scrapy框架第二天
1.scrapy数据分析
2.scrapy持久化存储
3.全站数据爬取
4.请求传参 + 五大核心组件
- 创建scrapy工程 scrapy startproject ProName - 切换到工程目录下 cd ProName - 创建spider文件夹 scrapy genspider SpiderName www.xxx.com
-settings里面的一些设置
- LOG_LEVEL = 'ERROR'
- USER_AGENT='JHJAJHHJKAFHJFHJ'
- ROBOTSTXT_OBEY = False
-运行spider scrapy crawl SpiderName
- scrapy的数据解析
- 在scrapy中使用xpath解析标签中的文本内容或者标签属性的话,最终获取的是一个Selector的对象,且我们需要的字符串数据全部被封装在了该对象中
- 如果可以确定xpath返回的列表只有一个列表元素则使用extract_first(),否则使用extract()
- scrapy的持久化存储
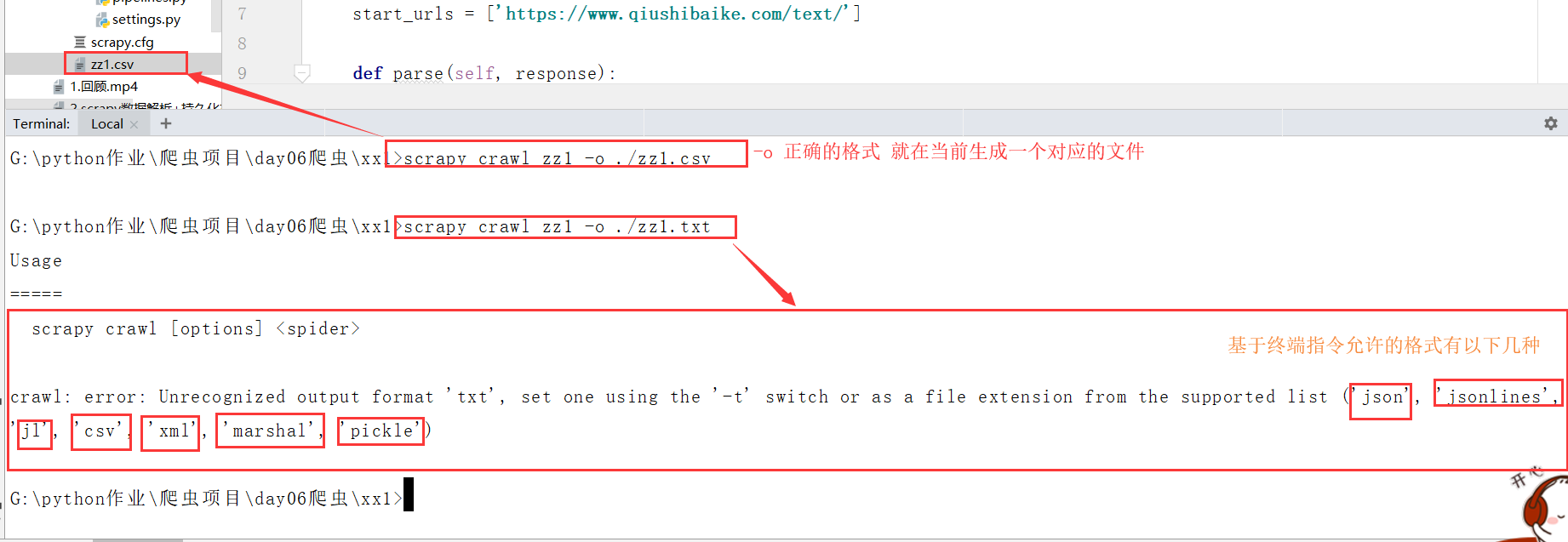
- 基于终端指令:
- 可以将parse方法的返回值对应的数据进行本地磁盘文件的持久化存储
- scrapy crawl SpiderName -o filePath
- 优点:便捷
- 缺点:局限性较强(数据不可以存储到数据库,数据存储文件的后缀有要求)
- 基于管道:
-编码流程:
- 1.数据解析
- 2.在item类中进行相关属性的封装
- 3.实例化一个item类型的对象
- 4.将解析的数据存储封装到item类型的对象中
- 5.将item提交给管道
- 6.在配置文件中开启管道
- 注意事项:
- 爬虫文件提交的item只会传递给第一个被执行的管道类
- 在管道类的process_item方法中的return item,是将item传递给下一个即将被执行的管道类
- 习惯:每一个process_item中都需要编写return item
爬取糗百数据一:
1.存放在start_urls中的url会被scrapy自动的进行请求发送
2. def parse(self, response): 这个函数下面操作代码的数据解析
3.response.xpath() scrapy用来定位标签的xpath,用法和etree的xpath差不多,但是response.xpath是scrapy自己封装的
4.scrapy的数据解析
- 在scrapy中使用xpath解析标签中的文本内容或者标签属性的话,最终获取的是一个Selector的对象,且我们需要的字符串数据全部被封装在了该对象中
- 如果可以确定xpath返回的列表只有一个列表元素则使用extract_first(),否则使用extract()
5.运行之前,settings里面的一些参数需要设置
# -*- coding: utf-8 -*-
import scrapy
from qiubaiPro.items import QiubaiproItem
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
#允许的域名,一般注释掉
# allowed_domains = ['www.xxx.com'] # 存放在该列表中的url都会被scrapy自动的进行请求发送
start_urls = ['https://www.qiushibaike.com/text/'] # 基于终端指令的持久化存储:可以将parse方法的返回值对应的数据进行本地磁盘文件的持久化存储
def parse(self, response):
all_data = [] #数据解析response.xpath:作者and段子内容
div_list = response.xpath('//div[@id="content-left"]/div') for div in div_list:
#在scrapy中使用xpath解析标签中的文本内容的话,最终获取的是一个Selector的对象,且我们需要的字符串数据全部被封装在了该对象中
#如果可以确定xpath返回的列表只有一个列表元素则使用extract_first(),否则使用extract()
author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
content = div.xpath('./a/div/span/text()').extract()
dic = {
'author':author,
'content':content
}
all_data.append(dic)
# print(author,content)
return all_data
scrapy基于终端指令的持久化存储
scrap基于管道的持久化存储
1.开启管道settings设置里面 需要手动打开管道
ITEM_PIPELINES = {
'qiubaiPro.pipelines.QiubaiproPipeline': 300,
# 'qiubaiPro.pipelines.mysqlPileLine': 301,
'qiubaiPro.pipelines.redisPileLine': 302,
#300表示的是优先级,数值越小优先级越高
}
2.
- 爬虫文件中获取文件信息
- 创建一个item的类对象 item = QiubaiproItem()
- 将解析数据存储到item对象中 item['author'] = author
- 将item提交给管道类 yield item
# -*- coding: utf-8 -*-
import scrapy
from qiubaiPro.items import QiubaiproItem
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.xxx.com']
# 存放在该列表中的url都会被scrapy自动的进行请求发送
start_urls = ['https://www.qiushibaike.com/text/'] #基于管道实现持久化存储
def parse(self, response):
all_data = []
#数据解析:作者and段子内容
div_list = response.xpath('//div[@id="content-left"]/div')
for div in div_list:
#在scrapy中使用xpath解析标签中的文本内容的话,最终获取的是一个Selector的对象,且我们需要的字符串数据全部被封装在了该对象中
#如果可以确定xpath返回的列表只有一个列表元素则使用extract_first(),否则使用extract()
author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
if not author:
author = '匿名用户'
content = div.xpath('./a/div/span/text()').extract()
content = ''.join(content) #创建一个item类型的对象(只可以存储一组解析的数据)
item = QiubaiproItem()
#将解析到的数据存储到item对象中
item['author'] = author
item['content'] = content #将item提交给管道类
yield item
3.管道pipelines.py的介绍
- 管道类里面使用数据库对爬取的文件进行存储
# -*- coding: utf-8 -*-
#
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
from redis import Redis
# 一个管道类对应一种平台的数据存储
class QiubaiproPipeline(object):
fp = None
#重写父类的方法:只在开始爬虫的时候被执行一次
def open_spider(self,spider):
print('开始爬虫......')
self.fp = open('./qiubai.txt','w',encoding='utf-8') #处理item类型的对象
#什么是处理?
#将封装在item对象中的数据值提取出来且进行持久化存储
#参数item表示的就是爬虫文件提交过来的item对象
#该方法每接收一个item就会被调用一次
def process_item(self, item, spider):
print('this is process_item()')
author = item['author']
content = item['content'] self.fp.write(author+':'+content+"\n")
#返回的item就会传递给下一个即将被执行的管道类
return item
def close_spider(self,spider):
print('结束爬虫!')
self.fp.close() #将数据同时存储到mysql
class mysqlPileLine(object):
conn = None
cursor = None
def open_spider(self,spider):
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,db='spider',user='root',password='',charset='utf8')
print(self.conn)
def process_item(self,item,spider):
sql = 'insert into qiubai values ("%s","%s")'%(item['author'],item['content'])
#创建一个游标对象
self.cursor = self.conn.cursor()
try:
self.cursor.execute(sql)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
#数据存储到redis中
class redisPileLine(object):
conn = None
def open_spider(self,spider):
self.conn = Redis(host='127.0.0.1',port=6379)
def process_item(self,item,spider):
dic = {
'author':item['author'],
'content':item['content']
}
self.conn.lpush('qiubaiData',dic)
4.item.py的介绍
- item.py文件中定义item类型的属性
import scrapy
class QiubaiproItem(scrapy.Item):
# define the fields for your item here like:
author = scrapy.Field()
content = scrapy.Field()
scrapy框架第二天的更多相关文章
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- python爬虫入门(七)Scrapy框架之Spider类
Spider类 Spider类定义了如何爬取某个(或某些)网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item). 换句话说,Spider就是您定义爬取的动作 ...
- Scrapy 框架流程详解
框架流程图 Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向): 简单叙述一下每层图的含义吧: Spiders(爬虫):它负责处理所有Respon ...
- 解读Scrapy框架
Scrapy框架基础:Twsited Scrapy内部基于事件循环的机制实现爬虫的并发.原来: url_list = ['http://www.baidu.com','http://www.baidu ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- scrapy框架整理
0.安装scrapy框架 pip install scrapy 注:找不到的库,或者安装部分库报错,去python第三方库中找,很详细 https://www.lfd.uci.edu/~gohlke/ ...
- scrapy框架学习之路
一.基础学习 - scrapy框架 介绍:大而全的爬虫组件. 安装: - Win: 下载:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted pip3 ...
- Scrapy框架爬虫
一.sprapy爬虫框架 pip install pypiwin32 1) 创建爬虫框架 scrapy startproject Project # 创建爬虫项目 You can start your ...
随机推荐
- 如何在 spring 中启动注解装配?
默认情况下,Spring 容器中未打开注解装配.因此,要使用基于注解装配,我们 必须通过配置 <context:annotation-config/> 元素在 Spring 配置文件 中启 ...
- Java 中,DOM 和 SAX 解析器有什么不同?
DOM 解析器将整个 XML 文档加载到内存来创建一棵 DOM 模型树,这样可以 更快的查找节点和修改 XML 结构,而 SAX 解析器是一个基于事件的解析器, 不会将整个 XML 文档加载到内存.由 ...
- 什么是持续集成CI?
持续集成(CI)是每次团队成员提交版本控制更改时自动构建和测试代码的过程. 这鼓励开发人员通过在每个小任务完成后将更改合并到共享版本控制存储库来共 享代码和单元测试.
- Python - 异常处理初步
- 10分钟go crawler colly从入门到精通
Introduction 本文对colly如何使用,整个代码架构设计,以及一些使用实例的收集. Colly是Go语言开发的Crawler Framework,并不是一个完整的产品,Colly提供了类似 ...
- C语言形参和实参的区别(非常详细)
如果把函数比喻成一台机器,那么参数就是原材料,返回值就是最终产品:从一定程度上讲,函数的作用就是根据不同的参数产生不同的返回值.这一节我们先来讲解C语言函数的参数,下一节再讲解C语言函数的返回值.C语 ...
- STM32 标准库
CMSIS 标准及库层次关系 因为基于Cortex 系列芯片采用的内核都是相同的,区别主要为核外的片上外设的差异,这些差异却导致软件在同内核,不同外设的芯片上移植困难.为了解决不同的芯片厂商生产的Co ...
- STM32 之 HAL库(固件库)
1 STM32的三种开发方式 通常新手在入门STM32的时候,首先都要先选择一种要用的开发方式,不同的开发方式会导致你编程的架构是完全不一样的.一般大多数都会选用标准库和HAL库,而极少部分人会通过直 ...
- 【Android开发】Bitmap的质量压缩法
public static Bitmap compressImage(Bitmap image) { ByteArrayOutputStream baos = new ByteArrayOutputS ...
- js new Date()参数格式
最近在写页面使用new Date()获取时间戳在ie浏览器中测试发现无效:后来发现是参数格式问题, new Date()参数格式如下: 1.用整数初始化日期对象 var date1 = new Dat ...