Python机器学习(1):KMeans聚类
Python进行KMeans聚类是比较简单的,首先需要import numpy,从sklearn.cluster中import KMeans模块:
import numpy as np
from sklearn.cluster import KMeans
然后读取txt文件,获取相应的数据并转换成numpy array:
X = []
f = open('rktj4.txt')
for v in f:
regex = re.compile('\s+')
X.append([float(regex.split(v)[3]), float(regex.split(v)[6])]) X = np.array(X)
设置类的数量,并聚类:
n_clusters = 5
cls = KMeans(n_clusters).fit(X)
完整代码:
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import re X = []
f = open('rktj4.txt')
for v in f:
regex = re.compile('\s+')
X.append([float(regex.split(v)[3]), float(regex.split(v)[6])]) X = np.array(X) n_clusters = 5
cls = KMeans(n_clusters).fit(X)
cls.labels_ markers = ['^','x','o','*','+']
for i in range(n_clusters):
members = cls.labels_ == i
plt.scatter(X[members, 0], X[members, 1], s=60, marker=markers[i], c='b', alpha=0.5)
print plt.title('')
plt.show()
运行结果:
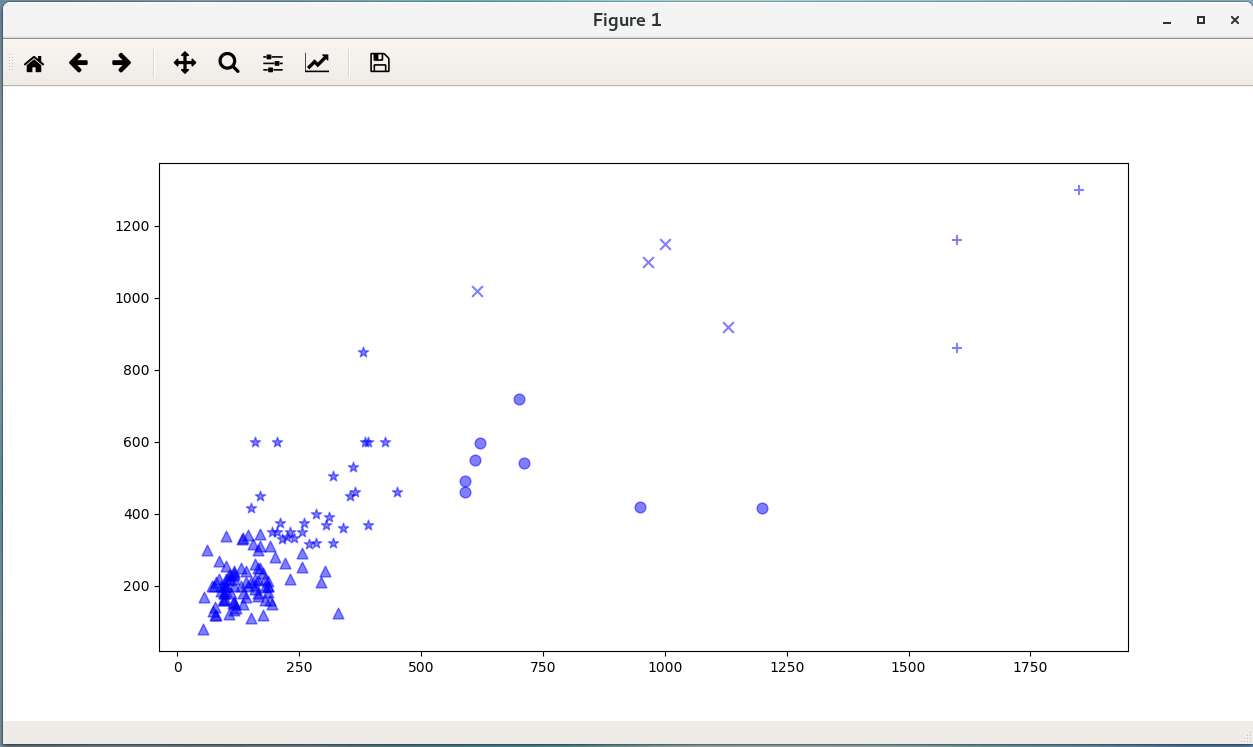
Python机器学习(1):KMeans聚类的更多相关文章
- Python机器学习算法 — K-Means聚类
K-Means简介 步,直到每个簇的中心基本不再变化: 6)将结果输出. K-Means的说明 如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示: (a)刚开始时是原始数据,杂乱无章 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- 【Python机器学习实战】聚类算法(1)——K-Means聚类
实战部分主要针对某一具体算法对其原理进行较为详细的介绍,然后进行简单地实现(可能对算法性能考虑欠缺),这一部分主要介绍一些常见的一些聚类算法. K-means聚类算法 0.聚类算法算法简介 聚类算法算 ...
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 菜鸟之路——机器学习之Kmeans聚类个人理解及Python实现
一些概念 相关系数:衡量两组数据相关性 决定系数:(R2值)大概意思就是这个回归方程能解释百分之多少的真实值. Kmeans聚类大致就是选择K个中心点.不断遍历更新中心点的位置.离哪个中心点近就属于哪 ...
- 机器学习算法-K-means聚类
引文: k均值算法是一种聚类算法.所谓聚类.他是一种无监督学习,将类似的对象归到同一个蔟中.蔟内的对象越类似,聚类的效果越好. 聚类和分类最大的不同在于.分类的目标事先已知.而聚类则不一样. 由于其产 ...
- 转载 | Python AI 教学│k-means聚类算法及应用
关注我们的公众号哦!获取更多精彩哦! 1.问题导入 假如有这样一种情况,在一天你想去某个城市旅游,这个城市里你想去的有70个地方,现在你只有每一个地方的地址,这个地址列表很长,有70个位置.事先肯定要 ...
- 【Python机器学习实战】聚类算法(2)——层次聚类(HAC)和DBSCAN
层次聚类和DBSCAN 前面说到K-means聚类算法,K-Means聚类是一种分散性聚类算法,本节主要是基于数据结构的聚类算法--层次聚类和基于密度的聚类算法--DBSCAN两种算法. 1.层次聚类 ...
- 机器学习: K-means 聚类
今天介绍机器学习里常见的一种无监督聚类算法,K-means.我们先来考虑在一个高维空间的一组数据集,S={x1,x2,...,xN}" role="presentation&quo ...
- 机器学习:K-Means聚类算法
本文来自同步博客. 前面几篇文章介绍了回归或分类的几个算法,它们的共同点是训练数据包含了输出结果,要求算法能够通过训练数据掌握规律,用于预测新输入数据的输出值.因此,回归算法或分类算法被称之为监督学习 ...
随机推荐
- 《剑指offer》-前n项和不准用通解和各种判断
题目描述 求1+2+3+...+n,要求不能使用乘除法.for.while.if.else.switch.case等关键字及条件判断语句(A?B:C). 这题目简直没事找事...为啥这么说,因为没有限 ...
- lldp
https://wenku.baidu.com/view/b9d831f26294dd88d0d26b20.html
- Mysql innodb_fast_shutdown
innodb_fast_shutdown有3个值: 默认是1 可选0 1 2 支持全动态局设置 使用场景:在做数据库关闭升级的时候 set global innodb_fast_shutdown=0 ...
- StringBuilder和+来串接字符串,时间的比较
一:程序比较 1.使用+ 2.使用的时间 虽然时间一直在变动,但是仍然可以看到时间在1000ms左右 3.使用StringBuilder 4.使用的时间 虽然时间每次在变化,但是时间在350ms左右变 ...
- 汇编之 eax, ebx, ecx, edx, esi, edi, ebp, esp??
一般寄存器:AX.BX.CX.DXAX:累积暂存器,BX:基底暂存器,CX:计数暂存器,DX:资料暂存器 索引暂存器:SI.DISI:来源索引暂存器,DI:目的索引暂存器 堆叠.基底暂存器:SP.BP ...
- u3d 元件的克隆 Cloning of u3d components
u3d 元件的克隆 Cloning of u3d components 作者:韩梦飞沙 Author:han_meng_fei_sha 邮箱:313134555@qq.com E-mail: 3131 ...
- AGC027 A - Candy Distribution Again
目录 题目链接 题解 代码 题目链接 AGC027 A - Candy Distribution Again 题解 贪心即可 代码 #include<cstdio> #include< ...
- BZOJ.1070.[SCOI2007]修车(费用流SPFA)
题目链接 /* 神tm看错题*2.. 假如人员i依次维修W1,W2,...,Wn,那么花费的时间是 W1 + W1+W2 + W1+W2+W3... = W1*n + W2*(n-1) + ... + ...
- 潭州课堂25班:Ph201805201 爬虫基础 第五课 (案例) 豆瓣分析 (课堂笔记)
动态讲求 , 翻页参数: # -*- coding: utf-8 -*- # 斌彬电脑 # @Time : 2018/9/1 0001 3:44 import requests,json class ...
- Flask的使用2
1.Flask文件的配置 # 方式一: # 直接书写 app.config['SESSION_COOKIE_NAME'] = 'session_lvning' # 方式二: #引入setting.py ...