爬虫项目之爬取4K高清壁纸
爬虫项目之爬取4K高清壁纸
目标网址:4K壁纸高清图片_电脑桌面手机全面屏壁纸4K超清_高清壁纸4K全屏 - 壁纸汇
使用技术Selenium+Requests
下面是目标网页
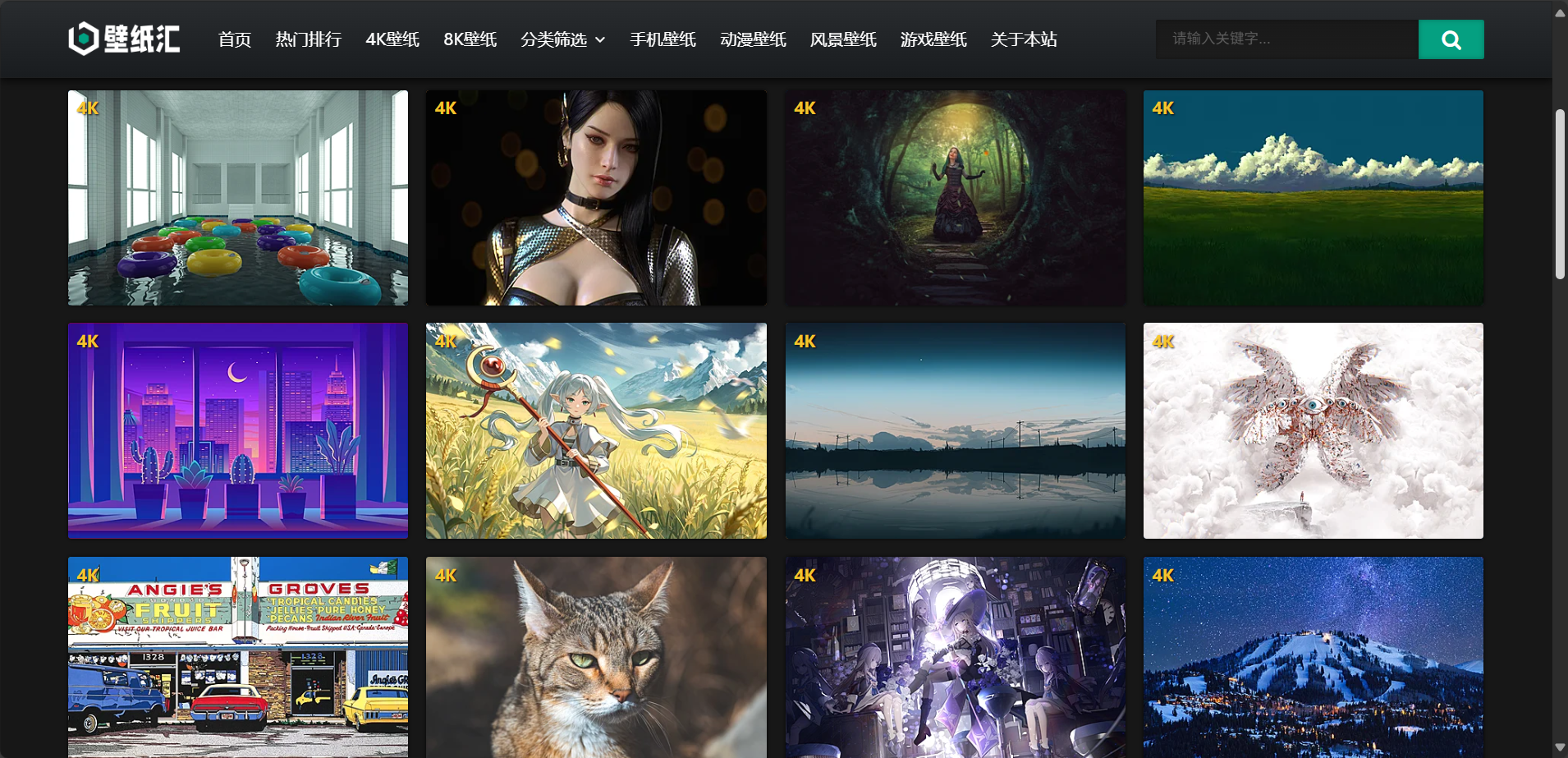
思路:由于此网页是通过不断下拉的方式刷新图片,而不是通过分页的方式加载新的图片,所以不能使用requests+xpath技术直接爬取该网页,所以采用Selenium操作网页,控制网页下滑获取最新图片。下面让我们来看代码。
第一步:首先设置无头显示,再打开目标网页。
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.edge.options import Options
import requests
import os
import shutil #设置无头显示
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
web = Edge(options=opt) #打开目标网页
url = 'https://www.bizhihui.com/tags/4Kbizhi/'
web.get(url)
time.sleep(1) #每次操作网页时必须让程序睡眠1秒,否则容易导致网页刷新失败,程序中断报错
第二步:通过不断循环不断下拉滚动条获取最新图片数据。
#滚动条设置
for i in range(5):
web.execute_script('document.documentElement.scrollTop=10000') #设置滚动条滚到最底下,0是顶部,10000是底部
time.sleep(2)
第三步:通过find_elements(By.TAG_NAME,'li')函数,获取该页面所有的li标签,并且筛选目标li标签,通过get_attribute('src')函数获取img标签的src属性,最后获取到图片的url和name,将它们放进字典img_url_list中。
#获取所有li标签
lis = web.find_elements(By.TAG_NAME,'li')
time.sleep(1) #通过li标签爬取目标图片的url
img_url_list = {}
for li in lis:
if li.get_attribute('class')=='item-list masonry-brick':#筛选class=item-list masonry-brick的li标签
img_src = li.find_element(By.TAG_NAME,'img').get_attribute('src') #获取img标签的src属性
img_url = img_src[:-9]
img_name = img_url[-17:]
img_url_list[img_name]=img_url
第四步:通过os模块自带的函数判断文件夹是否存在,如果存在则通过shutil模块的rmtree方法删除,再通过os模块下的makedirs方法创建目录。
#判断文件夹是否存在,如果存在则删除,在创建
if os.path.exists('./img'):
shutil.rmtree('./img') #删除文件夹
os.makedirs('./img') #创建文件夹
第五步:循环上面得到的字典,通过requests方法下载图片并保存在新建的img文件夹中
#循环字典下载图片
i=1
for key in img_url_list:
resp = requests.get(img_url_list[key])
with open(f'./img/{key}','wb') as f:
f.write(resp.content)
print(f"下载{i}张图片。。。")
i+=1
f.close() #关闭文件 #下载完成
print("OVER!") #结束进程
web.close()
通过以上步骤我们就爬取到了网页上的图片了。
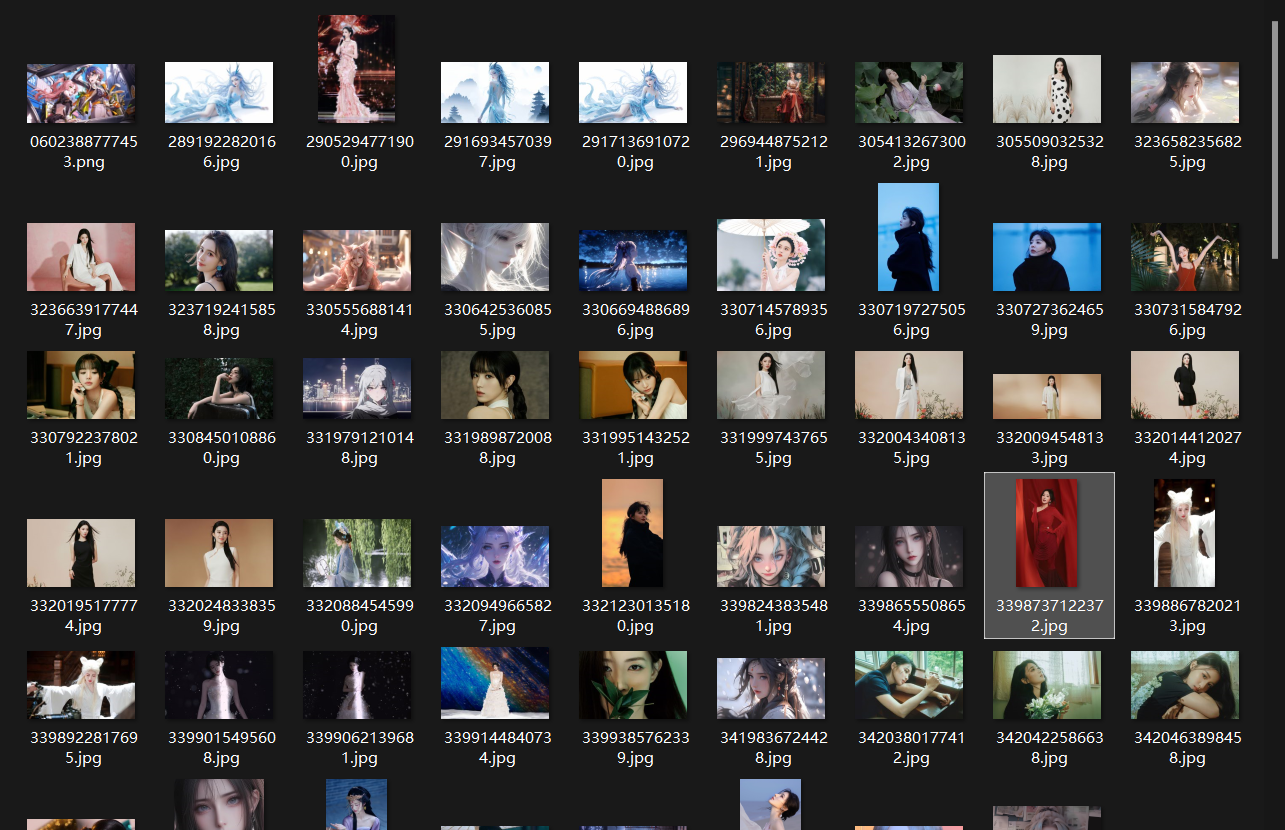
下面时程序源码:
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.edge.options import Options
import requests
import os
import shutil
#设置无头显示
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
web = Edge(options=opt)
# web = Edge()
#打开目标网页
url = 'https://www.bizhihui.com/tags/4Kbizhi/'
web.get(url)
time.sleep(1)
#滚动条设置
for i in range(5):
web.execute_script('document.documentElement.scrollTop=10000') #设置滚动条滚到最底下,0是顶部,10000是底部
time.sleep(2)
#获取所有li标签
lis = web.find_elements(By.TAG_NAME,'li')
time.sleep(1)
#通过li标签爬取目标图片的url
img_url_list = {}
for li in lis:
if li.get_attribute('class')=='item-list masonry-brick': #筛选class=item-list masonry-brick的li标签
img_src = li.find_element(By.TAG_NAME,'img').get_attribute('src') #获取img标签的src属性
img_url = img_src[:-9]
img_name = img_url[-17:]
img_url_list[img_name]=img_url
#判断文件夹是否存在,如果存在则删除,在创建
if os.path.exists('./img'):
shutil.rmtree('./img') #删除文件夹
os.makedirs('./img') #创建文件夹
#循环字典下载图片
i=1
for key in img_url_list:
resp = requests.get(img_url_list[key])
with open(f'./img/{key}','wb') as f:
f.write(resp.content)
print(f"下载{i}张图片。。。")
i+=1
f.close() #关闭文件
#下载完成
print("OVER!")
#结束进程
web.close()
爬虫项目之爬取4K高清壁纸的更多相关文章
- 别人用钱,而我用python爬虫爬取了一年的4K高清壁纸
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取htt ...
- 实例学习——爬取Pexels高清图片
近来学习爬取Pexels图片时,发现书上代码会抛出ConnectionError,经查阅资料知,可能是向网页申请过于频繁被禁,可使用time.sleep(),减缓爬取速度,但考虑到爬取数据较多,运行时 ...
- 编写python代码获取4k高清壁纸
Huskiesir最近在研究python爬虫大约俩周了吧,由于比较懒,也没把具体研究的过程与经验写下来,实在是一大憾事.这次直接上干货,代码送给大家: import re import request ...
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫练习:爬取800多所大学学校排名、星级等
前言 国内大学最新排名,北大反超,浙大仅第四,中科大跌至第八 时隔五年,"双一流"大学即将迎来首次大考,这也是继改变高校评断标准之后,第一次即将以官方对外发布,自然是引来了许多人的 ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- 爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章 一.简说安装相关环境及依赖包 1.安装Python(2或3都行,我这里用的是3) 2.虚拟环境搭建: 依赖包:virtualenv,virtualenvwr ...
- 爬虫入门之爬取策略 XPath与bs4实现(五)
爬虫入门之爬取策略 XPath与bs4实现(五) 在爬虫系统中,待抓取URL队列是很重要的一部分.待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪 ...
随机推荐
- .Net类型 引用类型
预定义类型引用类型 C#支持两种预定义的引用类型:object 和string 名称 .NET类型 说明 object System.Object 根类型,其他类型都是从它派生而来的(包括值类型) s ...
- react生命周期-渲染阶段
import React, { Component } from "react"; export default class Shengming extends Component ...
- oracle11gRAC升级到19C
升级oracle11g集群到19.3 前述环境检查: [root@qhdb1 ~]# crsctl status res -t ------------------------------------ ...
- Spark异常总结
1.Spark读写同一张表报错问题Cannot overwrite a path that is also being read from 问题描述:Spark SQL在执行ORC和Parquet格式 ...
- CSP 2024 游记
初赛 Day -1 唐,rp--了. 上午语文正卷满分,然后作文挂完了靠.我没想到我作文能挂到 40pts. 吃饭的时候 gcy 说了什么奇怪的东西,然后喷饭爆金币了,社死现场.吃饭的时候还 tm 咬 ...
- [MQ] Kafka
概述: Kafka 安装指南 安装 on Windows Step1 安装 JDK JDK 安装后: 在"系统变量"中,找到 JAVA_HOME,如果没有则新建,将其值设置为 JD ...
- 割以咏志:Stoer–Wagner 算法求解全局最小割
全局最小割问题(Global Min-Cut Problem)是图论中的一个经典问题,旨在通过切割图中的边来划分图的顶点集合.具体来说,给定一个加权无向图 $ G = (V, E) $,图中每条边 $ ...
- 【Unity】URP中的UGUIShader实现
[Unity]URP 中的 UGUIShader 实现 参考官方 Shader 代码实现: https://github.com/TwoTailsGames/Unity-Built-in-Shader ...
- 浅谈Processing中的 println() 打印输出函数[String]
简单看一下Processing中的打印输出函数println()相关用法. 部分源码学习 /** * ( begin auto-generated from println.xml ) * * Wri ...
- 支付宝 IoT 设备入门宝典(下)设备经营篇
上篇介绍了支付宝 IoT 设备管理,但除了这些基础功能外,商户还可以利用设备进行一些运营动作,让设备更好的帮助自己,本篇就会以设备经营为中心,介绍常见的设备相关能力和问题解决方案.如果对上篇感兴趣,可 ...