从零开始构建一个电影知识图谱,实现KBQA智能问答[下篇]:Apache jena SPARQL endpoint及推理、KBQA问答Demo超详细教学
从零开始构建一个电影知识图谱,实现KBQA智能问答[下篇]:Apache jena SPARQL endpoint及推理、KBQA问答Demo超详细教学
效果展示:
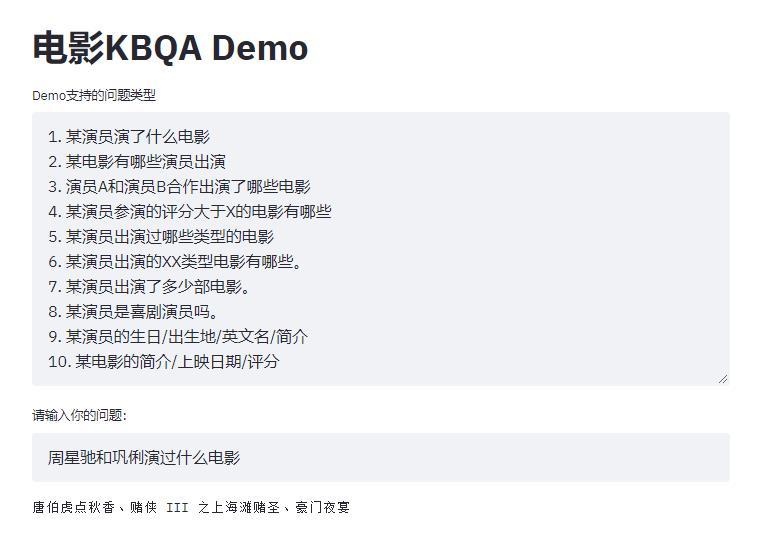
1.Apache jena SPARQL endpoint及推理
在上一篇我们学习了如何利用 D2RQ 来开启 endpoint 服务,但它有两个缺点:
不支持直接将 RDF 数据通过 endpoint 发布到网络上。
不支持推理。
这次我们介绍的 Apache Jena 能够解决上面两个问题。
1.1.Apache Jena 简介
Apache Jena(后文简称 Jena),是一个开源的 Java 语义网框架(open source Semantic Web Framework for Java),用于构建语义网和链接数据应用。下面是 Jena 的架构图:
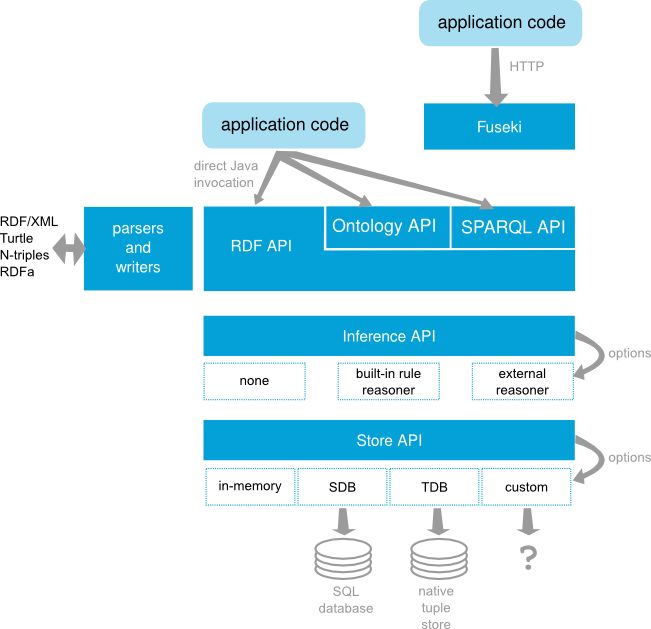
本次实践我们会用到的组件有:TDB、rule reasoner 和 Fuseki。
TDB 是 Jena 用于存储 RDF 的组件,是属于存储层面的技术。在单机情况下,它能够提供非常高的 RDF 存储性能。目前 TDB 的最新版本是 TDB2,且与 TDB1 不兼容。
Jena 提供了 RDFS、OWL 和通用规则推理机。其实 Jena 的 RDFS 和 OWL 推理机也是通过 Jena 自身的通用规则推理机实现的。
Fuseki 是 Jena 提供的 SPARQL 服务器,也就是 SPARQL endpoint。其提供了四种运行模式:单机运行、作为系统的一个服务运行、作为 web 应用运行或者作为一个嵌入式服务器运行。
Jena 目前是使用最广泛、文档最全、社区最活跃的一个开源语义网框架。更多的细节,读者可以参考官方文档。
1.2.Fuseki 与 OWL 推理实战
我们先下载 Jena 的最新版本(fuseki 和其他的功能模块不在同一个文件中,需要分别下载 apache-jena 和 apache-jena-fuseki)。后续操作以 Windows 为例,Linux 类似,只是脚本位置不同。
创建一个目录(我这里命名为 “tdb”)用于存放 tdb 数据。进入“apache-jena-X.X.X” 文件夹的 bat 目录,可以看到很多批处理文件,我们使用 “tdbloader.bat” 将之前我们的 RDF 数据以 TDB 的方式存储。命令如下:
.\tdbloader.bat --loc="D:\apache jena\tdb" "D:\d2rq\kg_demo_movie.nt"
“--loc” 指定 tdb 存储的位置,即刚才我们创建的文件夹;第二个参数是由 Mysql 数据转换得到的 RDF 数据。
进入入 “apache-jena-fuseki-X.X.X” 文件夹,运行 “fuseki-server.bat”,然后退出。程序会为我们在当前目录自动创建“run” 文件夹。将我们的本体文件 “ontology.owl” 移动到 “run” 文件夹下的 “databases” 文件夹中,并将 “owl” 后缀名改为 “ttl”。在“run” 文件夹下的 “configuration” 中,我们创建名为 “fuseki_conf.ttl” 的文本文件(取名没有要求),加入如下内容:
@prefix : <http://base/#> .
@prefix tdb: <http://jena.hpl.hp.com/2008/tdb#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix ja: <http://jena.hpl.hp.com/2005/11/Assembler#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix fuseki: <http://jena.apache.org/fuseki#> .
:service1 a fuseki:Service ;
fuseki:dataset <#dataset> ;
fuseki:name "kg_demo_movie" ;
fuseki:serviceQuery "query" , "sparql" ;
fuseki:serviceReadGraphStore "get" ;
fuseki:serviceReadWriteGraphStore "data" ;
fuseki:serviceUpdate "update" ;
fuseki:serviceUpload "upload" .
<#dataset> rdf:type ja:RDFDataset ;
ja:defaultGraph <#model_inf> ;
.
<#model_inf> a ja:InfModel ;
ja:baseModel <#tdbGraph> ;
#本体文件的路径
ja:content [ja:externalContent <file:///D:/apache%20jena/apache-jena-fuseki-3.5.0/run/databases/ontology.ttl> ] ;
#启用OWL推理机
ja:reasoner [ja:reasonerURL <http://jena.hpl.hp.com/2003/OWLFBRuleReasoner>] .
<#tdbGraph> rdf:type tdb:GraphTDB ;
tdb:dataset <#tdbDataset> ;
.
<#tdbDataset> rdf:type tdb:DatasetTDB ;
tdb:location "D:/apache jena/tdb" ;
.
再次运行 “fuseki-server.bat”,如果出现如下界面表示运行成功:

Fuseki 默认的端口是 3030,浏览器访问 “http://localhost:3030/”, 和之前介绍的 D2RQ web 界面类似,我们可以进行 SPARQL 查询等操作。在 Python 中用 SPARQLWrapper 向 Fuseki server 发送查询请求:
PREFIX : <http://www.kgdemo.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT * WHERE {
?x :movieTitle '功夫'.
?x ?p ?o.
}
即查询电影《功夫》的所有属性。返回的结果:
x p o
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasGenre file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#genre/14
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasGenre file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#genre/28
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasGenre file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#genre/35
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasGenre file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#genre/80
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.w3.org/1999/02/22-rdf-syntax-ns#type http://www.kgdemo.com#Movie
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#movieRating 7.2E0
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#movieIntroduction 1940年代的上海,自小受尽欺辱的街头混混阿星(周星驰)为了能出人头地,可谓窥见机会的缝隙就往里钻,今次他盯上行动日益猖獗的黑道势力“斧头帮”,想借之大名成就大业。 阿星假冒“斧头帮”成员试图在一个叫“猪笼城寨”的地方对居民敲诈,不想引来真的“斧头帮”与“猪笼城寨”居民的恩怨。“猪笼城寨”原是藏龙卧虎之处,居民中有许多身怀绝技者(元华、梁小龙等),他们隐藏于此本是为远离江湖恩怨,不想麻烦自动上身,躲都躲不及。而在观战正邪两派的斗争中,阿星逐渐领悟功夫的真谛。
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#movieTitle 功夫
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#movieReleaseDate 2004-02-10
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.w3.org/1999/02/22-rdf-syntax-ns#type http://www.w3.org/2002/07/owl#Thing
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/25251
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/57609
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/118745
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/57607
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/65975
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/78878
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/83635
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/119426
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/545277
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/576408
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/1136808
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/1173200
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/1173216
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/1173223
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/1173224
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/1287732
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.kgdemo.com#hasActor file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/1676386
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.w3.org/1999/02/22-rdf-syntax-ns#type http://www.w3.org/2000/01/rdf-schema#Resource
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470 http://www.w3.org/2002/07/owl#sameAs file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#movie/9470
电影的 “hasActor” 属性是通过 OWL 推理机得到的,即我们原本的 RDF 数据里面是没有的。可以在 D2RQ 的 endpoint 中进行同样的查询,得到如下结果:
x p o
http://localhost:2020/resource/movie/9470 http://www.kgdemo.com#movieRating 7.2E0
http://localhost:2020/resource/movie/9470 http://www.kgdemo.com#movieIntroduction 1940年代的上海,自小受尽欺辱的街头混混阿星(周星驰)为了能出人头地,可谓窥见机会的缝隙就往里钻,今次他盯上行动日益猖獗的黑道势力“斧头帮”,想借之大名成就大业。 阿星假冒“斧头帮”成员试图在一个叫“猪笼城寨”的地方对居民敲诈,不想引来真的“斧头帮”与“猪笼城寨”居民的恩怨。“猪笼城寨”原是藏龙卧虎之处,居民中有许多身怀绝技者(元华、梁小龙等),他们隐藏于此本是为远离江湖恩怨,不想麻烦自动上身,躲都躲不及。而在观战正邪两派的斗争中,阿星逐渐领悟功夫的真谛。
http://localhost:2020/resource/movie/9470 http://www.kgdemo.com#hasGenre http://localhost:2020/resource/genre/14
http://localhost:2020/resource/movie/9470 http://www.kgdemo.com#hasGenre http://localhost:2020/resource/genre/28
http://localhost:2020/resource/movie/9470 http://www.kgdemo.com#hasGenre http://localhost:2020/resource/genre/35
http://localhost:2020/resource/movie/9470 http://www.kgdemo.com#hasGenre http://localhost:2020/resource/genre/80
http://localhost:2020/resource/movie/9470 http://www.kgdemo.com#movieReleaseDate 2004-02-10
http://localhost:2020/resource/movie/9470 http://www.kgdemo.com#movieTitle 功夫
http://localhost:2020/resource/movie/9470 http://www.w3.org/1999/02/22-rdf-syntax-ns#type http://www.kgdemo.com#Movie
这些是真实存在于 “kg_demo_movie.nt” 的数据。
1.3.规则推理实战
在 “databases” 文件夹下新建一个文本文件“rules.ttl”,填入如下内容:
@prefix : <http://www.kgdemo.com#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix xsd: <XML Schema> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
[ruleComedian: (?p :hasActedIn ?m) (?m :hasGenre ?g) (?g :genreName '喜剧') -> (?p rdf:type :Comedian)]
[ruleInverse: (?p :hasActedIn ?m) -> (?m :hasActor ?p)]
我们定义了一个名为 “ruleComedian” 的规则,它的意思是:如果有一个演员,出演了一部喜剧电影,那么他就是一位喜剧演员。修改配置文件“fuseki_conf.ttl”:
@prefix : <http://base/#> .
@prefix tdb: <http://jena.hpl.hp.com/2008/tdb#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix ja: <http://jena.hpl.hp.com/2005/11/Assembler#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix fuseki: <http://jena.apache.org/fuseki#> .
:service1 a fuseki:Service ;
fuseki:dataset <#dataset> ;
fuseki:name "kg_demo_movie" ;
fuseki:serviceQuery "query" , "sparql" ;
fuseki:serviceReadGraphStore "get" ;
fuseki:serviceReadWriteGraphStore "data" ;
fuseki:serviceUpdate "update" ;
fuseki:serviceUpload "upload" .
<#dataset> rdf:type ja:RDFDataset ;
ja:defaultGraph <#model_inf> ;
.
<#model_inf> a ja:InfModel ;
ja:baseModel <#tdbGraph> ;
#本体文件的路径
ja:content [ja:externalContent <file:///D:/apache%20jena/apache-jena-fuseki-3.5.0/run/databases/ontology.ttl> ] ;
#关闭OWL推理机
#ja:reasoner [ja:reasonerURL <http://jena.hpl.hp.com/2003/OWLFBRuleReasoner>] .
#开启规则推理机,并指定规则文件路径
ja:reasoner [
ja:reasonerURL <http://jena.hpl.hp.com/2003/GenericRuleReasoner> ;
ja:rulesFrom <file:///D:/apache%20jena/apache-jena-fuseki-3.5.0/run/databases/rules.ttl> ; ]
.
<#tdbGraph> rdf:type tdb:GraphTDB ;
tdb:dataset <#tdbDataset> ;
.
<#tdbDataset> rdf:type tdb:DatasetTDB ;
tdb:location "D:/apache jena/tdb_for_demo" ;
.
我们只能启用一种推理机。前面也提到,OWL 的推理功能也可以在规则推理机里面实现,因此我们定义了 “ruleInverse” 来表示 “hasActedIn” 和“hasActor”的相反关系。更多细节读者可以参考文档。
我们执行如下 SPARQL 查询,喜剧演员有哪些:
PREFIX : <http://www.kgdemo.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT * WHERE {
?x rdf:type :Comedian.
?x :personName ?n.
}
limit 10
查询结果:
x n
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/111298 郑丹瑞
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/70591 陈欣健
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/116351 沈殿霞
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/116052 鲍汉琳
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/1002925 张同祖
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/62423 林正英
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/1614091 林琪欣
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/224929 陈法蓉
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/1135398 叶世荣
file:///D:/d2rq/d2rq-0.8.1/kg_demo_movie.nt#person/119426 元秋
1.4.小结
本次实践介绍了如何使用 Jena 来开启 endpoint 服务,提供高效的查询;并介绍了如何加入推理引擎。我们是用 Jena 提供的命令行工具来完成上述操作。实际上,jena 提供了所有工具的 API 接口,读者可以用 Java 编写程序,进行开发。
2.KBQA Demo
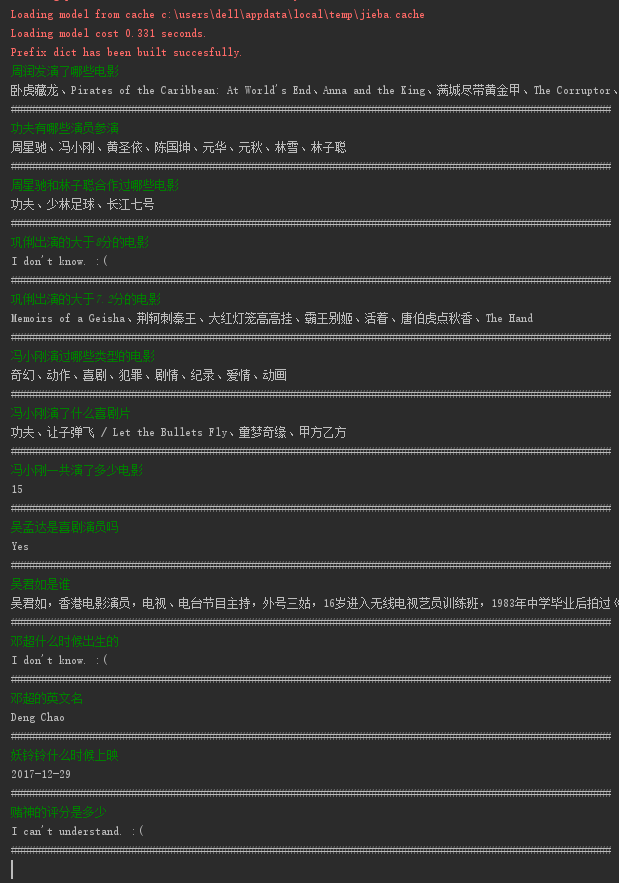
下面将介绍如何用 Python 完成一个简易的问答程序。下图是 demo 的展示效果:
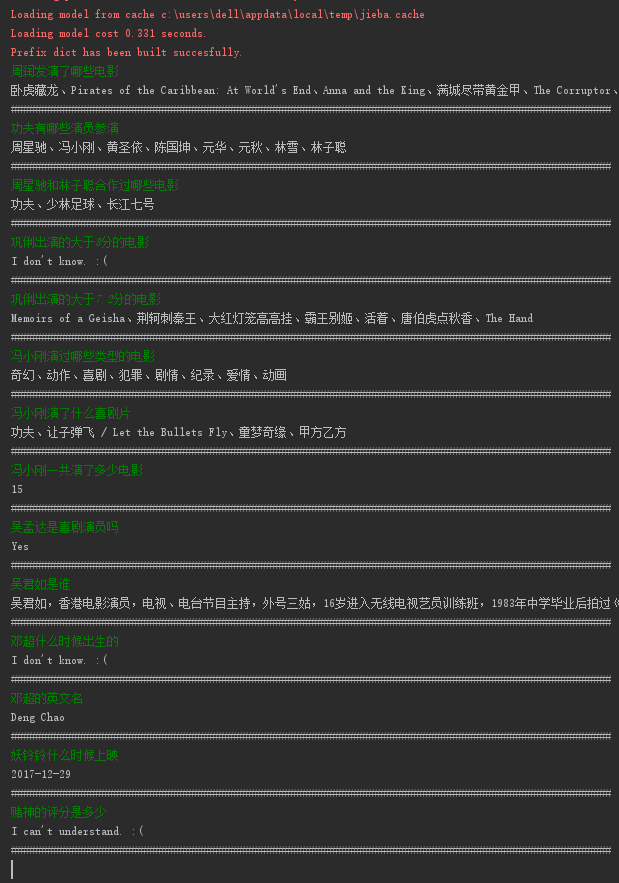
查询结果为空,回答 “I don't know.”;不能理解问句,回答 “I can't understand.”。本实现参考了王昊奋老师发布在 OpenKG 上的 demo“基于 REfO 的 KBQA 实现及示例”,读者也可以参考此示例,来完成本 demo。下面谈谈本 demo 的流程。
2.1 基本流程
此 demo 是利用正则表达式来做语义解析。我们需要第三方库来完成初步的自然语言处理(分词、实体识别),然后利用支持词级别正则匹配的库来完成后续的语义匹配。
分词和实体识别(人名和电影名)我们用 jieba 来完成。jieba 是一个轻量级的中文分词工具,有多种语言的实现版本。对于分词,在实验环境中,jieba 还是勉强能用。在我们这个 demo 当中,有些经常会被使用的词语并不能被正确切分。比如:“喜剧电影”、“恐怖电影”、“科幻电影”、“喜剧演员”、“出生日期”等,在分词的时候,jieba 把它们当作一个词来处理,我们需要手动调整词语的频率使得 “喜剧电影” 能被切分为 “喜剧” 和“电影”。至于实体识别,jieba 对于人名的识别精度尚可接受,但是电影名称的识别精度太低以至于完全不可用。因此,我们直接把数据库中的人名和电影名导出,作为外部词典;使用 jieba 的时候加载外部词典,这样就能解决实体识别的问题。
将自然语言转为以词为基础的基本单位后,我们使用 REfO(Regular Expressions for Objects) 来完成语义匹配。具体实现请参考 OpenKG 的 demo 或者本 demo 的代码。
匹配成功后,得到其对应的我们预先编写的 SPARQL 模板,再向 Fuseki 服务器发送查询,最后将结果打印出来。
2.2 代码文件说明
kg_demo_movie/
crawler/
movie_crawler.py
__init__.py
tradition2simple/
langconv.py
traditional2simple.py
zh_wiki.py
__init__.py
KB_query/
jena_sparql_endpoint.py
query_main.py
question2sparql.py
question_temp.py
word_tagging.py
external_dict/
csv2txt.py
movie_title.csv
movie_title.txt
person_name.csv
person_name.txt
__init__.py
"crawler" 文件夹包含的是我们从 "The Movie DB" 获取数据的脚本。
"KB_query" 文件夹包含的是完成整个问答 demo 流程所需要的脚本。
"external_dict" 包含的是人名和电影名两个外部词典。csv 文件是从 mysql-workbench 导出的,按照 jieba 外部词典的格式,我们将 csv 转为对应的 txt。
"word_tagging",定义 Word 类的结构(即我们在 REfO 中使用的对象);定义 "Tagger" 类来初始化词典,并实现自然语言到 Word 对象的方法。
"jena_sparql_endpoint",用于完成与 Fuseki 的交互。
"question2sparql",将自然语言转为对应的 SPARQL 查询。
"question_temp",定义 SPARQL 模板和匹配规则。
"query_main",main 函数。
在运行 "query_main" 之前,读者需要启动 Fuseki 服务,具体方法请参考上一篇文章。
2.3 小结
我们通过使用正则表达式的方式来解析自然语言,并将解析的结果和我们预定义的模板进行匹配,最后实现一个简易的 KBQA。方法没有大家想象的那么 “高大上”,没有统计方法、没有机器学习也没有深度学习。正则的好处是,易学,从事相关行业的人基本都了解这个东西;其次,可控性强或者说可解释性强,如果某个问题解析错误,我们只要找到对应的匹配规则进行调试即可;最后,正则冷启动比较容易,在没有数据或者数据极少的情况下,我们可以利用正则规则马上上线一个类似上述 demo 的初级的问答系统。在现实情况中,由于上述优点,工业界也比较青睐用正则来做语义解析。正则方法的缺陷也是显而易见的,它并不能理解语义信息,而是基于符号的匹配。换个角度说,用正则的方法,就需要规则的设计者能够尽可能考虑到所有情况,然而这是不可能的。暂且不考虑同义词、句子结构等问题,光是罗列所有可能的问题就需要花费很大的功夫。尽管如此,在某些垂直领域,比如 “音乐”,“电影”,由于问题集合的规模在一定程度上是可控的(我们基本能将用户的问题划定在某个范围内),正则表达式还是有很大的用武之地的。在冷启动一段时间,获得了一定用户使用数据之后,我们可以考虑引入其他的方法来改善系统的性能,然后逐渐减少正则规则在整个系统中的比重。如果读者想深入研究 KBQA,可以参考专栏 “揭开知识库问答 KB-QA 的面纱”,该专栏的作者详细介绍了做 KBQA 的方法和相关研究。
3.项目实操
3.1环境配置
- Python版本为3.6
- 安装依赖
pip install -r requirements.txt。 - jena版本为3.5.0,已经上传在该repo中(如果不用Docker运行demo,需要自己修改配置文件中的路径)。
- d2rq使用的0.8.1
3.2 运行方式
这里提供两种运行demo的方式:
- 直接构建docker镜像,部署容器服务。推荐这种方式,已经把各种环境配置好了。只需要安装docker,构建镜像。
- 直接在本地运行。需要自行修改配置文件(jena/apache-jena-fuseki-3.5.0/run/configuration/fuseki_conf.ttl配置文件中的路径)
3.3 构建docker镜像
进入项目根目录
docker build -t kbqa:V0.1 .
docker run -p 80:80
打开浏览器,输入localhost,即能看到demo界面。
3.4 本地运行
其实就是把Dockerfile里面的命令直接在本地环境运行(记得修改configuration/fuseki_conf.ttl中的文件路径)。
第一步:安装依赖库
pip3.6 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
第二步:将nt格式的三元组数据以tdb进行存储(怎么得到kg_demo_movie.nt文件请参考上篇内容)。
/kbqa/jena/apache-jena-3.5.0/bin/tdbloader --loc="path_of_tdb" "path_of_kg_demo_movie.nt" # 自行指定tdb的路径,记得和configuration/fuseki_conf.ttl中一致
window环境是使用/kbqa/jena/apache-jena-3.5.0/bat/tdbloader.bat
第三步:设置环境变量(windows如何设置请自行查询;也可以不设置streamlit端口,使用默认端口,第五步启动后会提示服务的端口)
export LANG=C.UTF-8 LC_ALL=C.UTF-8 STREAMLIT_SERVER_PORT=80 FUSEKI_HOME=/kbqa/jena/apache-jena-fuseki-3.5.0
第四步:运行fuseki(进入apache-jena-fuseki-3.5.0子目录,windows运行fuseki-server.bat)
./fuseki-server
第五步:运行web服务。
streamlit run streamlit_app.py --server.enableCORS=true
打开浏览器,输入指定的地址即可。
3.5 问题集锦
- fuseki-server服务启动后,关闭重启会报错。这是jena的一个bug,把tdb中的文件删了,重新用tdbloader命令生成一次即可。
目录结构
- Data文件夹
包含ER图模型文件和创建数据库、表,插入所有数据的sql文件。用户可以直接使用sql文件导入数据到mysql中。
- kg_demo_movie文件夹
- crawler中的movie_crawler用于从The Movie DB下载数据,用户需要自己去网站注册账号,申请API KEY。在脚本中填入自己的API KEY,填写mysql相关参数即可运行。用户需要额外下载的包:requests和pymysql。tradition2simple用于将繁体字转为简体字(声明一下,我找不到该文件的出处了,我是从网上找到的解决方案,如果有用户知道该作者,麻烦告知,我会备注)。
- KB_query文件夹包含的是完成整个问答demo流程所需要的脚本。
- "external_dict"包含的是人名和电影名两个外部词典。csv文件是从mysql-workbench导出的,按照jieba外部词典的格式,我们将csv转为对应的txt。
- "word_tagging",定义Word类的结构(即我们在REfO中使用的对象);定义"Tagger"类来初始化词典,并实现自然语言到Word对象的方法。
- "jena_sparql_endpoint",用于完成与Fuseki的交互。
- "question2sparql",将自然语言转为对应的SPARQL查询。
- "question_temp",定义SPARQL模板和匹配规则。
- "query_main",main函数。在运行"query_main"之前,读者需要启动Fuseki服务。
ontology.owl
通过protege构建的本体,用户可以直接用protege打开,查看或修改。kg_demo_movie_mapping.ttl
根据d2rq mapping language编辑的映射文件,将数据库中的数据映射到我们构建的本体上。kg_demo_movie.nt
利用d2rq,根据mapping文件,由Mysql数据库转换得到的RDF数据。fuseki_conf.ttl
fuseki server配置文件,指定推理引擎,本体文件路径,规则文件路径,TDB路径等rules.ttl
规则文件,用于基于规则的推理。streamlit_app.py
web demo文件,基于streamlit库。
项目码源见文末跳转
欢迎关注公众号:汀丶人工智能,公众号也会提供一些相关的资源和优质文章。


从零开始构建一个电影知识图谱,实现KBQA智能问答[下篇]:Apache jena SPARQL endpoint及推理、KBQA问答Demo超详细教学的更多相关文章
- GitHub:如何构建一个股票市场知识图谱?(附代码&链接)
来源:专知 本文约 600007 董事⻓/董事 高燕 女 60 600007 执⾏董事 刘永政 男 50 600008 董事⻓/董事 ··· ··· ··· ··· ··· 注:建议表头最好用相应的英 ...
- 从零开始构建一个的asp.net Core 项目
最近突发奇想,想从零开始构建一个Core的MVC项目,于是开始了构建过程. 首先我们添加一个空的CORE下的MVC项目,创建完成之后我们运行一下(Ctrl +F5).我们会在页面上看到"He ...
- 从零开始构建一个centos+jdk7+tomcat7的docker镜像文件
从零开始构建一个centos+jdk7+tomcat7的镜像文件 centos7系统下docker运行环境的搭建 准备centos基础镜像 docker pull centos 或者直接下载我准备好的 ...
- 从零开始构建一个的asp.net Core 项目(一)
最近突发奇想,想从零开始构建一个Core的MVC项目,于是开始了构建过程. 首先我们添加一个空的CORE下的MVC项目,创建完成之后我们运行一下(Ctrl +F5).我们会在页面上看到“Hello W ...
- 从零开始构建一个的asp.net Core 项目(二)
接着上一篇博客继续进行.上一篇博客只是显示了简单的MVC视图页,这篇博客接着进行,连接上数据库,进行简单的CRUD. 首先我在Controllers文件夹点击右键,添加->控制器 弹出的对话框中 ...
- .Net 从零开始构建一个框架之基本实体结构与基本仓储构建
本系列文章将介绍如何在.Net框架下,从零开始搭建一个完成CRUD的Framework,该Framework将具备以下功能,基本实体结构(基于DDD).基本仓储结构.模块加载系统.工作单元.事件总线( ...
- [计算机视觉]从零开始构建一个微软how-old.net服务/面部属性识别
大概两三年前微软发布了一个基于Cognitive Service API的how-old.net网站,用户可以上传一张包含人脸的照片,后台通过调用深度学习算法可以预测照片中的人脸.年龄以及性别,然后将 ...
- 从零开始构建一个Reactor模式的网络库(二)线程类Thread
线程类Thread是对POSIX线程的封装类,因为要构建的是一个Linux环境下的多线程网络库,对线程的封装是很必要的. 首先是CurrentThread命名空间,主要是获取以及缓存线程id: #if ...
- 从零开始构建一个Reactor模式的网络库(一) 线程同步Mutex和Condition
最近在学习陈硕大神的muduo库,感觉写的很专业,以及有一些比较“高级”的技巧和设计方式,自己写会比较困难. 于是打算自己写一个简化版本的Reactor模式网络库,就取名叫mini吧,同样只基于Lin ...
- 知识图谱-生物信息学-医学论文(Chip-2022)-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用
16.(2022)Chip-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用 论文标题: Construction and Application of Chinese Breast Cance ...
随机推荐
- 无法访问Docker 里的 mysql, redis
[root@centos-linux jimmy]# firewall-cmd --state not running [root@centos-linux jimmy]# sysctl net.ip ...
- 23年校招Java开发同花顺、滴滴等面经
前言 已经工作近半年时间了,最近突然翻到这份面经,于是想整理一下一些面试的经验,大中小公司都有 青书一面 50min 数据库.java基础. Cas机制. Tcp/udp区别 堆排序介绍,答错了,弄成 ...
- 拥抱智能,AI 视频编码技术的新探索
随着视频与交互在日常生活中的作用日益突显,愈发多样的视频场景与不断提高的视觉追求对视频编码提出更高的挑战.相较于人们手工设计的多种视频编码技术,AI 编码可以从大数据中自我学习到更广泛的信号内在编码规 ...
- 【计算机网络】WebSocket 是什么原理?为什么可以实现持久连接?
一.WebSocket是HTML5出的东西(协议),也就是说HTTP协议没有变化,或者说没关系,但HTTP是不支持持久连接的(长连接),循环连接的不算) 首先HTTP有1.1和1.0之说,也就是所谓的 ...
- BZOJ 3450 - Tyvj1952 Easy (期望DP)
描述 某一天 WJMZBMR 在打 osu~~~ 但是他太弱逼了,有些地方完全靠运气:( 我们来简化一下这个游戏的规则: 有 \(n(n\le 300000)\) 次点击要做,成功了就是 o,失败了就 ...
- HDU - 2897 邂逅明下 (简单博弈)
题目链接: https://vjudge.net/problem/HDU-2897 题目大意: 就是现在一堆石子有n颗, 每次只能拿走p~q颗, 当剩余少于p颗的时候必须一次拿完 拿走最后一颗的人败 ...
- Go语言安装(Windows10)
一. 官网下载 https://golang.google.cn/dl/ 二. 软件包安装 选择对应的路径进行安装 三. 环境变量设置 1.path 检查系统环境变量Path内已经添加Go的安 ...
- 异步httpClient(Async HttpClient)
一.简介 二.mvn依赖 三.客户端 3.1 官网实例 3.2. 根据官方文档的介绍,简单封装了一个异步HttpClient工具类 3.3 基本原理 四.参考文档 一.简介 HttpClient提供了 ...
- 分享这位大神的WPF界面设计系列视频
本文结构: 前言 视频详情 搬运详情 总结 4.1 国内推荐WPF资源 4.2 B站是学习的天堂 4.3 去外面看看 4.4 个人给C/S同学建议 1. 前言 今天介绍油管上一个大佬发的WPF设计系列 ...
- Keep English Level-01
state -- 声称,宣称,国家,政府 state-owned -- 国有的 He stated that "hell will break loose,politically and m ...