Python 动态网页Fetch/XHR爬虫——以获取NBA球员信息为例
Python 动态网页Fetch/XHR爬虫——以获取NBA球员信息为例
动态网页抓取信息,一般利用F12开发者工具-网络-Fetch/XHR获取信息,实现难点有:
动态网页的加载方式
获取请求Url
编排处理Headers
分析返回的数据Json
pandas DataFrame的处理
我们本次想获取的信息如下: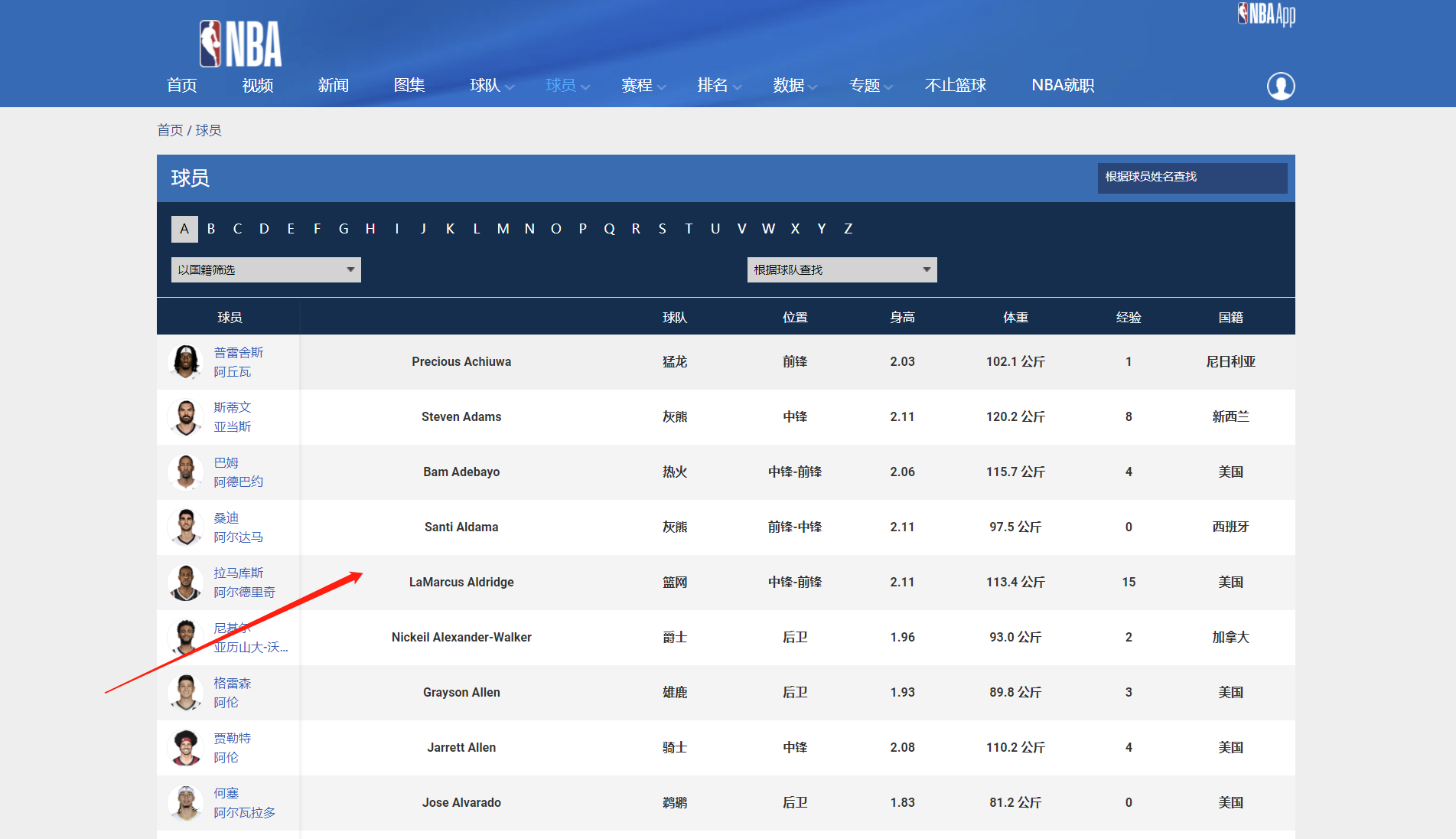
成功获取到的csv一共506位球员,具体如下:
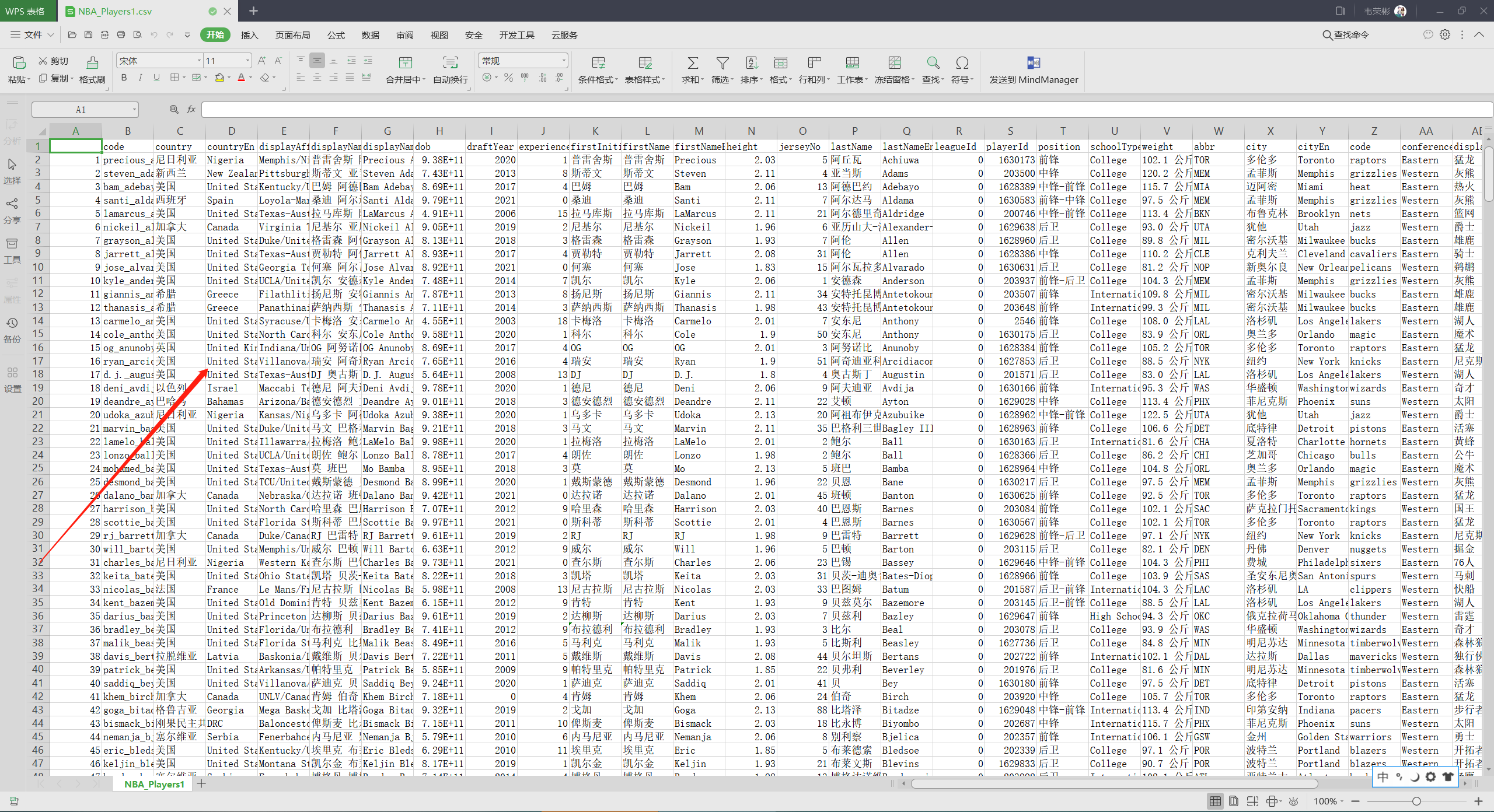
实现代码:
import requests
import pandas as pd
def get_headers(header_raw):
return dict(line.split(": ", 1) for line in header_raw.split("\n") if line != '')
# 设置headers
headers_str = '''
accept: application/json, text/plain, */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
referer: https://china.nba.cn/playerindex/
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
sec-fetch-dest: empty
sec-fetch-mode: cors
sec-fetch-site: same-origin
cookie: sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22182d0029f842fc-0d281a685dd4e08-4303066-2400692-182d0029f85406%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTgyZDAwMjlmODQyZmMtMGQyODFhNjg1ZGQ0ZTA4LTQzMDMwNjYtMjQwMDY5Mi0xODJkMDAyOWY4NTQwNiJ9%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%22182d0029f842fc-0d281a685dd4e08-4303066-2400692-182d0029f85406%22%7D; privacyV2=true; i18next=zh_CN; locale=zh_CN
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36
'''
headers = get_headers(headers_str)
# print(headers)
# requests请求
param = {'locale': 'zh_CN'}
url = 'https://china.nba.cn/stats2/league/playerlist.json'
response = requests.get(url=url, headers=headers, params=param)
print('返回状态码:', response.status_code)
print('编码:', response.encoding)
# json解码成字典
myjson = response.json()
# 保存为pandas DataFrame
# print(players_dicts['playerProfile'])
# print(players_dicts['teamProfile'])
# 遍历选手信息
players_info = []
for players_dicts in myjson['payload']['players']:
players_info.append(pd.DataFrame([players_dicts['playerProfile']]))
# 遍历队伍简介信息
teams_info = []
for players_dicts in myjson['payload']['players']:
teams_info.append(pd.DataFrame([players_dicts['teamProfile']]))
# 得到两个DataFrame
players_pandas = pd.concat(players_info)
teams_pandas = pd.concat(teams_info)
# 合并得到最终DataFrame
result = pd.concat([players_pandas, teams_pandas], axis=1)
result.to_csv(r'C:\Users\WeiRonbbin\Desktop\NBA_Players1.csv')Python 动态网页Fetch/XHR爬虫——以获取NBA球员信息为例的更多相关文章
- Python动态网页爬虫-----动态网页真实地址破解原理
参考链接:Python动态网页爬虫-----动态网页真实地址破解原理
- python动态网页爬取——四六级成绩批量爬取
需求: 四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页. ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- Python 爬虫修养-处理动态网页
Python 爬虫修养-处理动态网页 本文转自:i春秋社区 0x01 前言 在进行爬虫开发的过程中,我们会遇到很多的棘手的问题,当然对于普通的问题比如 UA 等修改的问题,我们并不在讨论范围,既然要将 ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求 selenium模块 selenium模块为 ...
- 在python使用selenium获取动态网页信息并用BeautifulSoup进行解析--动态网页爬虫
爬虫抓取数据时有些数据是动态数据,例如是用js动态加载的,使用普通的urllib2 抓取数据是找不到相关数据的,这是爬虫初学者在使用的过程中,最容易发生的情况,明明在浏览器里有相应的信息,但是在pyt ...
- python网络爬虫-动态网页抓取(五)
动态抓取的实例 在开始爬虫之前,我们需要了解一下Ajax(异步请求).它的价值在于在与后台进行少量的数据交换就可以使网页实现异步更新. 如果使用Ajax加载的动态网页抓取,有两种方法: 通过浏览器审查 ...
- Python爬虫 使用selenium处理动态网页
对于静态网页,使用requests等库可以很方便的得到它的网页源码,然后提取出想要的信息.但是对于动态网页,情况就要复杂很多,这种页面的源码往往只有一个框架,其内容都是由JavaScript渲染出来的 ...
随机推荐
- .net 工具箱不可用/怎样初始化vs环境 解决方案
在开始菜单里面执行的.开始菜单->Microsoft Visual Studio 2005->Visual Studio Tools->Visual Studio 2005 命令提示 ...
- 开发必备,开源 or 免费的 AI 编程助手
AI 大模型的火热,让开发圈近来如虎添翼,各种各样基于 AI 技术的开发者工具和新范式不断涌现,尤其是 Github 和 OpenAI 共同推出的 Copilot X ,更是一骑绝尘.本文推荐一些开源 ...
- 内存池是什么原理?|内存池简易模拟实现|为学习高并发内存池tcmalloc做准备
前言 那么这里博主先安利一些干货满满的专栏了! 这两个都是博主在学习Linux操作系统过程中的记录,希望对大家的学习有帮助! 操作系统Operating Syshttps://blog.csdn.ne ...
- 【算法】C语言程序编程模拟实现strlen函数和strcpy函数
C语言程序编程模拟实现strlen函数和strcpy函数(超详细的注释和解释) 求个赞求个赞求个赞求个赞 谢谢 先赞后看好习惯 打字不容易,这都是很用心做的,希望得到支持你 大家的点赞和支持对于我来说 ...
- 如何基于 spdlog 在编译期提供类 logrus 的日志接口
如何基于 spdlog 在编译期提供类 logrus 的日志接口 实现见 Github,代码简单,只有一个头文件. 前提 几年前看到戈君在知乎上的一篇文章,关于打印日志的一些经验总结: 实践下来很受用 ...
- C语言程序设计之 循环控制2020-10-20
2020-10-20 整理: 第一题: 2011年开始实行新个人所得税法,要求输入月薪salary,输出应交的个人所得税 tax (保留两位小数). 新税法方案如下: tax=rate*(salary ...
- 【.NET】聊聊 IChangeToken 接口
由于两个月的奋战,导致很久没更新了.就是上回老周说的那个产线和机械手搬货的项目,好不容易等到工厂放假了,我就偷偷乐了.当然也过年了,老周先给大伙伴们拜年了,P话不多讲,就祝大家身体健康.生活愉快.其实 ...
- NC201985 立方数
题目链接 题目 题目描述 对于给定的正整数 N,求最大的正整数 A,使得存在正整数 B,满足 \(A^3B=N\) 输入包含 T 组数据,1≤T≤10,000:\(1≤N≤10^{18}\) 输入描述 ...
- NC20154 [JSOI2007]建筑抢修
题目链接 题目 题目描述 小刚在玩JSOI提供的一个称之为"建筑抢修"的电脑游戏:经过了一场激烈的战斗,T部落消灭了所有z部落的入侵者.但是T部落的基地里已经有N个建筑设施受到了严 ...
- python 中异常类型总结
异常类型: 异常名称 描述BaseException 所有异常的基类SystemExit 解释器请求退出KeyboardInterrupt ...