「保姆级」网络爬虫教程(二):教你下载文库中的PDF文档!
如何点赞再看,养成习惯。微信公众号搜索「Job Yan」关注这个爱发技术干货的 Coder。本文 GitHub https://github.com/JobYan/PythonPearls 已收录,还有算法学习、爬虫进阶等资料,以及我的系列文章,欢迎 Star 和完善。
大家好,我是 「Job」。本篇文章是「保姆级」带你入门和进阶网络爬虫系列文章的第二篇,在本篇文章中我会手把手教你:如何下载文库中的 PDF 文档和 PPT 文档。温馨提示,本文字数较多,可能需要阅读较长时间,建议先点赞收藏,防止迷路。
大家好呀,我的文字终于又和大家见面了!上一次和大家见面大概是在 2020 年的 11 月,转眼间两年时间已经过去。这两年里社会上发生了很多重大的事件,我们也经历了很多,尤其是疫情期间,每天都上演着新冠病毒和人类之间发生的“没有硝烟的战争”,在这场战役中涌现出了众多志愿者,他们用自己的弱小的身躯筑起了抗击疫情的厚重城墙。在这段时间里我顺利完成了学业,并且步入了社会,由学生转变为职场人,慢慢地体会到了工作的压力和生活的不易。现在再回头看看之前立下的“长时间更新公众号文章”的小目标好像实现得并不太理想,两年的时间只产出了一篇文章,不知道你还有没有印象当时随手关注的公众号,竟然在自己的关注列表里躺平了2年多的时间。
上次写文档下载程序主要是为了学习爬虫相关的知识,顺便帮助有需要的小伙伴下载一些文档,本着「独乐乐不如众乐乐」的信条,我也将自己写的蹩脚的代码开源了,想着可以帮助一些朋友快速实现文库文档的获取。程序发布一段时间之后,得到了好多小伙伴的使用和认可,好景不长的是文库总是会有一些更新,包括页面的排版、链接的格式等,这些改动往往会导致之前通过正则匹配、选取样式等方式抓取 URL 的方法失效,由于上一版软件长时间未得到维护,最终,它毫无意外地失效了。
后边,我有关注文库的一些反爬策略,但迟迟没有动手编写新版的代码。最近,我想着在工作之余培养自己在爬虫方面的兴趣,顺便帮助有需要的小伙伴,所以又开始对软件进行维护了。
1. 软件是如何使用的?
上一版的软件采用控制台样式,直接在控制台中输入文档的链接,就可以下载文档中包含的图像,图像下载完成后,会将这些图像拼成一个PDF文件,所以最终会得到一组图片和一个PDF文件。程序的使用过程展示如下:
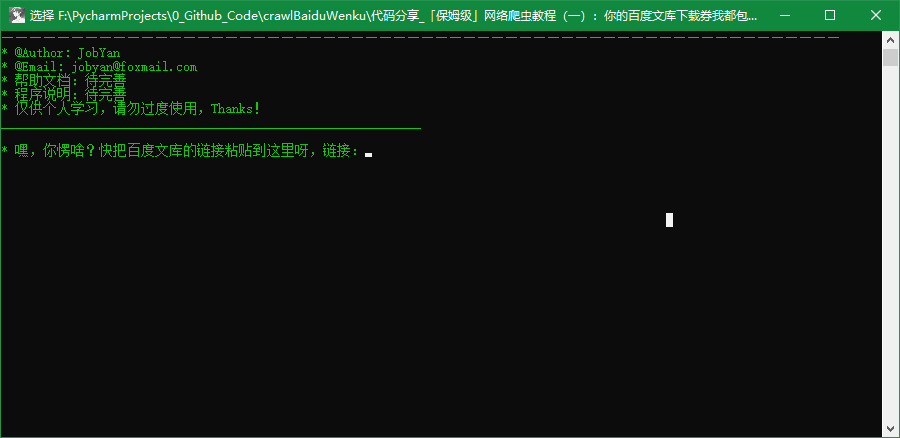
这个没有UI界面的程序使用起来不太友好,在易用上可能会劝退一部分小伙伴。因此,本次对程序进行了升级,首次加上了UI界面,虽然界面比较简陋,但是聊胜于无。在经过一段时间的开发之后,我打算将最近一段时间成果物展示给各位小伙伴,如果大家有文档下载方面需求的话,可以下载软件之后自己尝试一下。
需要说明的是本次开发的软件仅支持 PPT 文件和 PDF 文件的下载,暂不支持 WORD 文件和 TXT 文件的下载。
升级之后,程序的使用过程如下图所示,只需要将文档的链接粘贴到文本框中,点击下载即可得到一组图片和 PDF 文件。当然,这次还贴心的实现了「更改下载文件夹」和「打开下载文件夹」的功能,可以方便的修改保存路径和打开下载路径。
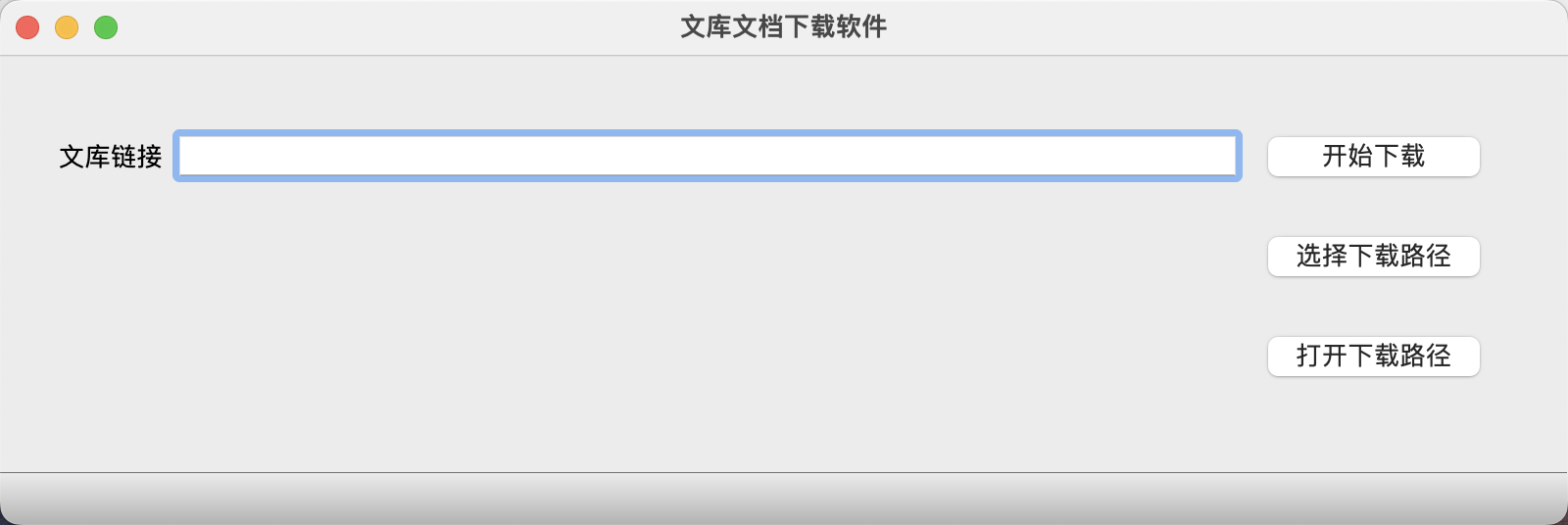
按照以往的惯例,本次的代码依旧会开源,我已经将代码托管在 GitHub 上了,如果有对这方面有兴趣的小伙伴,可以下载源码并进行改进。很希望这个小软件能为你的工作或学习带来一点点的帮助。
2. 软件是如何实现的?
软件实现的思路很简单,这次直接把上次文章中画的流程图拿了过来。
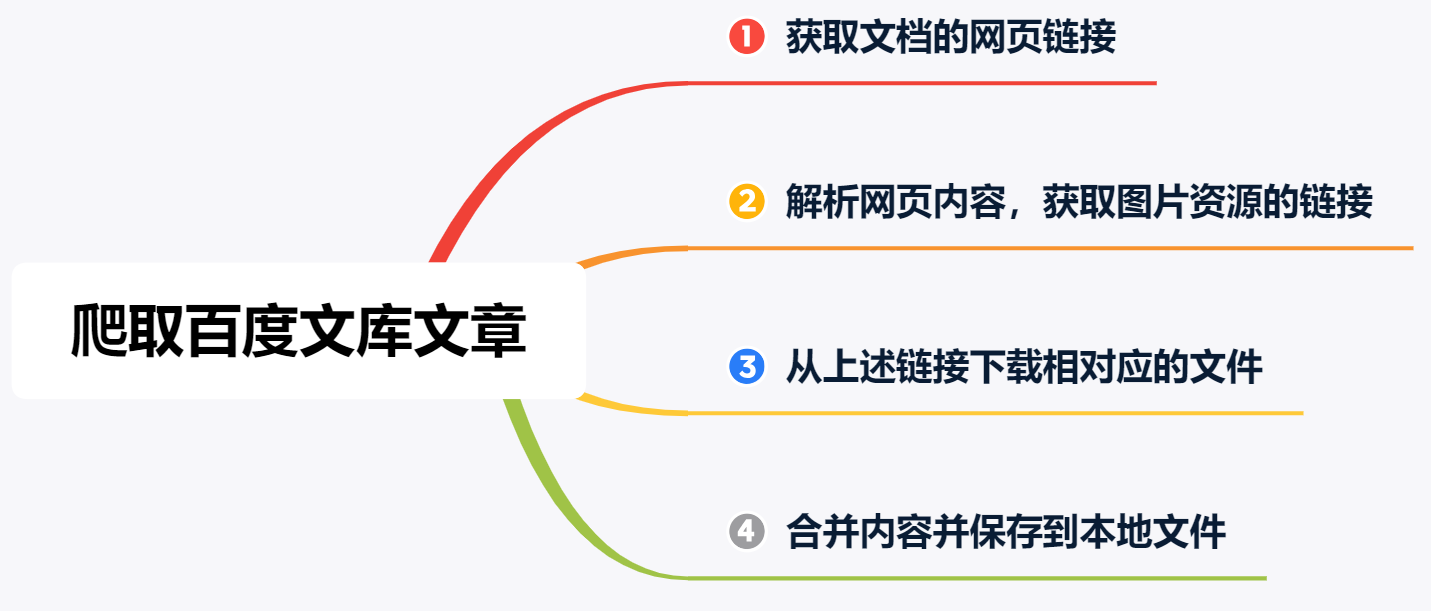
从上图可以看出,总共分为 4 步:
获取文档的网页链接
首先要获取文档的链接,这个链接也就是需要小伙伴们动手获取,并粘贴到文本框中的链接。解析网页内容,获取图片资源的链接
获取文档链接对应的 HTML 文件并利用「正则表达式」或者「Beautiful Soup」对 HTML 内容进行解析,获取到图片资源的链接。从上述链接下载对应的图片文件
对上一步获取到的链接依次进行爬取,并将文件以图片的格式保存到本地。合并内容并保存到本地 PDF 文件
利用 fitz 库将图片文件合并为 PDF 文件。
从上述的流程中可以发现,重点在于第 2 步,即如何从 HTML 文件中获取图片链接是本文要讲解的重点。
上一篇文章中讲解了如何爬取 PPT 文档,有兴趣的小伙伴可以去翻开上一篇文档看一下,本次主要介绍如何爬去 PDF 文档。
2.1 获取 HTML 文件
# 带下载的文档链接
url = "https://wenku.baidu.com/view/e966626f7cd184254b3535d7"
# 构造 header
user_agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
header = {'User-Agent': user_agent}
# 首先访问文库官网,获取cookies,骗过防爬机制
res = requests.get('https://wenku.baidu.com', headers=header)
cookie = res.cookies
# 获取文档链接的网页内容
html_content = requests.get(url, headers=self.header, cookies=cookie).content
2.2 利用正则表达式解析网页内容,获取图片链接
获取到的网页内容如下,为了便于展示,对原网页的内容进行了部分删减。从下面的内容中可以看出,json 和 png 都是按照「页」的格式来填充的。pageIndex 表示页码,后面的 pageLoadUrl 字段为 json 或 png 的链接,如果能获取该链接,就可以获取到 PDF 的文本和图片。
<meta charset="utf-8">\n <title>\xe4\xb8\xad\xe5\x8d\x8e\xe6\xb0\x91\xe5\x9b\xbd\xe5\x9c\xb0\xe5\x9b\xbe\xe9\x9b\x86 - \xe7\x99\xbe\xe5\xba\xa6\xe6\x96\x87\xe5\xba\x93</title>\n
<!-- 此处为json文件信息,json文件中包含PDF中的文字 -->
"json":[{"pageIndex":1,"pageLoadUrl":"https://wkbjcloudbos.bdimg.com/v1/docconvert3273/wk/cbf845cb74352d6a2c27bef96588c94b/0.json?responseContentType=application%2Fjavascript&responseCacheControl=max-age%3D3888000&responseExpires=Wed%2C%2001%20Feb%202023%2016%3A48%3A35%20%2B0800"},{"pageIndex":2,"pageLoadUrl":"https://wkbjcloudbos.bdimg.com/v1/docconvert3273/wk/cbf845cb74352d6a2c27bef96588c94b/0.json?responseContentType=application%2Fjavascript&responseCacheControl=max-age%3D3888000&responseExpires=Wed%2C%2001%20Feb%202023%2016%3A48%3A35%20%2B0800"}]
<!-- 此处为json文件信息,json文件中包含PDF中的图片 -->
"png":[{"pageIndex":1,"pageLoadUrl":"https://wkbjcloudbos.bdimg.com/v1/docconvert3273/wk/cbf845cb74352d6a2c27bef96588c94b/0.png?responseContentType=image%2Fpng&responseCacheControl=max-age%3D3888000&responseExpires=Wed%2C%2001%20Feb%202023%2016%3A48%3A35%20%2B0800"},{"pageIndex":2,"pageLoadUrl":"https://wkbjcloudbos.bdimg.com/v1/docconvert3273/wk/cbf845cb74352d6a2c27bef96588c94b/0.png?responseContentType=image%2Fpng&responseCacheControl=max-age%3D3888000&responseExpires=Wed%2C%2001%20Feb%202023%2016%3A48%3A35%20%2B0800"}]},"freePage":23,"showPage":2,"page":23,"originalPage":23
由于网页上文本的排版较为复杂,如果仅获取文字,也无法较好地还原网页上显示的页面,因此,本软件只是实现了图片文件的获取。针对上述网页内容,通过正则表达式可以快速提取出 png 文件所对应的链接。
links = re.findall("\"png\"\:\[(.*?)\]", html_content.decode('utf-8'))
if links:
self.link_list = re.findall("\"pageIndex\"\:\d+\,\"pageLoadUrl\"\:\"(.*?)\"\}", links[0])
2.3 依次下载图片
利用下面的下载函数,依次把正则表达式提取到的 png 图像链接下载下来。
def download(url, user_agent="wswp", num_retries=2):
# print("Downloading: ", url)
headers = {"User-agent": user_agent}
request = urllib.request.Request(url, headers=headers)
try:
html = urllib.request.urlopen(request)
# print(html.read().decode("utf-8"))
except urllib.error.URLError as e:
# print("Download error: ", e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code <= 600:
# 如果是5xx错误,则进行重试
return download(url, user_agent, num_retries - 1)
return html
2.4 将图片合并为PDF文件
借助 fitz 库的帮助,将下载好的 png 图像合并成一个 PDF 文件。
def export_pdf(self, dir, pdf_name, img_paths):
doc = fitz.open()
for img_path in img_paths:
imgdoc = fitz.open(img_path) # 打开图片
pdfbytes = imgdoc.convert_to_pdf() # 使用图片创建单页的 PDF
imgpdf = fitz.open("pdf", pdfbytes)
doc.insert_pdf(imgpdf) # 将当前页插入文档
# 保存在图片文件夹下
save_pdf_path = os.path.join(dir, pdf_name)
if os.path.exists(save_pdf_path):
os.remove(save_pdf_path)
doc.save(save_pdf_path) # 保存pdf文件
doc.close()
3. 软件的一些说明
- 本软件会永久开源并且永不收费,仅供喜欢爬虫技术的小伙伴们学习使用;
- 软件可能会由于各种原因而不能使用,请不要依赖此软件;
- 本次开发的软件仅支持 PPT 文件和 PDF 文件的下载,暂不支持 WORD 文件和 TXT 文件的下载;
- 软件爬取到的文件和文库中的原文件是有区别的,以PPT类型的文件为例,我们在文档页面看到的内容其实是 PPT 经过渲染后的图片。所以我们可以利用 Python 等编写爬虫脚本,爬取网页中的相关图片,再将这些图片合并成 PDF 文档。如果想要获取可编辑的 PPT 文件,可能需要你用「钞能力」支持一下文库。
4. 如何获取软件
如果我的文章帮到了你,请给一个小心心,有了你的鼓励我后续会更有动力创作出更加优质的文章,从而帮助到更多的小伙伴。当然,如果你觉得本文章在某些方面是不够好的,请在评论区留言,你的意见对我真的非常重要,谢谢。
我已经将本文章中讲述的源码都打包好了,并且还利用 pyinstaller 生成了可执行文件,如果你有这方面需求的话,请关注公众号「Job Yan」,后台回复百度文库,即可获取相关文件,后期程序更新的话,我会第一时间将相应文件更新到微信公众号后台。本系列教程持续更新,如果你也对爬虫感兴趣,欢迎关注,咱们共同进步,一起成长。
欢迎各位小伙伴用你们心爱的大手机扫描屏幕上的二维码(长按二维码可以识别或者保存到本地哟)。这是个套了支付宝马甲的公众号二维码,不信你就扫扫看(手动斜眼)。

文章持续更新,可以微信公众号搜索「Job Yab」第一时间阅读,本文 GitHub https://github.com/JobYan/PythonPearls 已经收录,还有算法学习、爬虫进阶等资料,欢迎 Star 和完善。
「保姆级」网络爬虫教程(二):教你下载文库中的PDF文档!的更多相关文章
- ABBYY PDF Transformer+从文件选项中创建PDF文档的教程
可使用OCR文字识别软件ABBYY PDF Transformer+从Microsoft Word.Microsoft Excel.Microsoft PowerPoint.HTML.RTF.Micr ...
- SpringBoot入门教程(二十)Swagger2-自动生成RESTful规范API文档
Swagger2 方式,一定会让你有不一样的开发体验:功能丰富 :支持多种注解,自动生成接口文档界面,支持在界面测试API接口功能:及时更新 :开发过程中花一点写注释的时间,就可以及时的更新API文档 ...
- python爬虫处理在线预览的pdf文档
引言 最近在爬一个网站,然后爬到详情页的时候发现,目标内容是用pdf在线预览的 比如如下网站: https://camelot-py.readthedocs.io/en/master/_static/ ...
- Java 添加条码、二维码到PDF文档
本文介绍如何通过Java程序在PDF文档中添加条码和二维码.创建条码时,可创建多种不同类型的条码,包括Codebar.Code11.Code128A.Code128B.Code32.Code39.Co ...
- 迷上我成真恋爱学心理学挽回她PDF文档资料完整版情感技巧脱单教程
迷上我成真恋爱学心理学挽回她PDF文档资料完整版情感技巧脱单教程 成真迷上我偷听女人心挽回她课程 百度网盘迷上我教程pdf地址 百度网盘挽回她教程pdf+视频的地址 备用地址淘宝百度网盘发货地址 百度 ...
- 基于C#.NET的高端智能化网络爬虫(二)(攻破携程网)
本篇故事的起因是携程旅游网的一位技术经理,豪言壮举的扬言要通过他的超高智商,完美碾压爬虫开发人员,作为一个业余的爬虫开发爱好者,这样的言论我当然不能置之不理.因此就诞生了以及这一篇高级爬虫的开发教程. ...
- GJM:用C#实现网络爬虫(二) [转载]
上一篇<用C#实现网络爬虫(一)>我们实现了网络通信的部分,接下来继续讨论爬虫的实现 3. 保存页面文件 这一部分可简单可复杂,如果只要简单地把HTML代码全部保存下来的话,直接存文件就行 ...
- 用C#实现网络爬虫(二)
上一篇<用C#实现网络爬虫(一)>我们实现了网络通信的部分,接下来继续讨论爬虫的实现 3. 保存页面文件 这一部分可简单可复杂,如果只要简单地把HTML代码全部保存下来的话,直接存文件就行 ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- python 网络爬虫(二)
一.编写第一个网络爬虫 为了抓取网站,我们需要下载含有感兴趣的网页,该过程一般被称为爬取(crawling).爬取一个网站有多种方法,而选择哪种方法更加合适,则取决于目标网站的结构. 首先探讨如何安全 ...
随机推荐
- Avalonia中用FluentAvalonia+DialogHost.Avalonia实现界面弹窗和对话框
Avalonia中用FluentAvalonia+DialogHost.Avalonia实现界面弹窗和对话框 本文是项目中关于 弹窗界面 设计的技术分享,通过 FluentAvalonia+Dialo ...
- VUE3、ElementPlus 重构若依vue2 表单构建功能
Vue3 + ElementPlus + Vite 重构 若依Vue2 表单构建功能 若依官方的Vue3 版本发布已经有段时间了,就是这个表单构建功能一直没有安排计划去适配到Vue3! 前段时间公司需 ...
- DXP TreeList 目录树
DXP TreeList 目录树 1.需求背景 需要一个支持勾选,拖动节点,保存各节点顺序的目录树. 2.创建目录树 在treeList控件中添加两个colunm 用来显示绑定数据和显示值. 接下来对 ...
- 操作系统实验——利用Linux的消息队列通信机制实现两个线程间的通信
目录 一. 题目描述 二.实验思路 三.代码及实验结果 四.遇到问题及解决方法 五.参考文献 一. 题目描述 编写程序创建三个线程:sender1线程.sender2线程和receive线程,三个线程 ...
- Java单元测试及常用语句
1 前言 编写Java单元测试用例,即把一段复杂的代码拆解成一系列简单的单元测试用例,并且无需启动服务,在短时间内测试代码中的处理逻辑.写好Java单元测试用例,其实就是把"复杂问题简单化, ...
- AtCoder ABC183F Confluence
题意 \(n\)个人,每个人属于一个班级\(ci\),这些人会有些小团体(并查集) 两种操作: \(1\) \(a\) \(b\),将\(a\)所在的集体和\(b\)所在的集体合并 \(2\) \(x ...
- Codeforces Round #576 (Div. 2)
A - City Day 题意:给n,x,y和数组a[n],求最小的下标d,使得有a[d-x,d-x+1,--d-1,d+1,d-1,d+1,--d+y-1,d+y]都比a[d]小,若d-x<= ...
- 企业级低代码平台,通用代码生成平台,Java开源项目(附源码)
项目介绍 Jeecg-Boot 是一款基于代码生成器的智能开发平台!采用前后端分离架构:SpringBoot,Mybatis,Shiro,JWT,Vue&Ant Design.强大的代码生成器 ...
- Kafka Stream 高级应用
9.1将Kafka 与其他数据源集成 对于第一个高级应用程序示例,假设你在金融服务公司工作.公司希望将其现有数据迁移到新技术实现的系统中,该计划包括使用 Kafka.数据迁移了一半,你被要求去更新公司 ...
- Chrome 手机端网页如何使用开发者模式
chrome 手机端网页如何调试 在Chrome手机端,你可以使用Chrome开发者工具来调试网页.下面是一些步骤: 首先,确保你的手机已经开启开发者模式.打开USB调试功能或可以通过USB连接或无线 ...