小爬新浪新闻AFCCL
1.任务目标:
爬取新浪新闻AFCCL的文章:文章标题、时间、来源、内容、评论数等信息。
2.目标网页:
http://sports.sina.com.cn/z/AFCCL/
3.网页分析
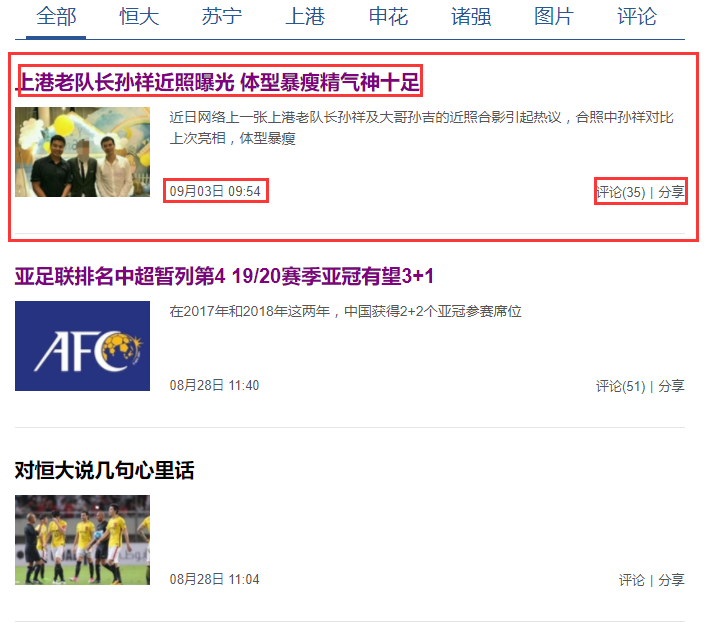

4.源代码:
#!/usr/bin/env/python
# coding:utf-8
import sys
import requests
from bs4 import BeautifulSoup
import json
import re
if __name__ == '__main__':
url = 'http://sports.sina.com.cn/z/AFCCL/'
res = requests.get(url)
html_doc = res.content soup = BeautifulSoup(html_doc, 'html.parser') a_list=[]
#爬取新闻时间,标题,链接
for news in soup.select('.news-item'):
if(len(news.select('h2'))>0):
h2=news.select('h2')[0].text
a=news.select('a')[0]['href']
time=news.select('.time')[0].text
# print(time,h2,a)
a_list.append(a)
#爬取内文资料
for i in range(len(a_list)):
url=a_list[i]
res = requests.get(url)
html_doc = res.content
soup = BeautifulSoup(html_doc, 'html.parser')
#获取文章标题、时间、来源、内容,评论数
title=soup.select('#j_title')
if title:
title = soup.select('#j_title')[0].text.strip()
time = soup.select('.article-a__time')[0].text.strip()
source = soup.select('.article-a__source')[0].text.strip()
content = soup.select('.article-a__content')[0].text.strip()
#动态生成获取评论的Ajax url eg:'http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=ty&newsid=comos-fykiuaz1429964&group=&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=20&jsvar=loader_1504416797470_64712661'
# print(url)
pattern_id=r'(fyk\w*).s?html'
# print(re.search(pattern_id,url).group(1))
id=re.search(pattern_id,url).group(1)
url='http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=ty&newsid=comos-'+id+'&group=&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=20'
comments = requests.get(url)
jd=json.loads(comments.text.strip('var data='))
commentCount = jd['result']['count']['total'] # 评论数
print(time,title,source,content)
print(commentCount)
5.运行结果:

6.小结:
对于一次请求获得的资源爬取是比较顺利的,对于异步请求的资源需要查看检查器,寻找资源所在请求,正对性的爬取。
eg:“评论及评论数”的爬取。
小爬新浪新闻AFCCL的更多相关文章
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
- python3爬虫-爬取新浪新闻首页所有新闻标题
准备工作:安装requests和BeautifulSoup4.打开cmd,输入如下命令 pip install requests pip install BeautifulSoup4 打开我们要爬取的 ...
- 门户级UGC系统的技术进化路线——新浪新闻评论系统的架构演进和经验总结(转)
add by zhj:先收藏了 摘要:评论系统是所有门户网站的核心标准服务组件之一.本文作者曾负责新浪网评论系统多年,这套系统不仅服务于门户新闻业务,还包括调查.投票等产品,经历了从单机到多机再到集群 ...
- Python_网络爬虫(新浪新闻抓取)
爬取前的准备: BeautifulSoup的导入:pip install BeautifulSoup4 requests的导入:pip install requests 下载jupyter noteb ...
- Lance老师UI系列教程第八课->新浪新闻SlidingMenu界面的实现
UI系列教程第八课:Lance老师UI系列教程第八课->新浪新闻SlidingMenu界面的实现 今天蓝老师要讲的是关于新浪新闻侧滑界面的实现.先看看原图: 如图所示,这种侧滑效果以另一种方式替 ...
- Python爬虫:新浪新闻详情页的数据抓取(函数版)
上一篇文章<Python爬虫:抓取新浪新闻数据>详细解说了如何抓取新浪新闻详情页的相关数据,但代码的构建不利于后续扩展,每次抓取新的详情页时都需要重新写一遍,因此,我们需要将其整理成函数, ...
- Android仿新浪新闻SlidingMenu界面的实现 .
先看看原图: 如图所示,这种侧滑效果以另一种方式替代了原先tab导航的那种用户体验方式 给人耳目一新的感觉,现已被广大知名应用所效仿,如新浪新闻,网易新闻,人人网等 那么这种效果该如何实现呢?那就需要 ...
- 今天写了一个简单的新浪新闻RSS操作类库
今天,有位群友问我如何获新浪新闻列表相关问题,我想,用正则表达式网页中取显然既复杂又不一定准确,现在许多大型网站都有RSS集合,所以我就跟他说用RSS应该好办一些. 一年前我写过一个RSS阅读器,不过 ...
- 采集新浪新闻php插件
今天没事,就分享一个采集新浪新闻PHP插件接口,可用于火车头采集,比较简单,大家可以研究! 新浪新闻实时动态列表为:https://news.sina.com.cn/roll/?qq-pf-to=pc ...
随机推荐
- 【转载】Android 开发 命名规范
原文地址:http://www.cnblogs.com/ycxyyzw/p/4103284.html 标识符命名法标识符命名法最要有四种: 1 驼峰(Camel)命名法:又称小驼峰命名法,除首单词外, ...
- Java 9 揭秘(14. HTTP/2 Client API)
Tips 做一个终身学习的人. 在此章中,主要介绍以下内容: 什么是HTTP/2 Client API 如何创建HTTP客户端 如何使HTTP请求 如何接收HTTP响应 如何创建WebSocket的e ...
- Echarts关系图-力引导布局
需要做一个树形图,可以查看各个人员的关系. 可伸缩的力引导图-失败 刚开始,打算做一个可展开和伸缩的,搜索时候发现CSDN有一篇美美哒程序媛写的Echarts Force力导向图实现节点可折叠. 这里 ...
- 单双引号的区别,defined容易疏忽的小地方
单双引号的区别(面试题) 1.双引号可以解析变量,单引号不行 2.双引号解析转义字符,单引号不解析转义字符.但是单引号能解析 ...
- 原生JS元素怎么取消事件
关于原生JS元素怎么取消事件,有3种方式 常规方法:removeEventListener 案例: <body> <div id="myDIV"> div ...
- UE4 C++BeginPlay And BlueprintBeginPlay
今天遇到了一个诡异的问题,经过几个小时的煎熬终于找到了原因.mmmp 如果有一个类AActorChild,这个AActorChild继承自AActor,再有一个蓝图类BPAActorChild. 蓝图 ...
- 《开发技巧》WEB APP开发调试技巧
前言 随着html5和nodejs的兴起.web APP越来越火,一套代码可以多平台使用.减少了很大的开发成本.很多APP中也集成了很多的html5页面,增强很高的应用体验.所以移动端页面也事关重要! ...
- nginx实现wap移动端和PC端业务分离
随着移动互联网时代的来临,很多WEB网站都已经推出了基于手机,Ipad等移动客户端的页面访问,这里介绍一下如何利用用户UA实现用户不同终端下的用户访问: $http_user_agent 为ngin ...
- git远程仓库之从远程库克隆
上次我们讲了先有本地库,后有远程库的时候,如何关联远程库. 现在,假设我们从零开发,那么最好的方式是先创建远程库,然后,从远程库克隆. 首先,登陆GitHub,创建一个新的仓库,名字叫gitskill ...
- NYOJ 128 前缀表达式的计算
前缀式计算 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描述 先说明一下什么是中缀式: 如2+(3+4)*5这种我们最常见的式子就是中缀式. 而把中缀式按运算顺序加上括 ...