/Parch (兄弟姐妹配偶数 / 父母孩子数)
由于这两个属性都和 Survived 没有很大的影响,将这两个属性的值相加,表示为家属个数。
data['FamilyNum'] = data['SibSp'] + data['Parch']
(2)Fare (费用)
它有一个缺失值,需要将其补充。(这里是参考别人的,大神总能发现一些潜在的信息:票价和 Pclass 和 Embarked 有关) 因此,先看一下他们之间的关系以及缺失值的情况。
train_data.groupby(by=["Pclass","Embarked"]).Fare.mean()

缺失值 Pclass = 3, Embarked = S,因此我们将其置为14.644083.
data["Fare"].fillna(14.644083,inplace=True)
还有 Age 的缺失值也需要处理,我是直接将其设置为平均值。
2、对 categorical 数据进行处理
(1)对 Cabin 进行处理
Cabin虽然有很多空值,但他的值的开头都是字母,按我自己的理解应该是对应船舱的位置,所以取首字母。考虑到船舱位置对救生是有一定影响的,虽然有很多缺失值,但还是把它保留下来,而且由于 T 开头的只有一条数据,因此将它设置成数量较小的 G。
data['Cabin'] = data['Cabin'].str[0]
data['Cabin'][data['Cabin']=='T'] = 'G'
(2)对 Ticket 进行处理
将 Ticket 的头部取出来当成新列。
data['Ticket_Letter'] = data['Ticket'].str.split().str[0]
data['Ticket_Letter'] = data['Ticket_Letter'].apply(lambda x:np.nan if x.isnumeric() else x)
data.drop('Ticket',inplace=True,axis=1)
(3)对 Name 进行处理
名字这个东西,虽然它里面的称呼可能包含了一些身份信息,但我还是打算把这一列给删掉...
data.drop('Name',inplace=True,axis=1)
(4)统一将 categorical 数据进行 One-Hot
One-Hot 大致的意思在之前的文章讲过了,这里也不再赘述。
data['Pclass'] = data['Pclass'].astype(str)
data['FamilyNum'] = data['FamilyNum'].astype(str)
dummied_data = pd.get_dummies(data)
(5)数据处理完毕,将训练集和测试集分开
X_train = dummied_data.loc[train_data.index].values
X_test = dummied_data.loc[test_data.index].values
三、构建模型
这里用到了 sklearn.model_selection 的 GridSearchCV,我主要用它来调参以及评定 score。
1、XGBoost
xgbc = XGBClassifier()
params = {'n_estimators': [100,110,120,130,140],
'max_depth':[5,6,7,8,9]}
clf = GridSearchCV(xgbc, params, cv=5, n_jobs=-1)
clf.fit(X_train, y_train)
print(clf.best_params_)
print(clf.best_score_)
{'max_depth': 6, 'n_estimators': 130}
0.835016835016835
2、Random Forest
rf = RandomForestClassifier()
params = {
'n_estimators': [100,110,120,130,140,150],
'max_depth': [5,6,7,8,9,10],
}
clf = GridSearchCV(rf, params, cv=5, n_jobs=-1)
clf.fit(X_train, y_train)
print(clf.best_params_)
print(clf.best_score_)
{'max_depth': 8, 'n_estimators': 110}
0.8294051627384961
四、模型融合
from sklearn.ensemble import VotingClassifier
xgbc = XGBClassifier(n_estimators=130, max_depth=6)
rf = RandomForestClassifier(n_estimators=110, max_depth=8) vc = VotingClassifier(estimators=[('rf', rf),('xgb',xgbc)], voting='hard')
vc.fit(X_train, y_train)
准备就绪,预测并保存模型与结果
y_test = vc.predict(X_test) # 保存模型
from sklearn.externals import joblib
joblib.dump(vc, 'vc.pkl') submit = pd.DataFrame(data= {'PassengerId' : test_data.index, 'Survived': y_test})
submit.to_csv('./input/submit.csv', index=False)
最后提交即可,提交的方式也在上一篇提到过了。Over~ 项目地址:Titanic
Kaggle之泰坦尼克号幸存预测估计的更多相关文章
- Kaggle入门——泰坦尼克号生还者预测
前言 这个是Kaggle比赛中泰坦尼克号生存率的分析.强烈建议在做这个比赛的时候,再看一遍电源<泰坦尼克号>,可能会给你一些启发,比如妇女儿童先上船等.所以是否获救其实并非随机,而是基于一 ...
- 数据挖掘竞赛kaggle初战——泰坦尼克号生还预测
1.题目 这道题目的地址在https://www.kaggle.com/c/titanic,题目要求大致是给出一部分泰坦尼克号乘船人员的信息与最后生还情况,利用这些数据,使用机器学习的算法,来分析预测 ...
- Titanic幸存预测分析(Kaggle)
分享一篇kaggle入门级案例,泰坦尼克号幸存遇难分析. 参考文章: 技术世界,原文链接 http://www.jasongj.com/ml/classification/ 案例分析内容: 通过训练集 ...
- Survival on the Titanic (泰坦尼克号生存预测)
>> Score 最近用随机森林玩了 Kaggle 的泰坦尼克号项目,顺便记录一下. Kaggle - Titanic: Machine Learning from Disaster On ...
- kaggle之泰坦尼克号乘客死亡预测
目录 前言 相关性分析 数据 数据特点 相关性分析 数据预处理 预测模型 Logistic回归训练模型 模型优化 前言 一般接触kaggle的入门题,已知部分乘客的年龄性别船舱等信息,预测其存活情况, ...
- Kaggle竞赛 —— 泰坦尼克号(Titanic)
完整代码见kaggle kernel 或 NbViewer 比赛页面:https://www.kaggle.com/c/titanic Titanic大概是kaggle上最受欢迎的项目了,有7000多 ...
- Kaggle案例泰坦尼克号问题
泰坦里克号预测生还人口问题 泰坦尼克号问题背景 - 就是那个大家都熟悉的『Jack and Rose』的故事,豪华游艇倒了,大家都惊恐逃生,可是救生艇#### 的数量有限,无法人人都有,副船长发话了l ...
- kaggle入门--泰坦尼克号之灾(手把手教你)
作者:炼己者 具体操作请看这里-- https://www.jianshu.com/p/e79a8c41cb1a 大家也可以看PDF版,用jupyter notebook写的,视觉效果上感觉会更棒 链 ...
- 【Kaggle】泰坦尼克号
引言 Kaggle官方网站 这是泰坦尼克号事件的基本介绍: 我们需要做的就是通过给出的数据集,通过对特征值的分析以及运用机器学习模型,分析什么样的人最可能存活,并给出对测试集合的预测. 对于Kaggl ...
随机推荐
- akka框架——异步非阻塞高并发处理框架
akka actor, akka cluster akka是一系列框架,包括akka-actor, akka-remote, akka-cluster, akka-stream等,分别具有高并发处理模 ...
- Maya API编程快速入门
一.Maya API编程简介 Autodesk® Maya® is an open product. This means that anyone outside of Autodesk can ch ...
- vue货币格式化组件、局部过滤功能以及全局过滤功能
一.在这里介绍一个vue的时间格式化插件: moment 使用方法: .npm install moment --save. 2 定义时间格式化全局过滤器 在main.js中 导入组件 import ...
- jdk?jre?
很多人都搞不懂什么是jdk,什么是jre,只知道电脑安装了这两个就能开发和运行java程序,这里我简单讲讲什么是jdk,什么是jre. jdk,即Java Development Kit,故名思意就是 ...
- markdown让文字居中和带颜色
markdown让文字居中和带颜色 markdown让文字居中和带颜色1.说明2. 文字的居中3.文字的字体及颜色3.1 字体更换3.2 大小更换3.3 颜色替换4 总结 1.说明 本文主要叙述如何写 ...
- 【剑指Offer】4、重建二叉树
题目描述: 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树.假设输入的前序遍历和中序遍历的结果中都不含重复的数字.例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列 ...
- 分别用for循环,while do-while以及递归方法实现n的阶乘!
分别用for循环,while do-while以及递归方法实现n的阶乘! 源码: package book;import java.util.Scanner;public class Access { ...
- swift-导航栏添加自定义返回按钮
//1.添加返回按钮 func addBackBtn(){ let leftBtn:UIBarButtonItem=UIBarButtonItem(title: "返回", sty ...
- svg文件报错
错误:The content of element type "font-face" is incomplete, it must match "((font-face- ...
- Hexo系列(五) 撰写文章
在利用 Hexo 框架搭建一个属于我们自己的博客网站后,下面我们就来谈谈怎样在网站上书写我们的第一篇博客吧 一.创建文章 在站点文件夹中打开 git bash,输入如下命令创建文章,其中 title ...