HBase-4MapReduce
集成分析
- HBase表中的数据最终都是存储在HDFS上,HBase天生的支持MR的操作,我们可以通过MR直接处理HBase表中的数据,
并且MR可以将处理后的结果直接存储到HBase表中。 - 参考地址:http://hbase.apache.org/book.html#mapreduce
1 实现方式一
- 读取HBase当中某张表的数据,将数据写入到另外一张表的列族里面去
2 实现方式二
- 读取HDFS上面的数据,写入到HBase表里面去
3 实现方式三
通过bulkload的方式批量加载数据到HBase表中
加载数据到HBase当中去的方式多种多样,我们可以使用HBase的javaAPI或者使用sqoop将我们的数据写入或者导入到HBase当中去,
但是这些方式不是最佳的,因为在导入的过程中占用Region资源导致效率低下- HBase数据正常写流程回顾

- HBase数据正常写流程回顾
通过MR的程序,将我们的数据直接转换成HBase的最终存储格式HFile,然后直接load数据到HBase当中去即可
- bulkload方式的处理示意图
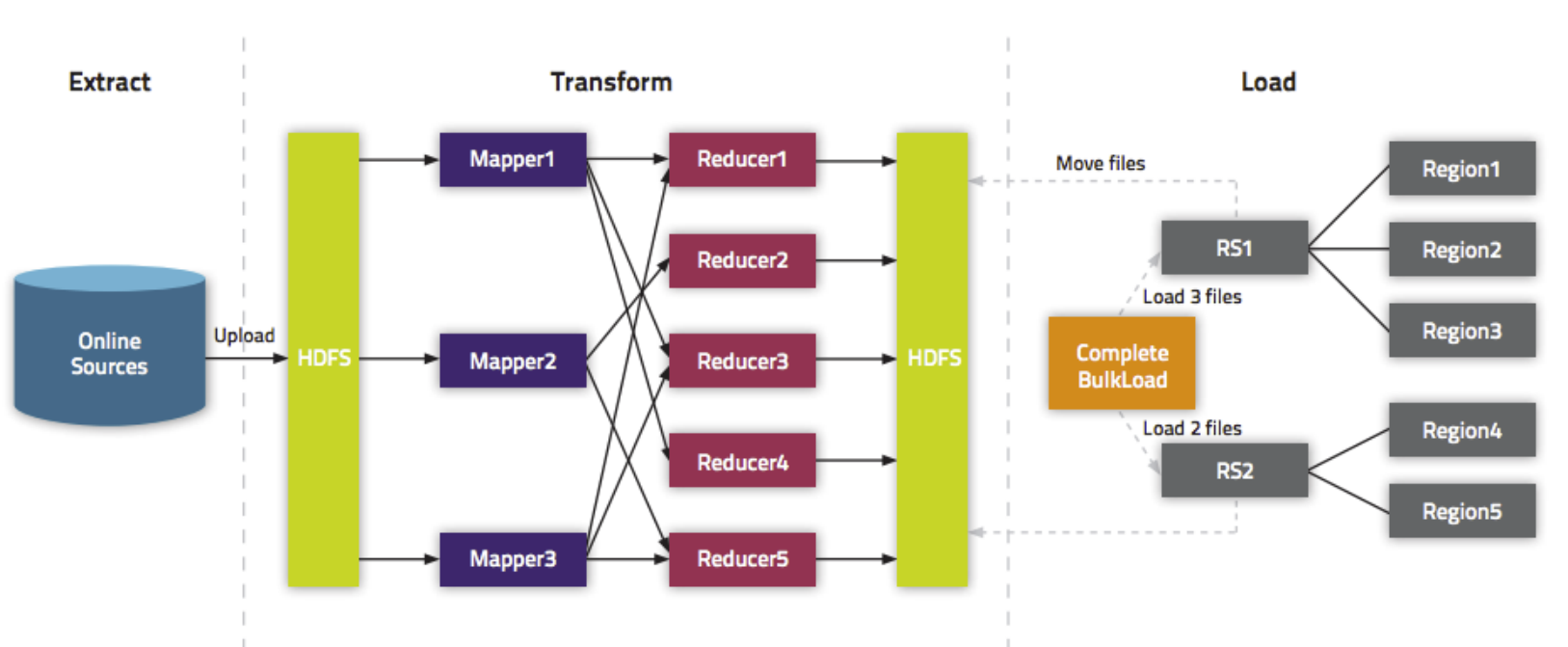
- bulkload方式的处理示意图
使用bulkload的方式批量加载数据的好处
- 导入过程不占用Region资源
- 能快速导入海量的数据
- 节省内存
实现方式一
- 读取HBase当中person这张表的info1:name、info2:age数据,将数据写入到另外一张person1表的info1列族里面去
- 第一步:创建person1这张hbase表
注意:列族的名字要与person表的列族名字相同
create 'person1','info1'
- 第二步:创建maven工程并导入jar包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>tenic</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>HbaseMrDdemo</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*/RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 第三步:开发MR程序实现功能
- 自定义map类
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class HBaseReadMapper extends TableMapper<Text, Put> {
/**
* @param key rowKey
* @param value rowKey此行的数据 Result类型
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
// 获得rowKey的字节数组
byte[] rowKeyBytes = key.get();
String rowKeyStr = Bytes.toString(rowKeyBytes);
Text text = new Text(rowKeyStr);
Put put = new Put(rowKeyBytes);
// 获取一行中所有的Cell对象
Cell[] cells = value.rawCells();
for (Cell cell : cells) {
//列族
byte[] familyBytes = CellUtil.cloneFamily(cell);
String familyStr = Bytes.toString(familyBytes);
//当前cell是否是info1
if ("info1".equals(familyStr)) {
//在判断是否是name | age
byte[] qualifier_bytes = CellUtil.cloneQualifier(cell);
String qualifierStr = Bytes.toString(qualifier_bytes);
if ("name".equals(qualifierStr) || "age".equals(qualifierStr)) {
put.add(cell);
}
}
}
// 判断是否为空;不为空,才输出
if (!put.isEmpty()) {
context.write(text, put);
}
}
}
- 自定义reduce类
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.Text;
import java.io.IOException;
/**
* TableReducer第三个泛型包含rowkey信息
*/
public class HBaseWriteReducer extends TableReducer<Text, Put, ImmutableBytesWritable> {
//将map传输过来的数据,写入到hbase表
@Override
protected void reduce(Text key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
//key 就是上边mapper阶段输出的rowkey
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable();
immutableBytesWritable.set(key.toString().getBytes());
//遍历put对象,并输出
for(Put put: values) {
context.write(immutableBytesWritable, put);
}
}
}
- main入口类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Main extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
// 设定绑定的zk集群
configuration.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
int run = ToolRunner.run(configuration, new Main(), args);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf());
job.setJarByClass(Main.class);
// mapper
TableMapReduceUtil.initTableMapperJob(TableName.valueOf("person"), new Scan(), HBaseReadMapper.class, Text.class, Put.class, job);
// reducer
TableMapReduceUtil.initTable ReducerJob("person1", HBaseWriteReducer.class, job);
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
}

实现方式二
- 读取hdfs上面的数据,写入到hbase表里面去
hadoop03执行以下命令准备数据文件,并将数据文件上传到HDFS上面去
在/bigdata/install/documents/目录,创建user.txt文件
cd /bigdata/install/documents/
vi user.txt
内容如下:
rk0003 honghong 18
rk0004 lilei 25
rk0005 kangkang 22
将文件上传到hdfs的路径下面去
hdfs dfs -mkdir -p /hbase/input
hdfs dfs -put /bigdata/install/documents/user.txt /hbase/input/
- 代码开发
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import java.io.IOException;
/**
* 将HDFS上文件/hbase/input/user.txt数据,导入到HBase的person1表
*/
public class HDFS2HBase {
public static class HDFSMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
// 数据原样输出
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, NullWritable.get());
}
}
public static class HBaseReducer extends TableReducer<Text, NullWritable, ImmutableBytesWritable> {
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
/**
* key -> 一行数据
* 样例数据:
*rk0003 honghong 18
*rk0004 lilei 25
*rk0005 kangkang 22
*/
String[] split = key.toString().split("\t");
// split[0] 对应的是rowkey
Put put = new Put(Bytes.toBytes(split[0]));
put.addColumn("info1".getBytes(), "name".getBytes(), split[1].getBytes());
put.addColumn("info1".getBytes(), "age".getBytes(), split[2].getBytes());
context.write(new ImmutableBytesWritable(Bytes.toBytes(split[0])), put);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = HBaseConfiguration.create();
// 设定zk集群
conf.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
Job job = Job.getInstance(conf);
job.setJarByClass(HDFS2HBase.class);
job.setMapperClass(HDFSMapper.class);
job.setInputFormatClass(TextInputFormat.class);
// map端的输出的key value 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 设置reduce个数
job.setNumReduceTasks(1);
// 输入文件路径
TextInputFormat.addInputPath(job, new Path("hdfs://hadoop01:8020/hbase/input/user.txt"));
// 指定输出到hbase的表名
TableMapReduceUtil.initTableReducerJob("person1", HBaseReducer.class, job);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

实现方式三
- HDFS上面的这个路径/hbase/input/user.txt的数据文件,转换成HFile格式,然后load到person1这张表里面去
- 1、开发生成HFile文件的代码
- 自定义map类
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// 四个泛型中后两个,分别对应rowkey及put
public class BulkLoadMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
// 封装输出的rowkey类型
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable(split[0].getBytes());
// 构建put对象
Put put = new Put(split[0].getBytes());
put.addColumn("info1".getBytes(), "name".getBytes(), split[1].getBytes());
put.addColumn("info1".getBytes(), "age".getBytes(), split[2].getBytes());
context.write(immutableBytesWritable, put);
}
}
- 程序main
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class HBaseBulkLoad extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
//设定zk集群
configuration.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
int run = ToolRunner.run(configuration, new HBaseBulkLoad(), args);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = super.getConf();
Job job = Job.getInstance(conf);
job.setJarByClass(HBaseBulkLoad.class);
TextInputFormat.addInputPath(job, new Path("hdfs://hadoop01:8020/hbase/input/user.txt"));
job.setMapperClass(BulkLoadMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
Connection connection = ConnectionFactory.createConnection(conf);
Table table = connection.getTable(TableName.valueOf("person1"));
//使MR可以向myuser2表中,增量增加数据
HFileOutputFormat2.configureIncrementalLoad(job, table, connection.getRegionLocator(TableName.valueOf("person1")));
//数据写回到HDFS,写成HFile -> 所以指定输出格式为HFileOutputFormat2
job.setOutputFormatClass(HFileOutputFormat2.class);
HFileOutputFormat2.setOutputPath(job, new Path("hdfs://hadoop01:8020/hbase/out_hfile"));
//开始执行
boolean b = job.waitForCompletion(true);
return b? 0: 1;
}
}
3、观察HDFS上输出的结果

4、加载HFile文件到hbase表中
- 方式一:代码加载
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.tool.BulkLoadHFiles; public class LoadData { public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "hadoop01,hadoop02,hadoop03");
// 获取数据库连接
Connection connection = ConnectionFactory.createConnection(configuration);
// 获取表的管理器对象
Admin admin = connection.getAdmin();
// 获取table对象
TableName tableName = TableName.valueOf("person1");
Table table = connection.getTable(tableName);
// 构建BulkLoadHFiles加载HFile文件 hbase2.0 api
BulkLoadHFiles load = BulkLoadHFiles.create(configuration);
load.bulkLoad(tableName, new Path("hdfs://hadoop01:8020/hbase/out_hfile"));
}

HBase集成Hive
Hive提供了与HBase的集成,使得能够在HBase表上使用hive sql 语句进行查询、插入操作以及进行Join和Union等复杂查询,同时也可以将hive表中的数据映射到Hbase中
1 HBase与Hive的对比
1.1 Hive
- 数据仓库管理系统
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。 - 用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高 - 基于HDFS、MapReduce(或者其他计算引擎如:Tez、Spark)
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。(不要钻不需要执行MapReduce代码的情况的牛角尖)
1.2 HBase
- 数据库管理系统
是一种面向列存储的非关系型数据库。 - 用于存储结构化和非结构话的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。 - 基于HDFS
数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。 - 延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
1.3 总结:Hive与HBase
- Hive和Hbase是两种基于Hadoop的不同技术,Hive是一种类SQL的引擎,并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL 的Key/vale数据库。
这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,
数据也可以从Hive写到HBase,或者从HBase写回Hive。
我们来做2个小案例,Hive中表数据导入到Hbase中,Hbase中的表数据导入到Hive
注意:请确保安装Hadoop、zookeeper、hive、hbase、mysql,具体安装过程请查看其他博客文章
| hadoop01 | hadoop02 | hadoop03 | |
|---|---|---|---|
| namenode | x | ||
| secondnamenode | x | ||
| datanode | x | x | x |
| yarn | x | ||
| zk | x | x | x |
| Hive | x | ||
| Hbase | x | ||
| mysql | x |
Hive整合Hbase
1 拷贝jar包
- 将我们HBase的五个jar包拷贝到Hive的lib目录下
- Hbase的jar包都在/bigdata/install/hbase-2.2.6/lib
- 我们需要拷贝五个jar包名字如下
hbase-client-2.2.6.jar
hbase-hadoop2-compat-2.2.6.jar
hbase-hadoop-compat-2.2.6.jar
hbase-it-2.2.6.jar
hbase-server-2.2.6.jar
- 在hadoop02执行以下命令
cd /bigdata/install/hbase-2.2.6/lib
cp hbase-protocol-2.2.6.jar /bigdata/install/hive-3.1.2/lib/
cp hbase-server-2.2.6.jar /bigdata/install/hive-3.1.2/lib/
cp hbase-client-2.2.6.jar /bigdata/install/hive-3.1.2/lib/
cp hbase-common-2.2.6.jar /bigdata/install/hive-3.1.2/lib/
cp hbase-common-2.2.6-tests.jar /bigdata/install/hive-3.1.2/lib/
2 修改hive的配置文件
- 编辑hadoop02服务器上面的Hive的配置文件hive-site.xml
cd /bigdata/install/hive-3.1.2/conf
vim hive-site.xml
- 添加以下两个属性的配置
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop01,hadoop02,hadoop03</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01,hadoop02,hadoop03</value>
</property>
3 修改hive-env.sh配置文件
cd /bigdata/install/hive-3.1.2/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
- 添加以下配置
export HADOOP_HOME=/bigdata/install/hadoop-3.1.4
export HBASE_HOME=/bigdata/install/hbase-2.2.2
export HIVE_CONF_DIR=/bigdata/install/hive-3.1.2/conf
Hive中表数据导入到Hbase
1 Hive当中建表
- hadoop02执行以下命令,进入Hive客户端,并创建Hive表
cd /bigdata/install/hive-3.1.2/
bin/hive
- 创建Hive数据库与Hive对应的数据库表
create database course;
use course;
create external table if not exists course.score(id int, cname string, score int)
row format delimited fields terminated by '\t' stored as textfile ;
2 准备数据内容如下并加载到Hive表
- hadoop02执行以下命令,创建数据文件
cd /bigdata/install/
mkdir docouments
cd /bigdata/install/docouments
vim hive-hbase.txt
- 文件内容如下
1 zhangsan 80
2 lisi 60
3 wangwu 30
4 zhaoliu 70
- 进入Hive客户端进行加载数据
hive (course)> load data local inpath '/bigdata/install/docouments/hive-hbase.txt' into table score;
hive (course)> select * from score;
3 创建Hive管理表与HBase进行映射
- 我们可以创建一个Hive的管理表与Hbase当中的表进行映射,Hive管理表当中的数据,都会存储到Hbase上面去
- Hive当中创建内部表
create table course.hbase_score(id int,cname string,score int)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping" = "cf:name,cf:score") tblproperties("hbase.table.name" = "hbase_score");
- 通过insert overwrite select 插入数据
insert overwrite table course.hbase_score select id,cname,score from course.score;
4 Hbase当中查看表hbase_score
- 进入Hbase的客户端查看表hbase_score,并查看当中的数据
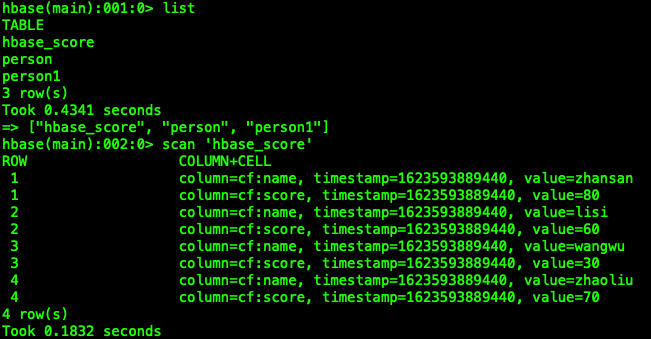
创建Hive外部表,映射HBase当中已有的表模型
1 HBase当中创建表并手动插入加载一些数据
- 进入HBase的shell客户端,
bin/hbase shell
- 手动创建一张表,并插入加载一些数据进去
# 创建一张表
# 通过put插入数据到hbase表
create 'hbase_hive_score',{ NAME =>'cf'}
put 'hbase_hive_score','1','cf:name','zhangsan'
put 'hbase_hive_score','1','cf:score', '95'
put 'hbase_hive_score','2','cf:name','lisi'
put 'hbase_hive_score','2','cf:score', '96'
put 'hbase_hive_score','3','cf:name','wangwu'
put 'hbase_hive_score','3','cf:score', '97'
- 查看以下HBase当中hbase_hive_score表的数据
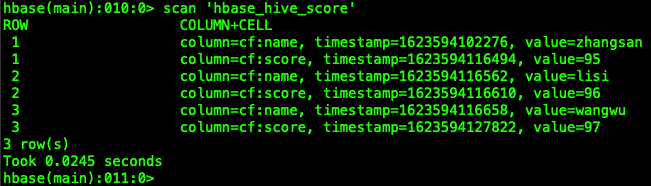
2 建立hive的外部表,映射HBase当中的表以及字段
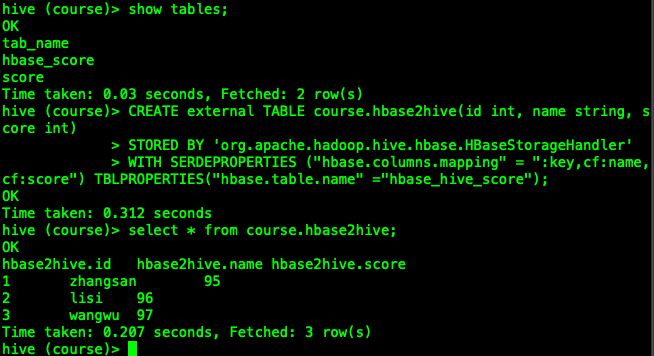
- 进入Hive客户端,然后执行以下命令进行创建Hive外部表,就可以实现映射HBase当中的表数据
CREATE external TABLE course.hbase2hive(id int, name string, score int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf:name,cf:score") TBLPROPERTIES("hbase.table.name" ="hbase_hive_score");
- 查看Hive表course.hbase2hive
select * from course.hbase2hive;
HBase-4MapReduce的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- Redis/HBase/Tair比较
KV系统对比表 对比维度 Redis Redis Cluster Medis Hbase Tair 访问模式 支持Value大小 理论上不超过1GB(建议不超过1MB) 理论上可配置(默认配置1 ...
- Hbase的伪分布式安装
Hbase安装模式介绍 单机模式 1> Hbase不使用HDFS,仅使用本地文件系统 2> ZooKeeper与Hbase运行在同一个JVM中 分布式模式– 伪分布式模式1> 所有进 ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- 深入学习HBase架构原理
HBase定义 HBase 是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群. HBase 是Google Bigtabl ...
- hbase协处理器编码实例
Observer协处理器通常在一个特定的事件(诸如Get或Put)之前或之后发生,相当于RDBMS中的触发器.Endpoint协处理器则类似于RDBMS中的存储过程,因为它可以让你在RegionSer ...
- hbase集群安装与部署
1.相关环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 hbase1.2.4 本篇文章仅涉及hbase集群的搭建,关于hadoop与zookeeper的相关部 ...
- 从零自学Hadoop(22):HBase协处理器
阅读目录 序 介绍 Observer操作 示例下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,Sour ...
- Hbase安装和错误
集群规划情况: djt1 active Hmaster djt2 standby Hmaster djt3 HRegionServer 搭建步骤: 第一步:配置conf/regionservers d ...
随机推荐
- 洛谷:P5707 【深基2.例12】上学迟到 (纯净的顺序结构方法)
本内容纯作者吃饱了没事干做出来的,仅供娱乐和思路参考(当然代码肯定是AC了) 最近我想重新提升一下自己的编程能力,想选一个题量比较精炼的平台,所以就用了洛谷. 题目描述 学校和 yyy 的家之间的距离 ...
- Rust 的静态网站生成器「GitHub 热点速览」
如果你做过个人博客网站,那么一定对静态网站生成器不陌生.无论是 Ruby 语言的 Jekyll.Go 语言的 Hugo.还是基于 React 的 Gatsby,这些工具都有庞大的用户群体.对于喜欢的人 ...
- Python基础:Python可变对象和不可变对象
Python在heap中分配的对象分成两类:可变对象和不可变对象.所谓可变对象是指,对象的内容是可变的,例如list.而不可变的对象则相反,表示其内容不可变. 不可变对象:int,string,flo ...
- vue父组件向子组件传递一个对象,使用一个对象绑定多个 prop
如果你想要将一个对象的所有属性都当作 props 传入,你可以使用没有参数的 v-bind,即只使用 v-bind 而非 :prop-name.例如,这里有一个 post 对象: export def ...
- 面试:10亿数据如何最快速插入MySQL?
转载:https://mp.weixin.qq.com/s/kL1srP3FZjaTSXLULsUS5g 最快的速度把10亿条数据导入到数据库,首先需要和面试官明确一下,10亿条数据什么形式存在哪里, ...
- Yii2之model
记录model常用方法 between: $model->andFilterWhere(['between','apply_time',$startTime,$endTime])
- python命令行工具之Click
Click 是一个简洁好用的Python模块,它能用尽量少的代码实现漂亮的命令行界面.它不仅开箱即用.还能支持高度自定义的配置. 示例: import click @click.command() @ ...
- Graylog之基本使用
文档:https://docs.graylog.org/en/3.0/ Graylog Sidecar是一个轻量级配置管理系统,适用于不同的日志收集器,也称为后端.Graylog节点充当包含日志收集器 ...
- json数据对接
1.前言 fastadmin框架本身封装了一系列接口和插件来对表格数据进行管理(新增,编辑,删除),但是其使用的bootstrapTable基于jquery开发,基于某些原因,我们想要使用Vue框架代 ...
- Gitee三方登录_Python (超详细)
第三方登录是一种常见的身份验证机制,允许用户使用他们在其他平台(如社交媒体.电子邮件服务或开发平台)的账号来登录你的应用或网站,而不需要创建新的用户名和密码.这种方式不仅简化了用户的登录过程,还提高了 ...