scrapy框架整理
0.安装scrapy框架
pip install scrapy
注:找不到的库,或者安装部分库报错,去python第三方库中找,很详细
https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
1.创建一个scrapy框架
scrapy startproject 项目名

2.使用scrapy框架爬虫的三个步骤
a.配置items文件,确定需要爬取的字段
b.配置pipeline文件,确定文件的存储方式,并在setting文件中配置管道文件
注:如果存的是json数据,json.dumps(dict(item), ensure_ascii=False)
这里要记得将ensure_ascii置为False,原因是因为默认为ascii编码,但是中文用ascii编码会有问题
c.配置爬虫文件(分为两种,父类为Spider,CrawlSpider)
在终端中进入到项目目录下,执行:
scrapy genspider 爬虫名 限制的域名范围(创建Spider模板)
scrapy genspider -t crawl 爬虫名 限制的域名范围(创建CrawlSpider模板)
3.Spider类的使用
a.三个变量:name(爬虫名), allowed_domains(限定域), start_urls(最先请求的网站)
b.重写parse()方法,方法名必须是这个
c.在函数的最后yield item,会把item交给管道文件处理
d.如果需要再次发送请求的话需要 yield scrapy.Request(url,meta,callback)方法
url:为再次请求的地址
meta:请求携带的内容(字典格式),可以被response.meta取到,用于两个函数之间变量的传递
callback:请求的回调函数
4.CrawlSpider类的使用
a.三个变量(与Spider类一致)
b.rules规则的定义(用于匹配需要爬取的链接内容,且每次请求的页面也遵循这个规则)
优点:比Spider类更简洁,不需要写scrapy.Request()再次发送请求
注:rule规则可以写多条,如第一个规则用于翻页,第二个规则用于匹配当前页内中的链接
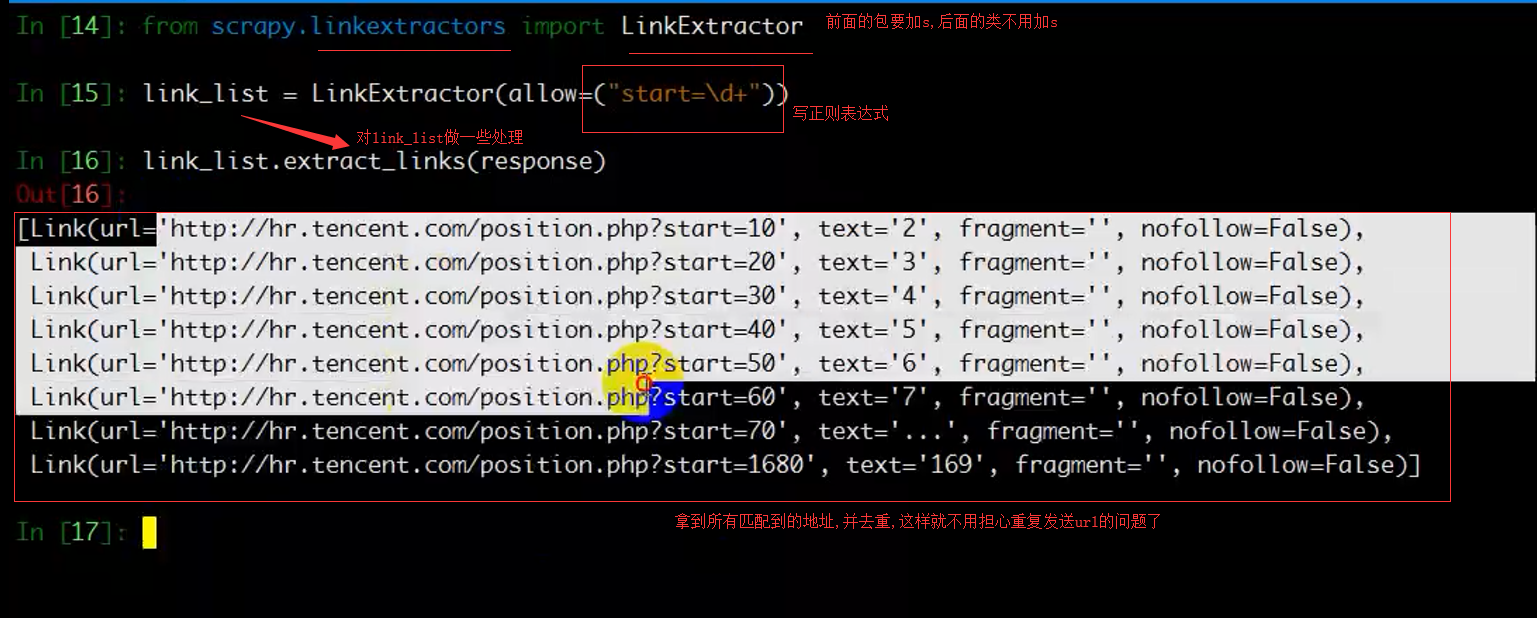
例:rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
allow:代表使用正则来匹配链接
restrict_xpaths:代表使用xpath来匹配链接
restrict_css:代表使用beautifulsoup4来匹配链接

callback:回调函数
follow:是否跟进(如果没有callback,follow默认为True),应用在匹配页码链接时,需要跟进
如果有callback,follow默认为False
注:在使用CrawlSpider时,callback不能再写parse,因为框架使用了parse实现其逻辑,我们在使用时,需要另起一个名字
5.中间件的设置
1.定义User-Agent列表,循环使用

2.如果需要使用代理服务器,需要设置代理,并附上对应的host和账号密码

scrapy框架整理的更多相关文章
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- Scrapy 框架流程详解
框架流程图 Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向): 简单叙述一下每层图的含义吧: Spiders(爬虫):它负责处理所有Respon ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- 12.scrapy框架
一.Scrapy 框架简介 1.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个 ...
- Scrapy 框架 安装
Scrapy 框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页 ...
- Scrapy框架学习笔记
1.Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网 ...
- scrapy框架系列 (1) 初识scrapy
Scrapy 框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页 ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
随机推荐
- 多对多关联模型,MANY_TOMANY
先分别创建三张表:think_user think_group think_user_group user 表里有id.name字段 group 表里有id.groupName字段 user_ ...
- Spring中的事务操作
事务的特性 原子性:强调事务的不可分割. 一致性:事务的执行的前后数据的完整性保持一致. 隔离性:一个事务执行的过程中,不应该受到其他事务的干扰. 持久性:事务一旦结束,数据就持久化到数据库. 如果不 ...
- 020-并发编程-java.util.concurrent之-jdk6/7/8中ConcurrentHashMap、HashMap分析
一.概述 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表. 是根据关键码值(Key ...
- 【UML】NO.51.EBook.5.UML.1.011-【UML 大战需求分析】- 时序图(Timing Diagram)
1.0.0 Summary Tittle:[UML]NO.51.EBook.1.UML.1.011-[UML 大战需求分析]- 时序图(Timing Diagram) Style:DesignPatt ...
- alias用法
echo 'alias msfconsole="pushd $HOME/git/metasploit-framework && ./msfconsole && ...
- ch01 PHP开篇
ch01 PHP开篇 1.1启蒙知识 思考:WAMP是什么?:集成开发环境 [Windows+Apache服务器+MySQL数据库+PHP编程] 1.1.1 站点 将网站所有相关素材都放到一个文件夹中 ...
- sql server 按年月日分组
sql server 按年月日分组 ----------------------------------------------- --author:yangjinwang --date:2017- ...
- ZAmbIE [DDoS Attacks](DDOS攻击)
在youtube上发现的一个视频 这是一个开源项目 git clone https://github.com/zanyarjamal/zambie.git chmod -R 777 zambie cd ...
- 2014-2015 ACM-ICPC, Asia Xian Regional Contest GThe Problem to Slow Down You
http://blog.csdn.net/u013368721/article/details/42100363 回文树 建立两棵回文树,然后count处理一遍就可以了,然后顺着这两棵树的边走下去就 ...
- codeforces 982C Cut 'em all!
题意: 给出一棵树,问最多去掉多少条边之后,剩下的连通分量的size都是偶数. 思路: 如果本来就是奇数个点,那么无论去掉多少条边都不可能成立的. 如果是偶数个点,就进行一次dfs,假设一个点的父亲是 ...