Python 爬取生成中文词云以爬取知乎用户属性为例
代码如下:
# -*- coding:utf-8 -*- import requests
import pandas as pd
import time import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba header={
'authorization':'Bearer 2|1:0|10:1515395885|4:z_c0|92:Mi4xOFQ0UEF3QUFBQUFBRU1LMElhcTVDeVlBQUFCZ0FsVk5MV2xBV3dDLVZPdEhYeGxaclFVeERfMjZvd3lOXzYzd1FB|39008996817966440159b3a15b5f921f7a22b5125eb5a88b37f58f3f459ff7f8',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36',
'X-UDID':'ABDCtCGquQuPTtEPSOg35iwD-FA20zJg2ps=',
} user_data = []
def get_user_data(page):
for i in range(page):
url = 'https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={}&limit=20'.format(i*20)
#response = requests.get(url, headers=header).text
response = requests.get(url, headers=header).json()['data']#['data'] 只有JSON格式中选择data节点
user_data.extend(response)
print('正在爬取%s页' % str(i+1))
time.sleep(1) if __name__=='__main__':
get_user_data(10)
#pandas 的函数 from_dict()可以直接将一个response变成一个对象
#df = pd.DataFrame.from_dict(user_data)
#df.to_csv('D:/PythonWorkSpace/TestData/zhihu/user2.csv')
df = pd.DataFrame.from_dict(user_data).get('headline')
df.to_csv('D:/PythonWorkSpace/TestData/zhihu/headline.txt') text_from_file_with_apath = open('D:/PythonWorkSpace/TestData/zhihu/headline.txt').read()
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba) my_wordcloud = WordCloud().generate(wl_space_split) plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
需要安装准备的库:
pip install matplotlib
pip install jieba
pip install wordcloud(发现这方法安装不成功)
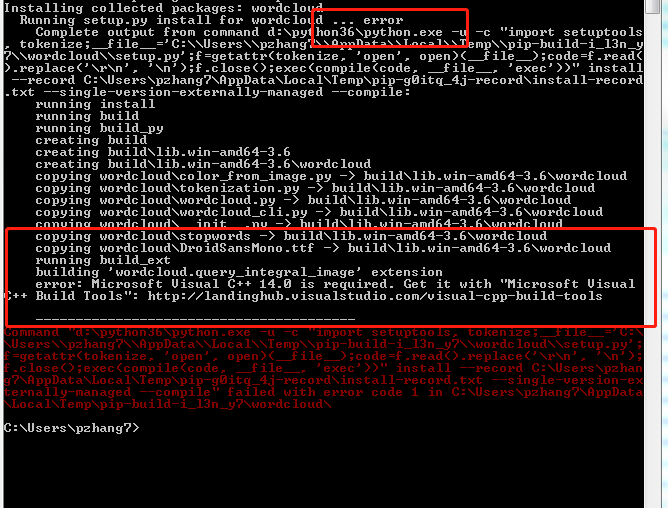
换种安装方式到 https://github.com/amueller/word_cloud 这里下载库文件,解压,然后进入到解压后的文件,按住shift+鼠标右键 打开命令窗口运行一下命令:
python setup.py install 然后同样报错
然后我又换了一张安装方式:
到 http://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud 页面下载所需的wordcloud模块的whl文件,下载后进入存储该文件的路径,按照方法一,执行“pip install wordcloud-1.3.3-cp36-cp36m-win_amd64.whl”,这样就会安装成功。
然后生成词云的代码如下:
text_from_file_with_apath = open('D:\Python\zhihu\headline.txt','r',encoding='utf-8').read()
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud = WordCloud().generate(wl_space_split)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
但是发现不显示中文,这可就头疼了。
显示的是一些大大小小的彩色框框。这是因为,我们使用的wordcloud.py中,FONT_PATH的默认设置不识别中文。
仔细研究之后做了改进,终于可以正常显示中文了
text_from_file_with_apath = open('D:\Python\zhihu\headline.txt','r',encoding='utf-8').read()
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
#FONT_PATH = os.environ.get("FONT_PATH", os.path.join(os.path.dirname(__file__), "simkai.ttf"))
cloud = WordCloud(
#设置字体,不指定就会出现乱码
font_path="simkai.ttf",
#设置背景色
background_color='white',
#允许最大词汇
max_words=9000,
#词云形状
#mask=color_mask
)#.generate(wl_space_split)
## 产生词云
word_cloud = cloud.generate(wl_space_split)
word_cloud.to_file('D:\Python\zhihu\headline.jpg')#将图片保存到指定文件中
#直接显示图片,并且可编辑
# plt.imshow(word_cloud)
# plt.axis("off")
# plt.show()

坑:
Python读取文件时经常会遇到这样的错误:python3.4 UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: illegal multibyte sequence
import codecs,sys
f = codecs.open("***.txt","r","utf-8")
指明打开文件的编码方式就可以消除错误了
Python 爬取生成中文词云以爬取知乎用户属性为例的更多相关文章
- Java爬取B站弹幕 —— Python云图Wordcloud生成弹幕词云
一 . Java爬取B站弹幕 弹幕的存储位置 如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号, ...
- Python基于jieba的中文词云
今日学习了python的词云技术 from os import path from wordcloud import WordCloud import matplotlib.pyplot as plt ...
- Scrapy+eChart自动爬取生成网络安全词云
因为工作的原因,近期笔者开始持续关注一些安全咨询网站,一来是多了解业界安全咨询提升自身安全知识,二来也是需要从各类安全网站上收集漏洞情报. 作为安全情报领域的新手,面对大量的安全咨询,多少还是会感觉无 ...
- 超详细:Python(wordcloud+jieba)生成中文词云图
# coding: utf-8 import jieba from scipy.misc import imread # 这是一个处理图像的函数 from wordcloud import WordC ...
- [python] 基于词云的关键词提取:wordcloud的使用、源码分析、中文词云生成和代码重写
1. 词云简介 词云,又称文字云.标签云,是对文本数据中出现频率较高的“关键词”在视觉上的突出呈现,形成关键词的渲染形成类似云一样的彩色图片,从而一眼就可以领略文本数据的主要表达意思.常见于博客.微博 ...
- python抓取数据构建词云
1.词云图 词云图,也叫文字云,是对文本中出现频率较高的"关键词"予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主旨. 先看几个词 ...
- Python第三方库wordcloud(词云)快速入门与进阶
前言: 笔主开发环境:Python3+Windows 推荐初学者使用Anaconda来搭建Python环境,这样很方便而且能提高学习速度与效率. 简介: wordcloud是Python中的一个小巧的 ...
- 从当当客户端api抓取书评到词云生成
看了好几本大冰的书,感觉对自己的思维有不少的影响.想看看其他读者的评论.便想从当当下手抓取他们评论做个词云.想着网页版说不定有麻烦的反爬,干脆从手机客户端下手好了.果其不然,找到一个书评的api.发送 ...
- 用Python实现一个词频统计(词云+图)
第一步:首先需要安装工具python 第二步:在电脑cmd后台下载安装如下工具: (有一些是安装好python电脑自带有哦) 有一些会出现一种情况就是安装不了词云展示库 有下面解决方法,需看请复制链接 ...
随机推荐
- Ribbon实现Office开始菜单
Ribbon实现Office开始菜单 界面效果: 首先:在主窗体上拖入popupMenu控件和imageCollection控件 然后选中popupMenu点击三角,再点击Run Designer在弹 ...
- HDU 2191 - 单调队列优化多重背包
题目: 传送门呀传送门~ Problem Description 急!灾区的食物依然短缺! 为了挽救灾区同胞的生命,心系灾区同胞的你准备自己采购一些粮食支援灾区,现在假设你一共有资金n元,而市场有m种 ...
- js 判断身份证好是否合法
function cidInfo(sId){ var info="" //if(!/^\d{17}(\d|x)$/i.test(sId))return false; sId=sId ...
- 【centos】 error: command 'gcc' failed with exit status 1
原文连接http://blog.csdn.net/fenglifeng1987/article/details/38057193 用安装Python模块出现error: command 'gcc' f ...
- 一:对程序员来说CPU是什么?
0.开篇 (1)程序是什么? 指示计算机每一步动作的一组指令 (2)程序是由什么组成的? 指令和数据 (3)什么是机器语言? ...
- 2017-2018-2 20155303『网络对抗技术』Exp5:MSF基础应用
2017-2018-2 20155303『网络对抗技术』Exp5:MSF基础应用 --------CONTENTS-------- 一.原理与实践说明 1.实践内容 2.预备知识 3.基础问题 二.实 ...
- 【逆向工具】IDA使用3-全局变量、数组、结构体
全局变量 测试代码 全局变量既可以是某对象函数创建,也可以是在本程序任何地方创建.全局变量是可以被本程序所有对象或函数引用.下面这段代码中将int.float.char变量定义在main函数之外. / ...
- grep用法【转】
简介 grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它 ...
- Expm 2_2 查找中项问题
对于长度为n的整型数组A,随机生成其数组元素值,然后实现一个线性时间的算法,在该数组中查找其中项. package org.xiu68.exp.exp3; import java.util.Array ...
- ThinkPHP 3.1.3及之前的版本使用不当可造成SQLi
Lib/Core/Model.class.php中解析SQL语句的函数parseSql没有对SQL语句进行过滤,使用不当可导致SQL注入.(哈哈,其实用再安全的框架使用不当都可能造成SQLi) 函数: ...