Llama2-Chinese项目:2.3-预训练使用QA还是Text数据集?
Llama2-Chinese项目给出pretrain的data为QA数据格式,可能会有疑问pretrain不应该是Text数据格式吗?而在Chinese-LLaMA-Alpaca-2和open-llama2预训练使用的LoRA技术,给出pretrain的data为Text数据格式。所以推测应该pretrain时QA和Text数据格式都应该支持。然后马上就会有一个疑问,两者有什么区别呢?再回答这个问题之前,先来看看Llama2-Chinese和open-llama2是如何处理QA和Text数据的。
一.Llama2-Chineses是如何处理QA数据格式的?
1.raw_datasets数据
首先使用raw_datasets = load_dataset()加载原始数据,如下所示:
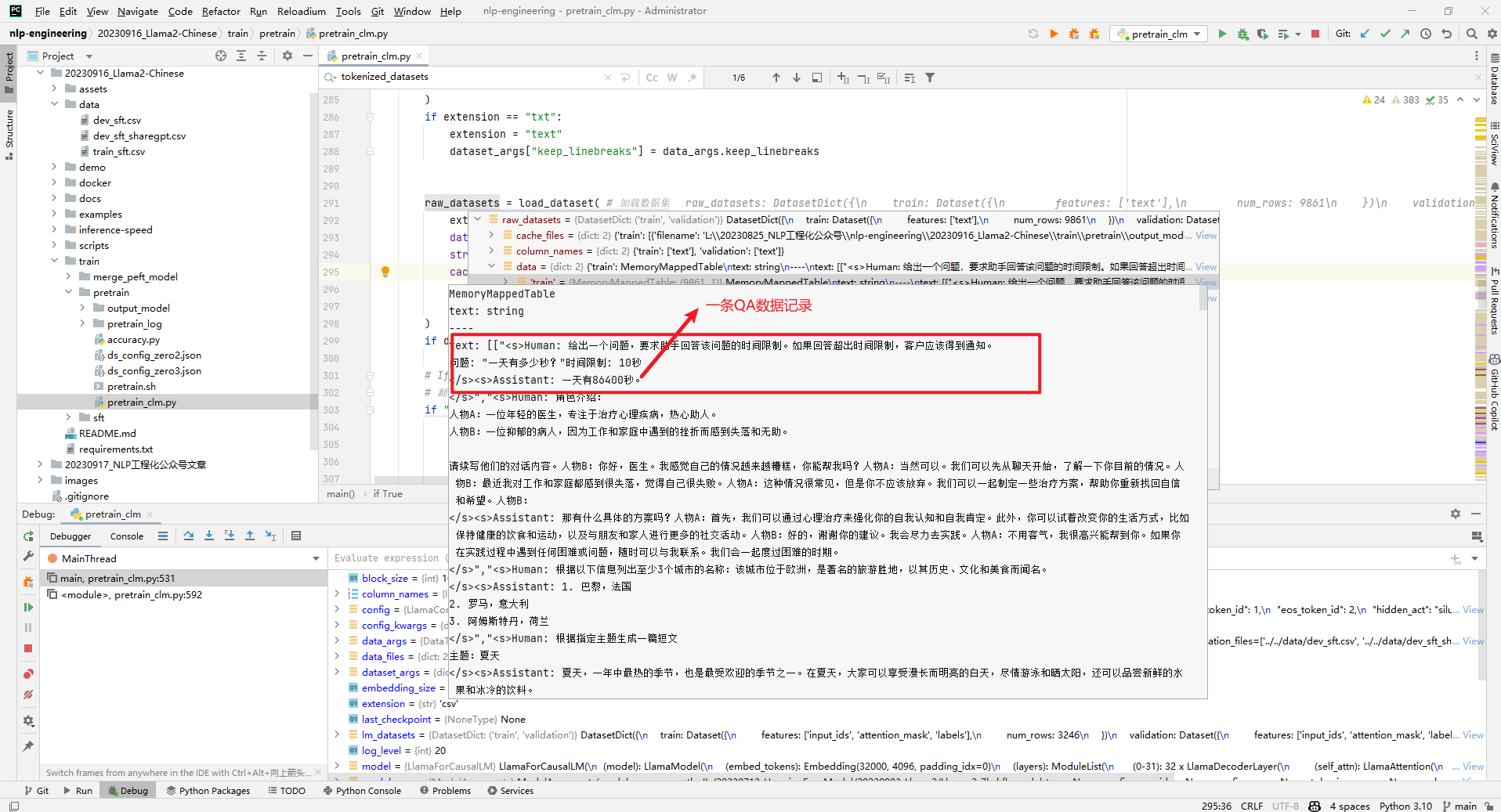
然后通过tokenize_function分词函数对raw_datasets进行处理,如下所示:
def tokenize_function(examples): # 分词函数
with CaptureLogger(tok_logger) as cl: # 捕获日志记录器
output = tokenizer( [ '<s>'+item+'</s>' for item in examples[text_column_name]]) # 分词
return output # 输出
对应的控制台输出日志,如下所示:
Running tokenizer on dataset: 0%| | 0/9861 [00:00<?, ? examples/s]Caching processed dataset at L:\20230825_NLP工程化公众号\nlp-engineering\20230916_Llama2-Chinese\train\pretrain\output_model\dataset_cache\csv\default-0be939ed6ae746cd\0.0.0\eea64c71ca8b46dd3f537ed218fc9bf495d5707789152eb2764f5c78fa66d59d\cache-5995c58fe2972c10.arrow
09/20/2023 21:52:13 - INFO - datasets.arrow_dataset - Caching processed dataset at L:\20230825_NLP工程化公众号\nlp-engineering\20230916_Llama2-Chinese\train\pretrain\output_model\dataset_cache\csv\default-0be939ed6ae746cd\0.0.0\eea64c71ca8b46dd3f537ed218fc9bf495d5707789152eb2764f5c78fa66d59d\cache-5995c58fe2972c10.arrow
Running tokenizer on dataset: 100%|██████████| 9861/9861 [00:11<00:00, 886.04 examples/s]
Running tokenizer on dataset: 0%| | 0/400 [00:00<?, ? examples/s]Caching processed dataset at L:\20230825_NLP工程化公众号\nlp-engineering\20230916_Llama2-Chinese\train\pretrain\output_model\dataset_cache\csv\default-0be939ed6ae746cd\0.0.0\eea64c71ca8b46dd3f537ed218fc9bf495d5707789152eb2764f5c78fa66d59d\cache-44181180d09c5991.arrow
09/20/2023 21:52:21 - INFO - datasets.arrow_dataset - Caching processed dataset at L:\20230825_NLP工程化公众号\nlp-engineering\20230916_Llama2-Chinese\train\pretrain\output_model\dataset_cache\csv\default-0be939ed6ae746cd\0.0.0\eea64c71ca8b46dd3f537ed218fc9bf495d5707789152eb2764f5c78fa66d59d\cache-44181180d09c5991.arrow
Running tokenizer on dataset: 100%|██████████| 400/400 [00:01<00:00, 251.86 examples/s]
2.tokenized_datasets数据
然后tokenized_datasets = raw_datasets.map()如下所示:
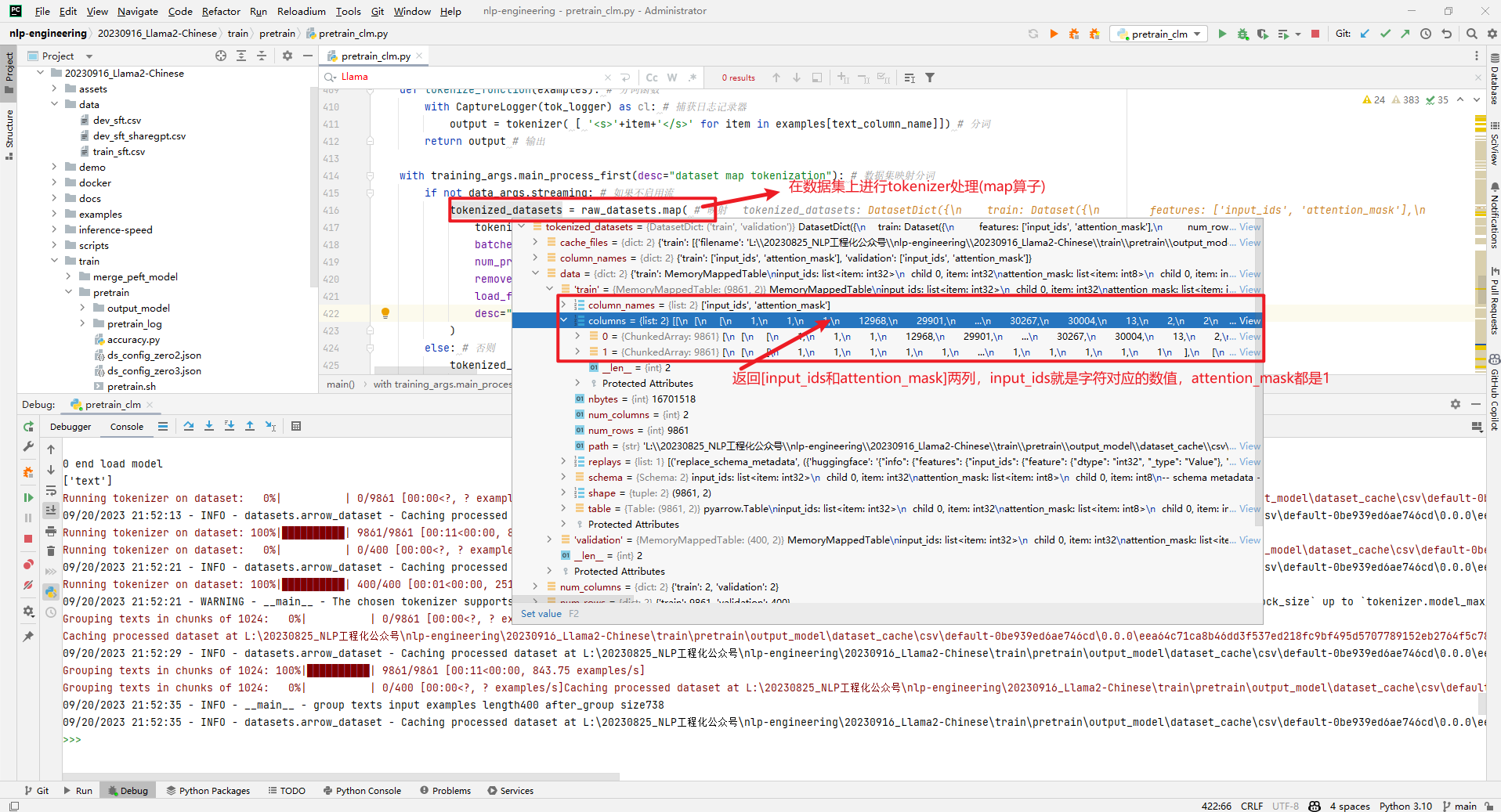
可以看到tokenized_datasets主要是包含['input_ids', 'attention_mask']这2列数据,拿出其中1条如下所示:
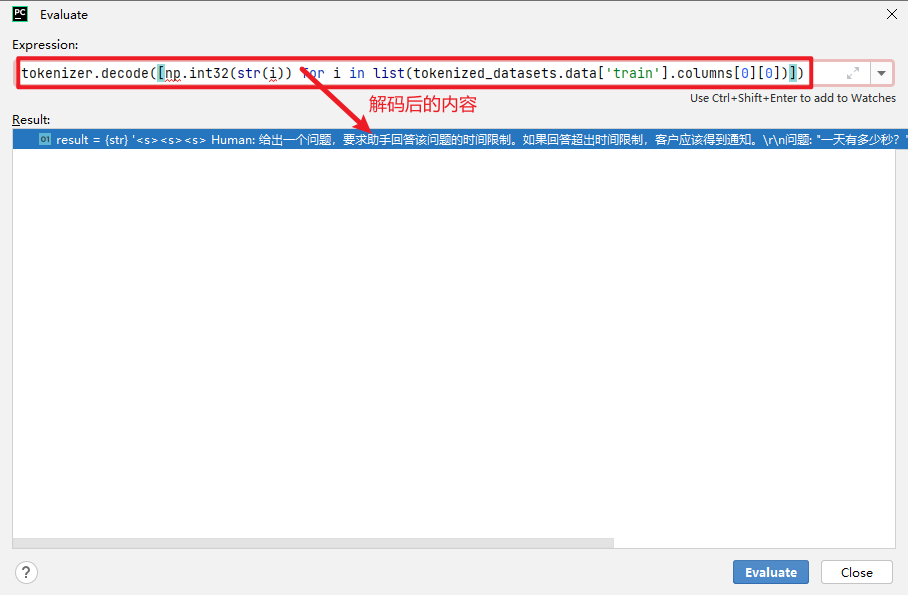
'input_ids':[1, 1, 1, 12968, 29901, 29871, 31999, 30544, 30287, 30502, 31658, 31596, 30214, 30698, 31376, 31931, 30880, 30742, 234, 176, 151, 31751, 31658, 31596, 30210, 30594, 31016, 31175, 31072, 30267, 30847, 30801, 30742, 234, 176, 151, 31480, 30544, 30594, 31016, 31175, 31072, 30214, 31915, 31229, 31370, 31751, 31050, 30780, 30768, 31043, 30267, 30004, 13, 31658, 31596, 29901, 376, 30287, 30408, 30417, 30923, 31022, 234, 170, 149, 30882, 29908, 30594, 31016, 31175, 31072, 29901, 29871, 29896, 29900, 234, 170, 149, 30004, 13, 2, 1, 4007, 22137, 29901, 29871, 30287, 30408, 30417, 29947, 29953, 29946, 29900, 29900, 234, 170, 149, 30267, 30004, 13, 2, 2]
# 'input_ids':'<s><s><s> Human: 给出一个问题,要求助手回答该问题的时间限制。如果回答超出时间限制,客户应该得到通知。问题: "一天有多少秒?"时间限制: 10秒</s><s> Assistant: 一天有86400秒。</s></s>'
'attention_mask':[1, 1, 1, 1, 1, ... 1, 1, 1, 1, 1]
3.lm_datasets数据
接下来得到lm_datasets = tokenized_datasets.map(),其中group_text()函数如下所示:
def group_texts(examples):
# 翻译:连接所有文本。
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()} # 连接所有文本
# concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]]) # 总长度
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can customize this part to your needs.
# 翻译:我们丢弃了小的余数,如果模型支持,我们可以添加填充,而不是这个丢弃,您可以根据需要自定义这部分。
if total_length >= block_size: # 如果总长度大于块大小
total_length = (total_length // block_size) * block_size # 总长度
# Split by chunks of max_len.
# 翻译:按max_len分割。
result = { # 结果
k: [t[i : i + block_size] for i in range(0, total_length, block_size)] # 拼接的示例
for k, t in concatenated_examples.items() # 拼接的示例
}
# print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
logger.info("group texts input examples length%d after_group size%d"%(len(examples['input_ids']),len(result["input_ids"]))) # 组文本输入示例长度%d后组大小%d
result["labels"] = result["input_ids"].copy() # 标签
return result # 返回结果
对应的控制台输出日志,如下所示:
09/20/2023 21:52:21 - WARNING - __main__ - The chosen tokenizer supports a `model_max_length` that is longer than the default `block_size` value of 1024. If you would like to use a longer `block_size` up to `tokenizer.model_max_length` you can override this default with `--block_size xxx`.
Grouping texts in chunks of 1024: 0%| | 0/9861 [00:00<?, ? examples/s]09/20/2023 21:52:29 - INFO - __main__ - group texts input examples length9861 after_group size3246
Caching processed dataset at L:\20230825_NLP工程化公众号\nlp-engineering\20230916_Llama2-Chinese\train\pretrain\output_model\dataset_cache\csv\default-0be939ed6ae746cd\0.0.0\eea64c71ca8b46dd3f537ed218fc9bf495d5707789152eb2764f5c78fa66d59d\cache-18dbcb518f2766e1.arrow
09/20/2023 21:52:29 - INFO - datasets.arrow_dataset - Caching processed dataset at L:\20230825_NLP工程化公众号\nlp-engineering\20230916_Llama2-Chinese\train\pretrain\output_model\dataset_cache\csv\default-0be939ed6ae746cd\0.0.0\eea64c71ca8b46dd3f537ed218fc9bf495d5707789152eb2764f5c78fa66d59d\cache-18dbcb518f2766e1.arrow
Grouping texts in chunks of 1024: 100%|██████████| 9861/9861 [00:11<00:00, 843.75 examples/s]
Grouping texts in chunks of 1024: 0%| | 0/400 [00:00<?, ? examples/s]Caching processed dataset at L:\20230825_NLP工程化公众号\nlp-engineering\20230916_Llama2-Chinese\train\pretrain\output_model\dataset_cache\csv\default-0be939ed6ae746cd\0.0.0\eea64c71ca8b46dd3f537ed218fc9bf495d5707789152eb2764f5c78fa66d59d\cache-962b32747bcb1aec.arrow
09/20/2023 21:52:35 - INFO - __main__ - group texts input examples length400 after_group size738
09/20/2023 21:52:35 - INFO - datasets.arrow_dataset - Caching processed dataset at L:\20230825_NLP工程化公众号\nlp-engineering\20230916_Llama2-Chinese\train\pretrain\output_model\dataset_cache\csv\default-0be939ed6ae746cd\0.0.0\eea64c71ca8b46dd3f537ed218fc9bf495d5707789152eb2764f5c78fa66d59d\cache-962b32747bcb1aec.arrow
Grouping texts in chunks of 1024: 100%|██████████| 400/400 [00:02<00:00, 153.36 examples/s]
lm_datasets的列名包括['input_ids', 'attention_mask', 'labels'],如下所示:
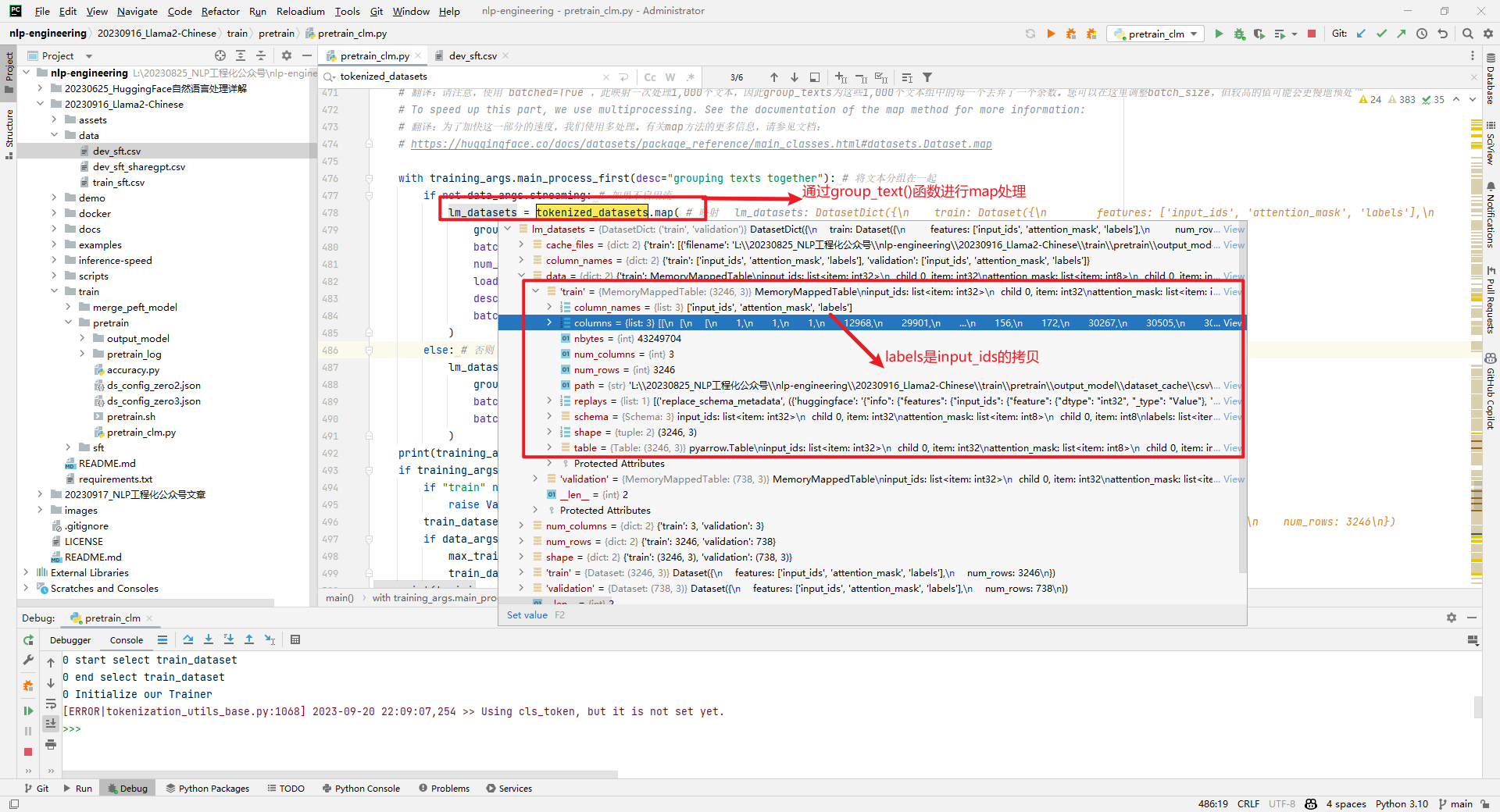
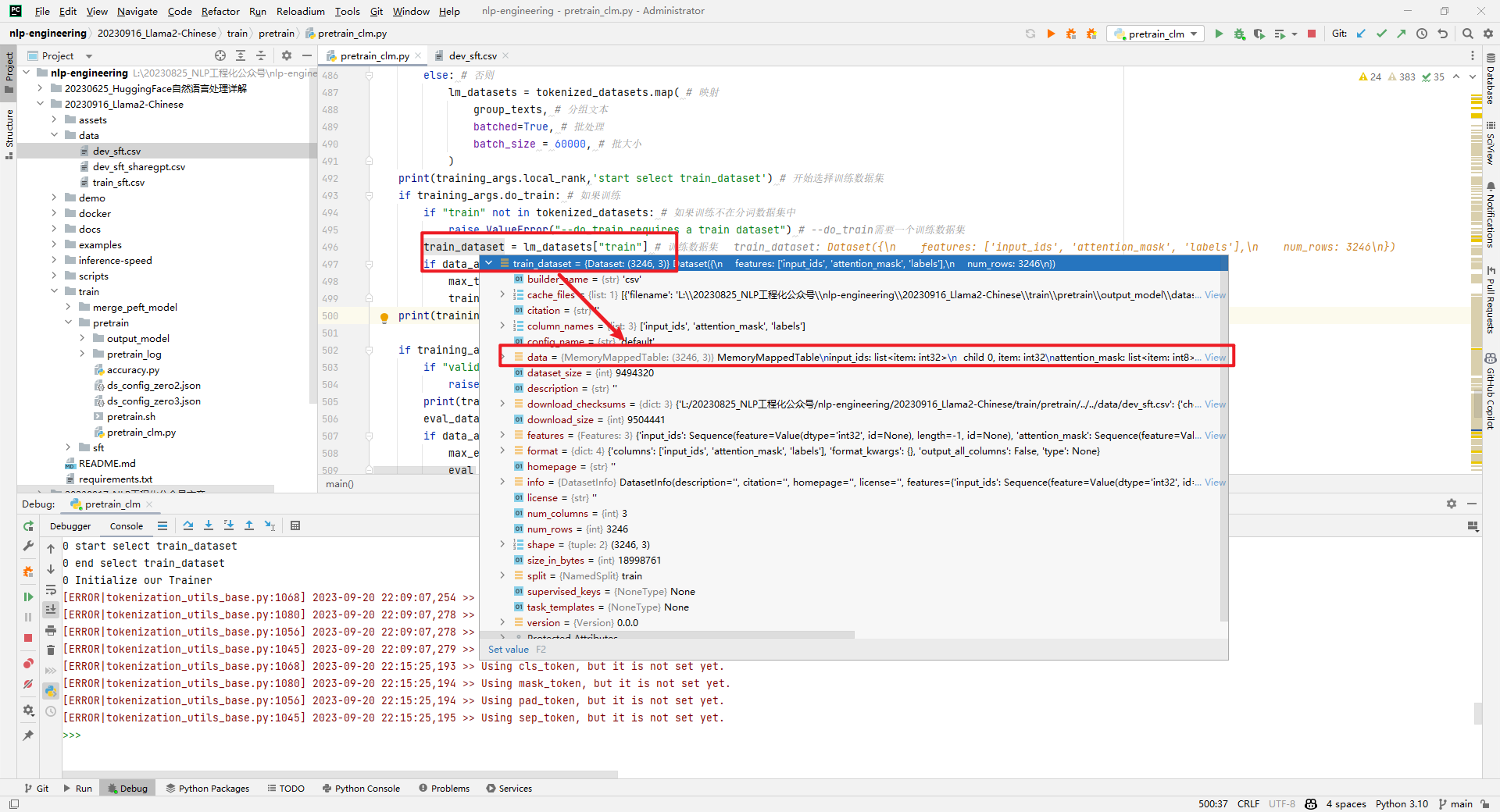
train_dataset就是lm_datasets中train的部分,如下所示:
4.定义训练器Trainer训练模型
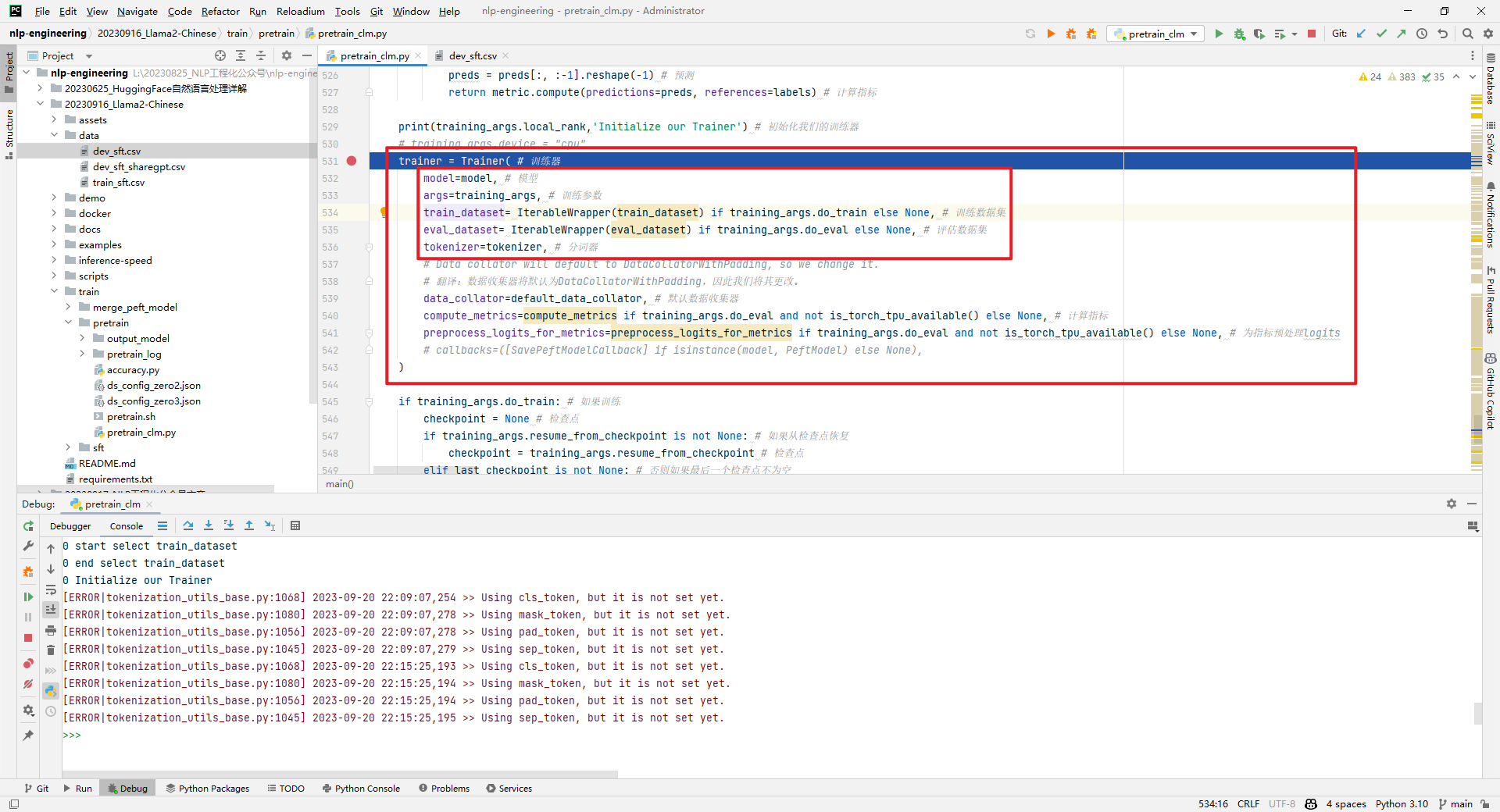
通过trainer.train(resume_from_checkpoint=checkpoint)训练模型,如下所示:
二.open-llama2是如何处理Text数据格式的?
1.raw_dataset数据
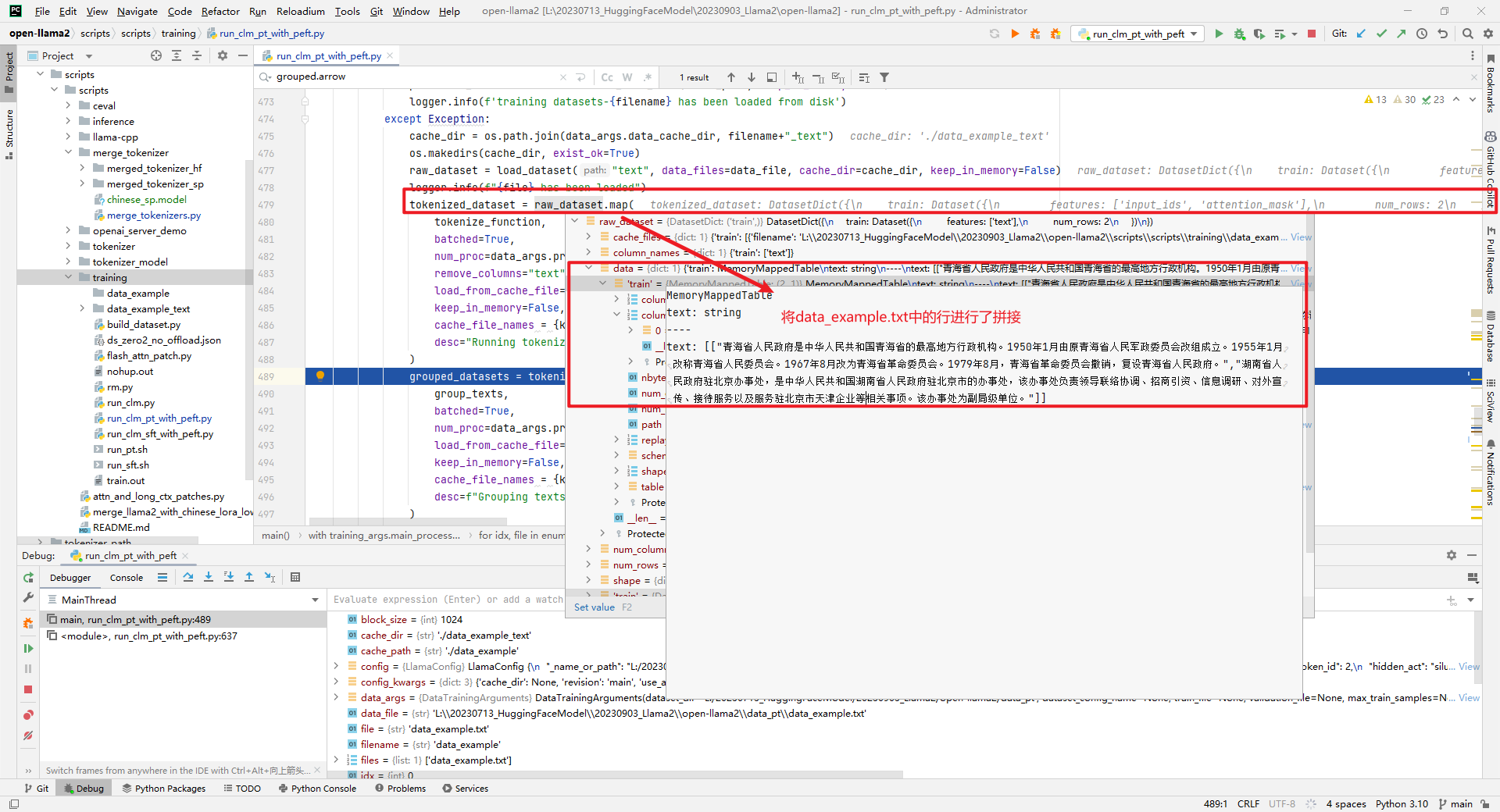
raw_dataset = load_dataset("text", data_files=data_file, cache_dir=cache_dir, keep_in_memory=False)加载预训练数据,如下所示:
2.tokenized_dataset数据
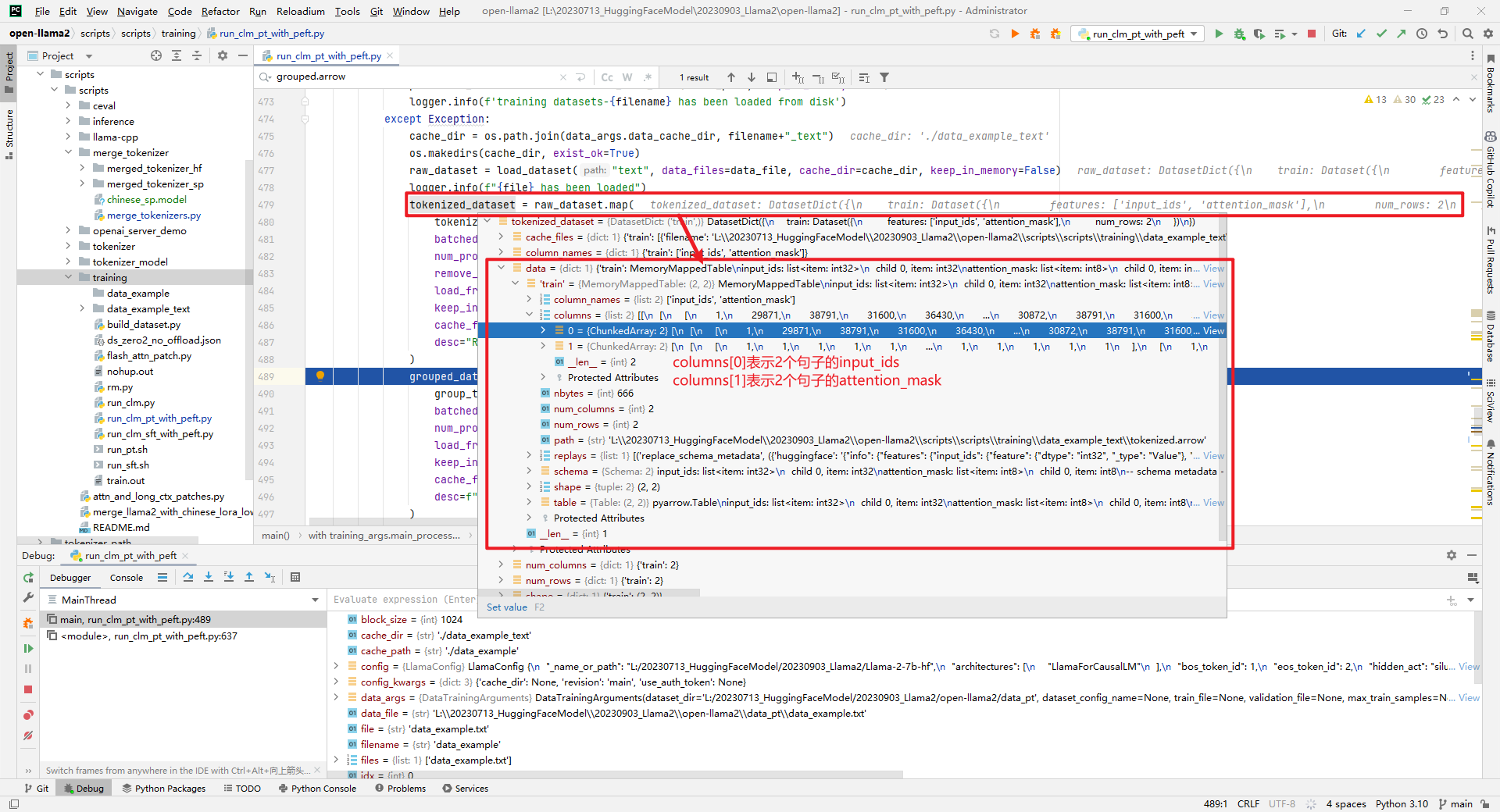
对raw_dataset进行text转id处理,如下所示:
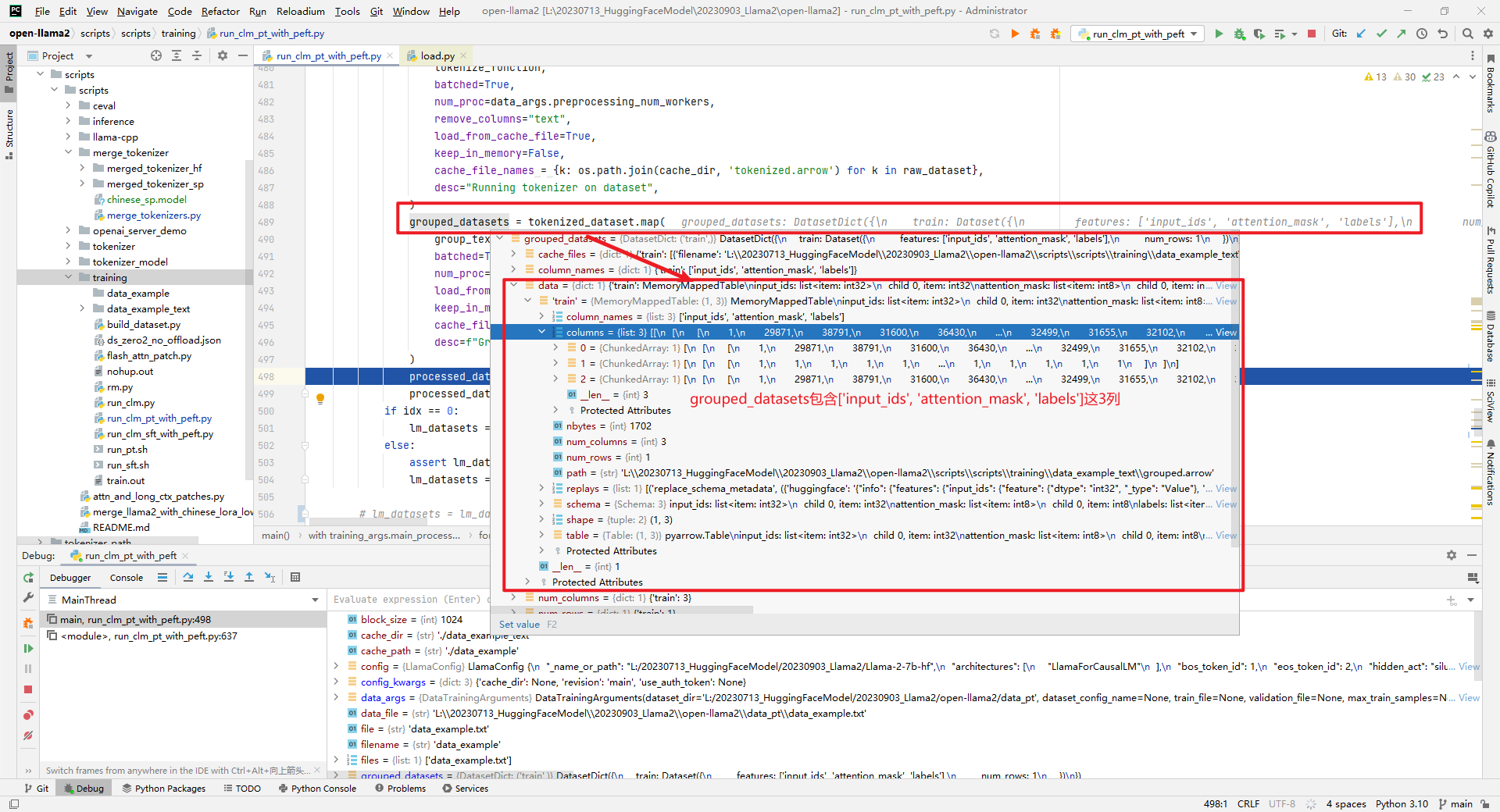
3.grouped_datasets和processed_dataset数据
这两者包含['input_ids', 'attention_mask', 'labels']三列数据,并且processed_dataset = grouped_datasets。如下所示:
4.lm_datasets数据
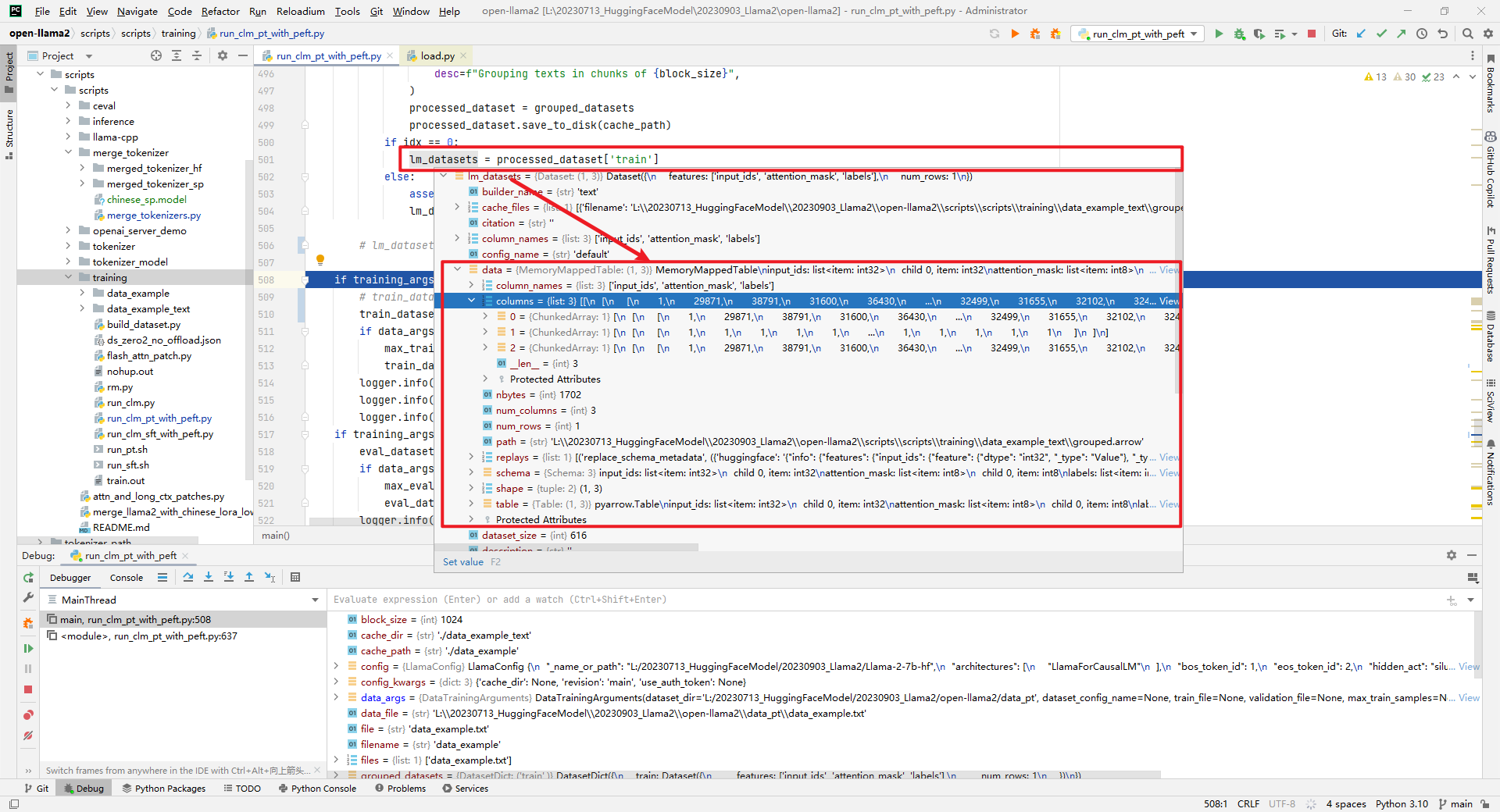
lm_datasets = processed_dataset['train'],如下所示:
通过tokenizer.decode(train_dataset[0]['input_ids'])对数据进行解码,如下所示:
<s> 青海省人民政府是中华人民共和国青海省的最高地方行政机构。1950年1月由原青海省人民军政委员会改组成立。1955年1月改称青海省人民委员会。1967年8月改为青海省革命委员会。1979年8月,青海省革命委员会撤销,复设青海省人民政府。<s>湖南省人民政府驻北京办事处,是中华人民共和国湖南省人民政府驻北京市的办事处,该办事处负责领导联络协调、招商引资、信息调研、对外宣传、接待服务以及服务驻北京市天津企业等相关事项。该办事处为副局级单位。
综上所述,加载QA数据时,train_dataset的shape为[3246, 3],而加载Text数据时,train_dataset的shape为[1, 3],可见前者是按照逐行处理的,而后者是合并后处理的。最后思考最开始的那个疑问,两者有什么区别呢?从数据处理上来说,无论是QA还是Text数据格式,都是把它们当做Text数据处理的。看似没有区别,实际上LLM有着强大的模式识别能力,从QA数据集上是可以识别到问答模式的,尽管做的都是无监督学习,没有明确的特征X和标签y。问了下ChatGPT增量训练使用QA数据集和Text数据集间的区别,如下所示:
| 特征 | QA 数据集增量训练 | Text 数据集增量训练 |
|---|---|---|
| 数据格式 | 问题和答案对的形式 | 连续的文本段落、句子或单词序列 |
| 目标任务 | 提高问题回答性能 | 提高文本理解和生成性能 |
| 数据内容 | 问题和答案对,通常领域特定 | 通常为通用文本,如新闻文章、小说等 |
| 数据预处理 | 问题和答案的提取、分词、标记化等 | 文本清理、标记化、分段等 |
| 应用示例 | 问答、领域特定任务 | 文本生成、文章摘要、翻译等 |
这个回答参考下就行了,还是要以场景为导向来思考,比如要训练一个心理咨询机器人,现在已经有了一个LLM的base模型,如果要增量预训练肯定也是在医疗非结构化文本(比如教材、文献等)上预训练,然后拿心理咨询问答数据进行SFT。应该很少会有人直接拿医疗QA数据集来预训练base模型吧,因为标注的成本还是太高了。若有不当之处,欢迎拍砖。
参考文献:
[1]https://github.com/FlagAlpha/Llama2-Chinese
[2]https://github.com/huxiaosheng123/open-llama2
[3]https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
[4]https://github.com/tatsu-lab/stanford_alpaca
[5]https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py
[6]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/train/pretrain/pretrain_clm.py
Llama2-Chinese项目:2.3-预训练使用QA还是Text数据集?的更多相关文章
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 资源 | TensorFlow推出新工具Seedbank:即刻使用的预训练模型库【转】
本文转载自:http://tech.ifeng.com/a/20180713/45062331_0.shtml 选自TensorFlow 作者:Michael Tyka 机器之心编译 参与:路.王淑婷 ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
- NLP中的预训练语言模型(一)—— ERNIE们和BERT-wwm
随着bert在NLP各种任务上取得骄人的战绩,预训练模型在这不到一年的时间内得到了很大的发展,本系列的文章主要是简单回顾下在bert之后有哪些比较有名的预训练模型,这一期先介绍几个国内开源的预训练模型 ...
- 基于BERT预训练的中文命名实体识别TensorFlow实现
BERT-BiLSMT-CRF-NERTensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuni ...
- LUSE: 无监督数据预训练短文本编码模型
LUSE: 无监督数据预训练短文本编码模型 1 前言 本博文本应写之前立的Flag:基于加密技术编译一个自己的Python解释器,经过半个多月尝试已经成功,但考虑到安全性问题就不公开了,有兴趣的朋友私 ...
- 知识增强的预训练语言模型系列之ERNIE:如何为预训练语言模型注入知识
NLP论文解读 |杨健 论文标题: ERNIE:Enhanced Language Representation with Informative Entities 收录会议:ACL 论文链接: ht ...
- 知识增强的预训练语言模型系列之KEPLER:如何针对上下文和知识图谱联合训练
原创作者 | 杨健 论文标题: KEPLER: A unified model for knowledge embedding and pre-trained language representat ...
- 知识增广的预训练语言模型K-BERT:将知识图谱作为训练语料
原创作者 | 杨健 论文标题: K-BERT: Enabling Language Representation with Knowledge Graph 收录会议: AAAI 论文链接: https ...
- 图神经网络之预训练大模型结合:ERNIESage在链接预测任务应用
1.ERNIESage运行实例介绍(1.8x版本) 本项目原链接:https://aistudio.baidu.com/aistudio/projectdetail/5097085?contribut ...
随机推荐
- 【Azure K8S】AKS升级 Kubernetes version 失败问题的分析与解决
问题描述 创建Azure Kubernetes Service服务后,需要升级AKS集群的 kubernetes version.在AKS页面的 Cluster configuration 页面中,选 ...
- V8是如何执行JavaScript代码的?
前言 一般来讲,电脑是不能直接运行我们的javascript代码的,它需要一个翻译程序将人类能够理解的编程语言 JavaScript,翻译成机器能够理解的机器语言.目前市面上有很多种 JavaScri ...
- ZYNQ 启动过程简介 以及 ZYNQ 裸机生成BOOT.BIN
背景 下图是ZYNQ的启动过程 上电复位等完成后,先执行BootRom,然后再根据MIO设定的启动方式选择对应从哪里启动,无论从哪里启动,都需要一个BOOT.BIN文件,对于裸机程序来说: BOOT. ...
- 现代C++学习指南-类型系统
在前一篇,我们提供了一个方向性的指南,但是学什么,怎么学却没有详细展开.本篇将在前文的基础上,着重介绍下怎样学习C++的类型系统. 写在前面 在进入类型系统之前,我们应该先达成一项共识--尽可能使用C ...
- 3 大数据实战系列-spark shell分析日志
1 准备数据源 文件格式: 访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击URL 数据文件越大越好,至少100万行 2 启动任务 ./spark-sh ...
- 白嫖一个WebAPI限流解决方案
什么是API限流: API 限流是限制用户在一定时间内 API 请求数量的过程.应用程序编程接口 (API) 充当用户和软件应用程序之间的网关.例如,当用户单击社交媒体上的发布按钮时,点击该按钮会触发 ...
- JMH – Java基准测试
官方资源 官方Github样例 应用场景 对要使用的数据结构不确定,不知道谁的性能更好 对历史方法代码重构,要评判改造之后的性能提升多少 (我要做的场景) 想准确地知道某个方法需要执行多长时间,以及执 ...
- Kali Sublist3r 报错解决办法
直接将Sublist3r.py中文件的内容替换为下面的即可 具体的更改的东西改了很多地方就不细说了,直接复制粘贴 如果遇到Error: Virustotal probably now is block ...
- Stable Diffusion AIGC:3步成为P图大师
摘要:instructPix2Pix文字编辑图片是一种纯文本编辑图像的方法,用户提供一张图片和文本编辑指令,告诉模型要做什么,模型根据编辑指令编辑输入的图像,最终输出用户想要的图像. 本文分享自华为云 ...
- 防缓存穿透利器-布隆滤器(BloomFilter)
布隆过滤器 1.布隆过滤器原理 1.1 什么是布隆过滤器 1.2 使用场景 1.3 原理 1.4 布隆过滤器的优缺点 2.实现方式 2.1 初始化skuId的布隆过滤器 2.1.1 RedisCons ...