K-means聚类算法及python代码实现
K-means聚类算法(事先数据并没有类别之分!所有的数据都是一样的)
1、概述
K-means算法是集简单和经典于一身的基于距离的聚类算法
采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。
该算法认为类簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
2、核心思想
通过迭代寻找k个类簇的一种划分方案,使得用这k个类簇的均值来代表相应各类样本时所得的总体误差最小。
k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
k-means算法的基础是最小误差平方和准则,
其代价函数是:

式中,μc(i)表示第i个聚类的均值。
各类簇内的样本越相似,其与该类均值间的误差平方越小,对所有类所得到的误差平方求和,即可验证分为k类时,各聚类是否是最优的。
上式的代价函数无法用解析的方法最小化,只能有迭代的方法。
3、算法步骤图解
下图展示了对n个样本点进行K-means聚类的效果,这里k取2。

4、算法实现步骤
k-means算法是将样本聚类成 k个簇(cluster),其中k是用户给定的,其求解过程非常直观简单,具体算法描述如下:
1) 随机选取 k个聚类质心点
2) 重复下面过程直到收敛 {
对于每一个样例 i,计算其应该属于的类:

对于每一个类 j,重新计算该类的质心:

}
其伪代码如下:
******************************************************************************
创建k个点作为初始的质心点(随机选择)
当任意一个点的簇分配结果发生改变时
对数据集中的每一个数据点
对每一个质心
计算质心与数据点的距离
将数据点分配到距离最近的簇
对每一个簇,计算簇中所有点的均值,并将均值作为质心
********************************************************
5、K-means聚类算法python实战
需求:
对给定的数据集进行聚类
本案例采用二维数据集,共80个样本,有4个类。

#!/usr/bin/python
# coding=utf-8
from numpy import *
# 加载数据
def loadDataSet(fileName): # 解析文件,按tab分割字段,得到一个浮点数字类型的矩阵
dataMat = [] # 文件的最后一个字段是类别标签
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float, curLine) # 将每个元素转成float类型
dataMat.append(fltLine)
return dataMat # 计算欧几里得距离
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) # 求两个向量之间的距离 # 构建聚簇中心,取k个(此例中为4)随机质心
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n))) # 每个质心有n个坐标值,总共要k个质心
for j in range(n):
minJ = min(dataSet[:,j])
maxJ = max(dataSet[:,j])
rangeJ = float(maxJ - minJ)
centroids[:,j] = minJ + rangeJ * random.rand(k, 1)
return centroids # k-means 聚类算法
def kMeans(dataSet, k, distMeans =distEclud, createCent = randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2))) # 用于存放该样本属于哪类及质心距离
# clusterAssment第一列存放该数据所属的中心点,第二列是该数据到中心点的距离
centroids = createCent(dataSet, k)
clusterChanged = True # 用来判断聚类是否已经收敛
while clusterChanged:
clusterChanged = False;
for i in range(m): # 把每一个数据点划分到离它最近的中心点
minDist = inf; minIndex = -1;
for j in range(k):
distJI = distMeans(centroids[j,:], dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j # 如果第i个数据点到第j个中心点更近,则将i归属为j
if clusterAssment[i,0] != minIndex: clusterChanged = True; # 如果分配发生变化,则需要继续迭代
clusterAssment[i,:] = minIndex,minDist**2 # 并将第i个数据点的分配情况存入字典
print centroids
for cent in range(k): # 重新计算中心点
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A == cent)[0]] # 去第一列等于cent的所有列
centroids[cent,:] = mean(ptsInClust, axis = 0) # 算出这些数据的中心点
return centroids, clusterAssment
# --------------------测试----------------------------------------------------
# 用测试数据及测试kmeans算法
datMat = mat(loadDataSet('testSet.txt'))
myCentroids,clustAssing = kMeans(datMat,4)
print myCentroids
print clustAssing
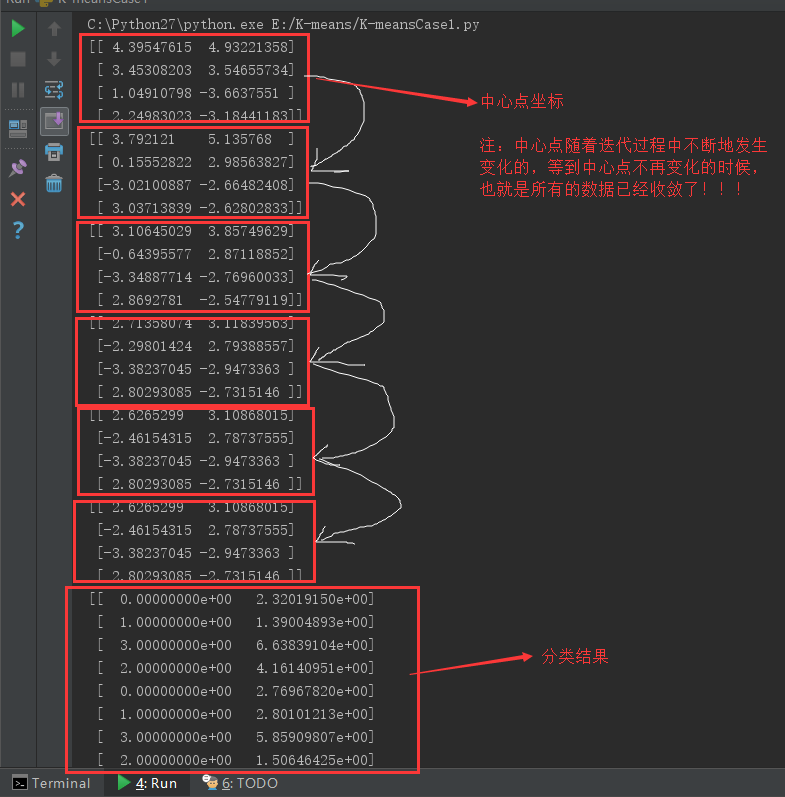
运行结果:
6、K-means算法补充
K-means算法的缺点及改进方法
(1)k值的选择是用户指定的,不同的k得到的结果会有挺大的不同,如下图所示,左边是k=3的结果,这个就太稀疏了,蓝色的那个簇其实是可以再划分成两个簇的。而右图是k=5的结果,可以看到红色菱形和蓝色菱形这两个簇应该是可以合并成一个簇的:
改进:
对k的选择可以先用一些算法分析数据的分布,如重心和密度等,然后选择合适的k
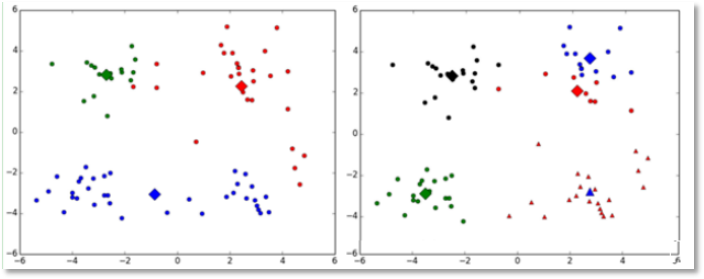
(2)对k个初始质心的选择比较敏感,容易陷入局部最小值。例如,我们上面的算法运行的时候,有可能会得到不同的结果,如下面这两种情况。K-means也是收敛了,只是收敛到了局部最小值:
改进:
有人提出了另一个成为二分k均值(bisecting k-means)算法,它对初始的k个质心的选择就不太敏感

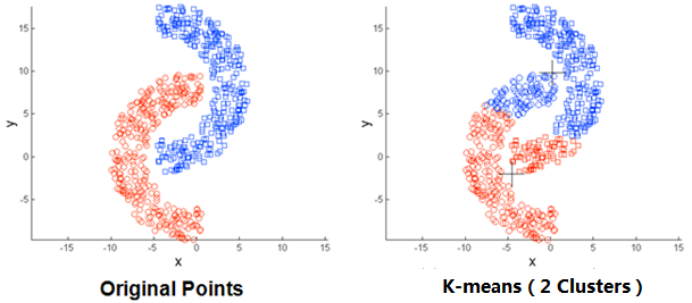
(3)存在局限性,如下面这种非球状的数据分布就搞不定了:
(4)数据集比较大的时候,收敛会比较慢。
K-means聚类算法及python代码实现的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- 数据关联分析 association analysis (Aprior算法,python代码)
1基本概念 购物篮事务(market basket transaction),如下表,表中每一行对应一个事务,包含唯一标识TID,和购买的商品集合.本文介绍一种成为关联分析(association a ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 密度峰值聚类算法原理+python实现
密度峰值聚类(Density peaks clustering, DPC)来自Science上Clustering by fast search and find of density peaks ...
- KNN分类算法及python代码实现
KNN分类算法(先验数据中就有类别之分,未知的数据会被归类为之前类别中的某一类!) 1.KNN介绍 K最近邻(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法. 机器学习, ...
- 决策树分类算法及python代码实现案例
决策树分类算法 1.概述 决策树(decision tree)——是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现 ...
随机推荐
- C# 面向对象的base的使用
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace Cons ...
- android 使用get和post将数据提交到服务器
1.activity_main.xml <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android& ...
- [C++]栈区(栈)与堆区(类链表)[转/摘]
一.预备知识—程序的内存分配 一个由C/C++编译的程序占用的内存分为以下几个部分 1.栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等.其 操 ...
- Flask最强攻略 - 跟DragonFire学Flask - 第七篇 Flask 中路由系统
Flask中的路由系统其实我们并不陌生了,从一开始到现在都一直在应用 @app.route("/",methods=["GET","POST" ...
- solr学习
入门文档 http://www.cnblogs.com/edwinchen/p/3972904.html 中文分词 https://github.com/EugenePig/ik-analyzer-s ...
- 计算正多边形的面积 Gym - 101840G
http://codeforces.com/gym/101840/attachments 题目大意:输入n,r,k .n代表往外扩张几次,r代表圆的内接圆半径,k代表多边形的边长.问你每次扩张多边形和 ...
- commons-lang3-3.2.jar中的常用工具类的使用
这个包中的很多工具类可以简化我们的操作,在这里简单的研究其中的几个工具类的使用. 1.StringUtils工具类 可以判断是否是空串,是否为null,默认值设置等操作: /** * StringUt ...
- 带事件的Bootstrap模态框的使用2
模态框中显示一些基本的数据以及触发一些基本的JS函数 <%@ page language="java" contentType="text/html; charse ...
- LinkedList源码分析笔记(jdk1.8)
1.特点 LinkedList的底层实现是由一个双向链表实现的,可以从两端作为头节点遍历链表. 允许元素为null 线程不安全 增删相对ArrayList快,改查相对ArrayList慢(curd都会 ...
- as 插件GsonFormat用法(json字符串快速生成javabean)
GsonFormat 主要用于使用Gson库将JSONObject格式的String 解析成实体,该插件可以加快开发进度,使用非常方便,效率高. 插件地址:https://plugins.jetbra ...