深度学习中使用TensorFlow或Pytorch框架时到底是应该使用CPU还是GPU来进行运算???
本文实验环境为Python3.7, TensorFlow-gpu=1.14, CPU为i7-9700k,锁频4.9Ghz, GPU为2060super显卡
==========================
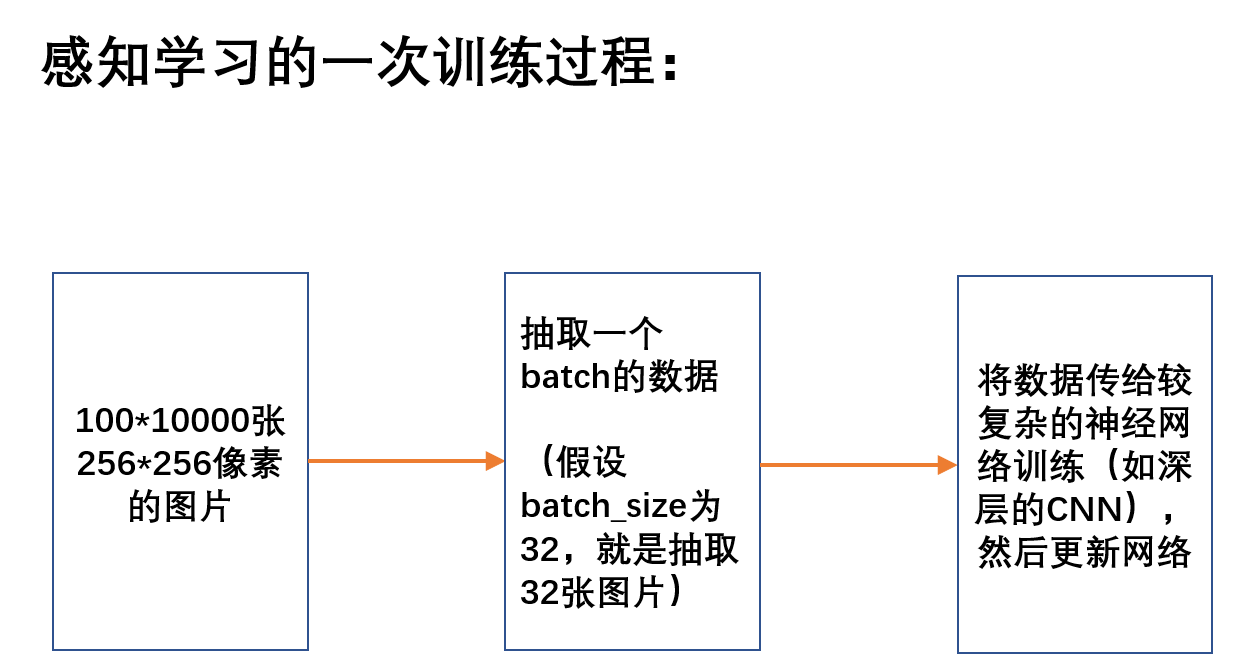
机器学习按照不同的分类标准可以有不同的分类方式,这里我们将深度学习按照感知学习和决策控制学习可以分为两类。感知学习类的比较有名的就是图像识别,语言识别等,而决策类的一般就是指强化学习了。
本文要讲的事情其实对于做感知学习的人来说是没有多少意义的,因为使用框架来搞深度学习首选的就是GPU,这基本上可以被认为是唯一选择,当然这里说的GPU是指计算能力还过得去的显卡,现在这个时间来说的话怎么你得是RTX2060,2070,2080TI,3060ti,3070,3080,3090的显卡,你要是非拿好几年前的老卡来说就没有比较价值了。换句话说就是搞感知的就是有较新几代的显卡那就首选显卡。
但是本文的意义又在哪呢?本文比较适用的对象主要就是那些搞决策控制方向的机器学习研究的人。
为啥搞感知的人一定首选显卡来做计算,而做决策学习的就要先研究研究我是使用显卡还是CPU来做计算呢?
首先,我们看下感知学习和决策学习在运算过程中有哪些不同:
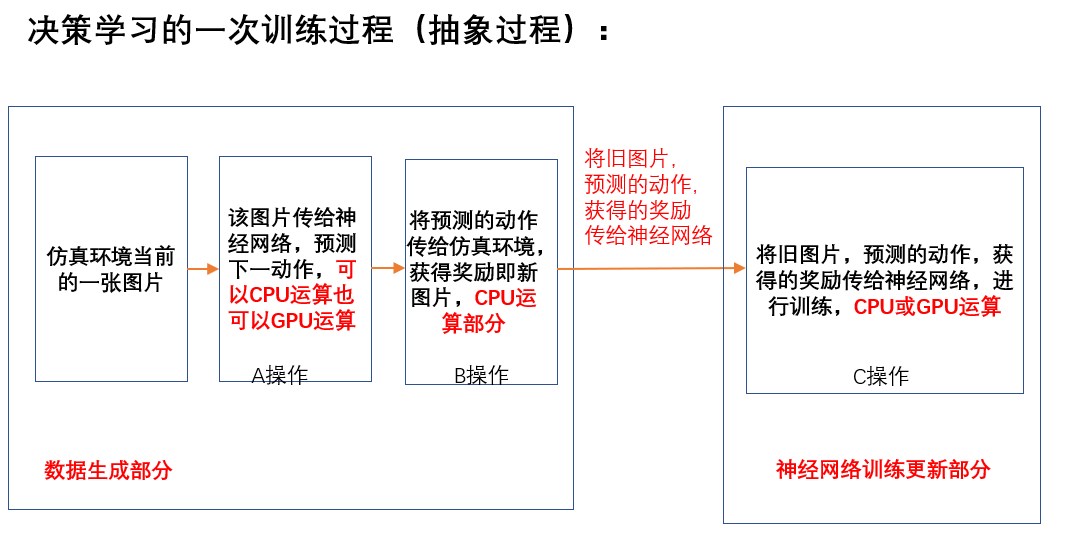
1.数据获得的途径不同。感知学习在运算前或者说在训练模型之前我们是已经获得到数据集的,训练数据是已知已有可获得的,而在决策学习中我们在训练模型之前是无法获得训练数据的。决策学习(强化学习)的训练数据是在训练过程中动态生成的,该生成过程往往需要和游戏仿真器等外部环境进行交互,而交互过程目前来看全部都是需要使用CPU来进行的,总的来说决策学习的训练数据需要动态的通过CPU进行计算来获得,因此决策学习的基本训练过程可以抽象的理解为:
CPU计算获得训练数据+通过CPU或GPU来训练模型
如果我们在决策学习中每一次迭代(每次更新模型)前获得的训练数据较少,而构建的神经网络模型层数较少或过于简单就会导致使用CPU或GPU来更新一次模型所需时间差不多,甚至会出现用CPU更新模型的速度快于GPU更新网络模型。而这时又因为我们是通过CPU来获得训练数据的,如果更新一次模型前只获得少量数据花费较少的时间,而训练模型是在GPU上,那么将数据从CPU计算时存储的内存导入到GPU计算时存储数据的显存所花时间就会和数据生成的时间与模型更新的时间相当,而这样就会导致使用gpu更新网络模型下的整体运算时间高于使用cpu更新网络模型下的整体运算时间。这个时候我们往往可以通过使用CPU来运行TensorFlow等框架进行提速,而不是使用GPU。
2. 神经网络复杂性不同。感知学习的神经网络往往采用较复杂的神经网络架构,或者说网络层数较多,而决策学习采用的神经网络架构较为简单。同样的训练数据在使用较复杂神经网络进行训练所花费的时间要高于使用较简单神经网络训练的时间。正因为决策学习训练网络花费的时间较少使用CPU和GPU来训练网络花费时间差不多,又加上数据生成的时间也往往较少(一般更新一次网络前只生成一个数据),这时如果用GPU训练网络而从CPU生成的数据传输到GPU所花费的时间就会和数据生成和网络训练的时间相当,因此该情况下我们使用CPU来训练网络会比GPU训练网络更加高效。
==============================================
--------------------------------------------------------------------
===================================================
从决策学习的训练过程可以看到一次训练可以分为A,B,C三个操作,其中A、B操作为数据生成部分,C操作为网络训练部分。A操作可以在CPU上运行也可以在GPU上运行,而B操作必须在CPU上运行,而C操作也是既可以在CPU上运行也可以在GPU上运行。
一般情况下,A、B、C操作都是串行的,由于B操作必须在CPU上进行,所以A操作和C操作如果也是在CPU上进行则不需要进行数据切换。其中A操作是使用神经网络预测下一步动作,C操作是使用神经网络根据状态,动作,奖励等信息进行神经网络训练。A操作一般是传给神经网络一个图片然后获得一个动作,C操作一般是传给神经网络batch_size个数据进行网络训练。
这里我们单独把A操作拿出来进行运算,分别看下A操作在CPU上和在GPU上时A操作的运算效率:
运行代码:


import tensorflow as tf
import numpy as np
import time flags = tf.app.flags
flags.DEFINE_integer('D', 4, '输入层维度')
flags.DEFINE_integer('H', 50, '隐藏层维度')
flags.DEFINE_float('learning_rate', 1e-4, '学习率')
config = flags.FLAGS """
这个module是对神经网络的定义
"""
import tensorflow as tf class Policy_Net(object):
def __init__(self, config):
self.learning_rate = config.learning_rate # 1e-2
self.D = config.D # 4 输入向量维度
self.H = config.H # 50 隐藏层维度
# 设置新的graph
self.graph = tf.Graph()
# 设置显存的上限大小
gpu_options = tf.GPUOptions(allow_growth=True) # 按照计算需求动态申请内存
# 设置新的session
self.sess = tf.Session(graph=self.graph, config=tf.ConfigProto(gpu_options=gpu_options)) self.net_build() # 构建网络
self.sess.run(self.op_init) # 全局变量初始化 def net_build(self): # 构建网络
with self.graph.as_default():
observations = tf.placeholder(tf.float32, [None, self.D], name="input_states") # 传入的观测到的状态tensor
actions = tf.placeholder(tf.float32, [None, 1], name="input_actions")
advantages = tf.placeholder(tf.float32, [None, 1], name="reward_signal") # 根据策略网络计算出选动作action_0的概率probability, action_1的概率为1-probability
w1 = tf.get_variable("w1", shape=[self.D, self.H],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable("b1", shape=[self.H], initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.add(tf.matmul(observations, w1), b1))
w2 = tf.get_variable("w2", shape=[self.H, 1],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable("b2", shape=[1], initializer=tf.constant_initializer(0.0))
score = tf.add(tf.matmul(layer1, w2), b2)
""" probability为选择action=2 的概率, action=1的选择概率为 1-probability """
probability = tf.nn.sigmoid(score) # 动作0的actions=0, 动作1的actions=1 # advantages 为选择动作actions后所得到的累计折扣奖励
loglik = tf.log(actions * (actions - probability) + (1 - actions) * (actions + probability))
# loss为一个episode内所有observation,actions,advantages得到的损失的均值,reduce_mean
loss = -tf.reduce_mean(loglik * advantages) trainable_vars = tf.trainable_variables() # 获得图内需要训练的 variables
# 设置batch更新trainable_variables的placeholder
batchGrad = []
for var in tf.trainable_variables():
var_name = "batch_" + var.name.split(":")[0]
batchGrad.append(tf.placeholder(tf.float32, name=var_name)) newGrads = tf.gradients(loss, trainable_vars) # 获得loss对于图内需要训练的 variables 的梯度
adam = tf.train.AdamOptimizer(learning_rate=self.learning_rate) # 优化器
# 定义对参数 tvars 进行梯度更新的操作, 使用adam优化器对参数进行更新
updateGrads = adam.apply_gradients(zip(batchGrad, trainable_vars))
# 直接优化
self.opt = adam.minimize(loss) self.op_init = tf.global_variables_initializer()
self.observations = observations
self.actions = actions
self.advantages = advantages
self.batchGrad = batchGrad
self.probability = probability
self.trainable_vars = trainable_vars
self.newGrads = newGrads
self.updateGrads = updateGrads def grad_buffer(self):
return self.sess.run(self.trainable_vars) def action_prob(self, input_x):
act_prob = self.sess.run(self.probability, feed_dict={self.observations: input_x})
return act_prob def new_grads(self, observations, actions, discounted_rewards):
# 返回神经网络各参数对应loss的梯度
n_grads = self.sess.run(self.newGrads, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards})
return n_grads def update_grads(self, input_gradBuffer):
self.sess.run(self.updateGrads, feed_dict=dict(zip(self.batchGrad, input_gradBuffer))) def update_opt(self, observations, actions, discounted_rewards):
self.sess.run(self.opt, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards}) p_net = Policy_Net(config)
observation = np.array([[0.1, 0.1, 0.1, 0.1]]) a = time.time()
for _ in range(10000*100):
p_net.action_prob(observation)
b = time.time()
print(b-a)
A操作在GPU上时,A操作运行时间:
264.3311233520508秒
264.20179986953735
CPU利用率:

GPU利用率:

A操作在CPU上时,A操作运行时间:
90.15146541595459秒
90.39280557632446秒
CPU利用率:

GPU利用率: 0%
可以看到A操作在CPU上运行的效率为在GPU上运行的 2.93倍,在CPU上运行A操作效率更好。
********************************************
那么A操作和B操作一起操作,A操作在CPU和GPU上效率又会如何呢:(这里我们对B操作进行模拟,也就是在每次迭代更新时增加在CPU上的运算量即可)
代码:
import tensorflow as tf
import numpy as np
import time flags = tf.app.flags
flags.DEFINE_integer('D', 4, '输入层维度')
flags.DEFINE_integer('H', 50, '隐藏层维度')
flags.DEFINE_float('learning_rate', 1e-4, '学习率')
config = flags.FLAGS """
这个module是对神经网络的定义
"""
import tensorflow as tf class Policy_Net(object):
def __init__(self, config):
self.learning_rate = config.learning_rate # 1e-2
self.D = config.D # 4 输入向量维度
self.H = config.H # 50 隐藏层维度
# 设置新的graph
self.graph = tf.Graph()
# 设置显存的上限大小
gpu_options = tf.GPUOptions(allow_growth=True) # 按照计算需求动态申请内存
# 设置新的session
self.sess = tf.Session(graph=self.graph, config=tf.ConfigProto(gpu_options=gpu_options)) self.net_build() # 构建网络
self.sess.run(self.op_init) # 全局变量初始化 def net_build(self): # 构建网络
with self.graph.as_default():
observations = tf.placeholder(tf.float32, [None, self.D], name="input_states") # 传入的观测到的状态tensor
actions = tf.placeholder(tf.float32, [None, 1], name="input_actions")
advantages = tf.placeholder(tf.float32, [None, 1], name="reward_signal") # 根据策略网络计算出选动作action_0的概率probability, action_1的概率为1-probability
w1 = tf.get_variable("w1", shape=[self.D, self.H],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable("b1", shape=[self.H], initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.add(tf.matmul(observations, w1), b1))
w2 = tf.get_variable("w2", shape=[self.H, 1],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable("b2", shape=[1], initializer=tf.constant_initializer(0.0))
score = tf.add(tf.matmul(layer1, w2), b2)
""" probability为选择action=2 的概率, action=1的选择概率为 1-probability """
probability = tf.nn.sigmoid(score) # 动作0的actions=0, 动作1的actions=1 # advantages 为选择动作actions后所得到的累计折扣奖励
loglik = tf.log(actions * (actions - probability) + (1 - actions) * (actions + probability))
# loss为一个episode内所有observation,actions,advantages得到的损失的均值,reduce_mean
loss = -tf.reduce_mean(loglik * advantages) trainable_vars = tf.trainable_variables() # 获得图内需要训练的 variables
# 设置batch更新trainable_variables的placeholder
batchGrad = []
for var in tf.trainable_variables():
var_name = "batch_" + var.name.split(":")[0]
batchGrad.append(tf.placeholder(tf.float32, name=var_name)) newGrads = tf.gradients(loss, trainable_vars) # 获得loss对于图内需要训练的 variables 的梯度
adam = tf.train.AdamOptimizer(learning_rate=self.learning_rate) # 优化器
# 定义对参数 tvars 进行梯度更新的操作, 使用adam优化器对参数进行更新
updateGrads = adam.apply_gradients(zip(batchGrad, trainable_vars))
# 直接优化
self.opt = adam.minimize(loss) self.op_init = tf.global_variables_initializer()
self.observations = observations
self.actions = actions
self.advantages = advantages
self.batchGrad = batchGrad
self.probability = probability
self.trainable_vars = trainable_vars
self.newGrads = newGrads
self.updateGrads = updateGrads def grad_buffer(self):
return self.sess.run(self.trainable_vars) def action_prob(self, input_x):
act_prob = self.sess.run(self.probability, feed_dict={self.observations: input_x})
return act_prob def new_grads(self, observations, actions, discounted_rewards):
# 返回神经网络各参数对应loss的梯度
n_grads = self.sess.run(self.newGrads, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards})
return n_grads def update_grads(self, input_gradBuffer):
self.sess.run(self.updateGrads, feed_dict=dict(zip(self.batchGrad, input_gradBuffer))) def update_opt(self, observations, actions, discounted_rewards):
self.sess.run(self.opt, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards}) p_net = Policy_Net(config) a = time.time()
for _ in range(10000*100):
observation = np.random.normal(size=[1, 4])
observation= observation*observation+np.matmul(observation, observation.transpose())
p_net.action_prob(observation)
b = time.time()
print(b-a)
A操作在GPU上时,A、B操作的运算情况:
用时:
307.19570112228394
312.24832940101624
CPU上利用率:

GPU上利用率:

A操作在CPU上时,A、B操作的运算情况:
用时:
104.759694814682
106.24265789985657
CPU上利用率:

GPU上利用率:0%
=========================================
假如我们不考虑A、B操作,只考虑C操作,那么是使用CPU还是GPU呢?
代码:
import tensorflow as tf
import numpy as np
import time flags = tf.app.flags
flags.DEFINE_integer('D', 4, '输入层维度')
flags.DEFINE_integer('H', 50, '隐藏层维度')
flags.DEFINE_float('learning_rate', 1e-4, '学习率')
config = flags.FLAGS """
这个module是对神经网络的定义
"""
import tensorflow as tf class Policy_Net(object):
def __init__(self, config):
self.learning_rate = config.learning_rate # 1e-2
self.D = config.D # 4 输入向量维度
self.H = config.H # 50 隐藏层维度
# 设置新的graph
self.graph = tf.Graph()
# 设置显存的上限大小
gpu_options = tf.GPUOptions(allow_growth=True) # 按照计算需求动态申请内存
# 设置新的session
self.sess = tf.Session(graph=self.graph, config=tf.ConfigProto(gpu_options=gpu_options)) self.net_build() # 构建网络
self.sess.run(self.op_init) # 全局变量初始化 def net_build(self): # 构建网络
with self.graph.as_default():
observations = tf.placeholder(tf.float32, [None, self.D], name="input_states") # 传入的观测到的状态tensor
actions = tf.placeholder(tf.float32, [None, 1], name="input_actions")
advantages = tf.placeholder(tf.float32, [None, 1], name="reward_signal") # 根据策略网络计算出选动作action_0的概率probability, action_1的概率为1-probability
w1 = tf.get_variable("w1", shape=[self.D, self.H],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable("b1", shape=[self.H], initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.add(tf.matmul(observations, w1), b1))
w2 = tf.get_variable("w2", shape=[self.H, 1],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable("b2", shape=[1], initializer=tf.constant_initializer(0.0))
score = tf.add(tf.matmul(layer1, w2), b2)
""" probability为选择action=2 的概率, action=1的选择概率为 1-probability """
probability = tf.nn.sigmoid(score) # 动作0的actions=0, 动作1的actions=1 # advantages 为选择动作actions后所得到的累计折扣奖励
loglik = tf.log(actions * (actions - probability) + (1 - actions) * (actions + probability))
# loss为一个episode内所有observation,actions,advantages得到的损失的均值,reduce_mean
loss = -tf.reduce_mean(loglik * advantages) trainable_vars = tf.trainable_variables() # 获得图内需要训练的 variables
# 设置batch更新trainable_variables的placeholder
batchGrad = []
for var in tf.trainable_variables():
var_name = "batch_" + var.name.split(":")[0]
batchGrad.append(tf.placeholder(tf.float32, name=var_name)) newGrads = tf.gradients(loss, trainable_vars) # 获得loss对于图内需要训练的 variables 的梯度
adam = tf.train.AdamOptimizer(learning_rate=self.learning_rate) # 优化器
# 定义对参数 tvars 进行梯度更新的操作, 使用adam优化器对参数进行更新
updateGrads = adam.apply_gradients(zip(batchGrad, trainable_vars))
# 直接优化
self.opt = adam.minimize(loss) self.op_init = tf.global_variables_initializer()
self.observations = observations
self.actions = actions
self.advantages = advantages
self.batchGrad = batchGrad
self.probability = probability
self.trainable_vars = trainable_vars
self.newGrads = newGrads
self.updateGrads = updateGrads def grad_buffer(self):
return self.sess.run(self.trainable_vars) def action_prob(self, input_x):
act_prob = self.sess.run(self.probability, feed_dict={self.observations: input_x})
return act_prob def new_grads(self, observations, actions, discounted_rewards):
# 返回神经网络各参数对应loss的梯度
n_grads = self.sess.run(self.newGrads, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards})
return n_grads def update_grads(self, input_gradBuffer):
self.sess.run(self.updateGrads, feed_dict=dict(zip(self.batchGrad, input_gradBuffer))) def update_opt(self, observations, actions, discounted_rewards):
self.sess.run(self.opt, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards}) p_net = Policy_Net(config)
exp_observation = np.random.normal(size=(32, 4))
exp_action = np.random.randint(2, size=[32, 1])*1.0
exp_reward = np.random.randint(99, size=[32, 1])*1.0
a = time.time()
for _ in range(10000*100):
"""
observation = np.random.normal(size=[1, 4])
observation= observation*observation+np.matmul(observation, observation.transpose())
p_net.action_prob(observation)
"""
p_net.update_opt(exp_observation, exp_action, exp_reward)
b = time.time()
print(b-a)
C操作在CPU上:
用时:
221.16503357887268
218.87172484397888
CPU利用率:

GPU利用率: 0%
C操作只在GPU上:
用时:
523.3830518722534
CPU利用率:

GPU利用率:

可以看到如果网络结构过于简单并且输入数据过于小时,C操作在CPU上运行的效率高于GPU上。
如果我们加大输入数据的大小呢,每次训练使用较大数据量呢?
import tensorflow as tf
import numpy as np
import time flags = tf.app.flags
flags.DEFINE_integer('D', 4, '输入层维度')
flags.DEFINE_integer('H', 50, '隐藏层维度')
flags.DEFINE_float('learning_rate', 1e-4, '学习率')
config = flags.FLAGS """
这个module是对神经网络的定义
"""
import tensorflow as tf class Policy_Net(object):
def __init__(self, config):
self.learning_rate = config.learning_rate # 1e-2
self.D = config.D # 4 输入向量维度
self.H = config.H # 50 隐藏层维度
# 设置新的graph
self.graph = tf.Graph()
# 设置显存的上限大小
gpu_options = tf.GPUOptions(allow_growth=True) # 按照计算需求动态申请内存
# 设置新的session
self.sess = tf.Session(graph=self.graph, config=tf.ConfigProto(gpu_options=gpu_options)) self.net_build() # 构建网络
self.sess.run(self.op_init) # 全局变量初始化 def net_build(self): # 构建网络
with self.graph.as_default():
observations = tf.placeholder(tf.float32, [None, self.D], name="input_states") # 传入的观测到的状态tensor
actions = tf.placeholder(tf.float32, [None, 1], name="input_actions")
advantages = tf.placeholder(tf.float32, [None, 1], name="reward_signal") # 根据策略网络计算出选动作action_0的概率probability, action_1的概率为1-probability
w1 = tf.get_variable("w1", shape=[self.D, self.H],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable("b1", shape=[self.H], initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.add(tf.matmul(observations, w1), b1))
w2 = tf.get_variable("w2", shape=[self.H, 1],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable("b2", shape=[1], initializer=tf.constant_initializer(0.0))
score = tf.add(tf.matmul(layer1, w2), b2)
""" probability为选择action=2 的概率, action=1的选择概率为 1-probability """
probability = tf.nn.sigmoid(score) # 动作0的actions=0, 动作1的actions=1 # advantages 为选择动作actions后所得到的累计折扣奖励
loglik = tf.log(actions * (actions - probability) + (1 - actions) * (actions + probability))
# loss为一个episode内所有observation,actions,advantages得到的损失的均值,reduce_mean
loss = -tf.reduce_mean(loglik * advantages) trainable_vars = tf.trainable_variables() # 获得图内需要训练的 variables
# 设置batch更新trainable_variables的placeholder
batchGrad = []
for var in tf.trainable_variables():
var_name = "batch_" + var.name.split(":")[0]
batchGrad.append(tf.placeholder(tf.float32, name=var_name)) newGrads = tf.gradients(loss, trainable_vars) # 获得loss对于图内需要训练的 variables 的梯度
adam = tf.train.AdamOptimizer(learning_rate=self.learning_rate) # 优化器
# 定义对参数 tvars 进行梯度更新的操作, 使用adam优化器对参数进行更新
updateGrads = adam.apply_gradients(zip(batchGrad, trainable_vars))
# 直接优化
self.opt = adam.minimize(loss) self.op_init = tf.global_variables_initializer()
self.observations = observations
self.actions = actions
self.advantages = advantages
self.batchGrad = batchGrad
self.probability = probability
self.trainable_vars = trainable_vars
self.newGrads = newGrads
self.updateGrads = updateGrads def grad_buffer(self):
return self.sess.run(self.trainable_vars) def action_prob(self, input_x):
act_prob = self.sess.run(self.probability, feed_dict={self.observations: input_x})
return act_prob def new_grads(self, observations, actions, discounted_rewards):
# 返回神经网络各参数对应loss的梯度
n_grads = self.sess.run(self.newGrads, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards})
return n_grads def update_grads(self, input_gradBuffer):
self.sess.run(self.updateGrads, feed_dict=dict(zip(self.batchGrad, input_gradBuffer))) def update_opt(self, observations, actions, discounted_rewards):
self.sess.run(self.opt, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards}) p_net = Policy_Net(config)
exp_observation = np.random.normal(size=(8096, 4))
exp_action = np.random.randint(2, size=[8096, 1])*1.0
exp_reward = np.random.randint(99, size=[8096, 1])*1.0
a = time.time()
for _ in range(10000*100):
"""
observation = np.random.normal(size=[1, 4])
observation= observation*observation+np.matmul(observation, observation.transpose())
p_net.action_prob(observation)
"""
p_net.update_opt(exp_observation, exp_action, exp_reward)
b = time.time()
print(b-a)
C操作只在GPU上:
用时:
669.1641449928284
CPU利用率:

GPU利用率:

C操作只在CPU上:
用时:
914.7391726970673
CPU利用率:

GPU利用率:0%
可以看到C操作部分只有当数据量较大(batch_size较大时)或者神经网络较深(网络较复杂时),使用GPU操作要优于使用CPU操作的,而在决策学习中(强化学习)这两点有时是难以满足的。如果batch数据较小或者网络较为简单时我们使用CPU端进行计算会更加高效。
===============================================
最后我们将A、B、C操作联合在一起,这也是一个完整决策学习的标准过程,我们看看将A、C操作反正CPU上还是GPU上速度更快。这里我们将C操作分为batch数据较大和较小两种情况来考察:
------------------------
batch数据较小情况:(batch_size 为32)
代码:
import tensorflow as tf
import numpy as np
import time flags = tf.app.flags
flags.DEFINE_integer('D', 4, '输入层维度')
flags.DEFINE_integer('H', 50, '隐藏层维度')
flags.DEFINE_float('learning_rate', 1e-4, '学习率')
config = flags.FLAGS """
这个module是对神经网络的定义
"""
import tensorflow as tf class Policy_Net(object):
def __init__(self, config):
self.learning_rate = config.learning_rate # 1e-2
self.D = config.D # 4 输入向量维度
self.H = config.H # 50 隐藏层维度
# 设置新的graph
self.graph = tf.Graph()
# 设置显存的上限大小
gpu_options = tf.GPUOptions(allow_growth=True) # 按照计算需求动态申请内存
# 设置新的session
self.sess = tf.Session(graph=self.graph, config=tf.ConfigProto(gpu_options=gpu_options)) self.net_build() # 构建网络
self.sess.run(self.op_init) # 全局变量初始化 def net_build(self): # 构建网络
with self.graph.as_default():
observations = tf.placeholder(tf.float32, [None, self.D], name="input_states") # 传入的观测到的状态tensor
actions = tf.placeholder(tf.float32, [None, 1], name="input_actions")
advantages = tf.placeholder(tf.float32, [None, 1], name="reward_signal") # 根据策略网络计算出选动作action_0的概率probability, action_1的概率为1-probability
w1 = tf.get_variable("w1", shape=[self.D, self.H],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable("b1", shape=[self.H], initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.add(tf.matmul(observations, w1), b1))
w2 = tf.get_variable("w2", shape=[self.H, 1],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable("b2", shape=[1], initializer=tf.constant_initializer(0.0))
score = tf.add(tf.matmul(layer1, w2), b2)
""" probability为选择action=2 的概率, action=1的选择概率为 1-probability """
probability = tf.nn.sigmoid(score) # 动作0的actions=0, 动作1的actions=1 # advantages 为选择动作actions后所得到的累计折扣奖励
loglik = tf.log(actions * (actions - probability) + (1 - actions) * (actions + probability))
# loss为一个episode内所有observation,actions,advantages得到的损失的均值,reduce_mean
loss = -tf.reduce_mean(loglik * advantages) trainable_vars = tf.trainable_variables() # 获得图内需要训练的 variables
# 设置batch更新trainable_variables的placeholder
batchGrad = []
for var in tf.trainable_variables():
var_name = "batch_" + var.name.split(":")[0]
batchGrad.append(tf.placeholder(tf.float32, name=var_name)) newGrads = tf.gradients(loss, trainable_vars) # 获得loss对于图内需要训练的 variables 的梯度
adam = tf.train.AdamOptimizer(learning_rate=self.learning_rate) # 优化器
# 定义对参数 tvars 进行梯度更新的操作, 使用adam优化器对参数进行更新
updateGrads = adam.apply_gradients(zip(batchGrad, trainable_vars))
# 直接优化
self.opt = adam.minimize(loss) self.op_init = tf.global_variables_initializer()
self.observations = observations
self.actions = actions
self.advantages = advantages
self.batchGrad = batchGrad
self.probability = probability
self.trainable_vars = trainable_vars
self.newGrads = newGrads
self.updateGrads = updateGrads def grad_buffer(self):
return self.sess.run(self.trainable_vars) def action_prob(self, input_x):
act_prob = self.sess.run(self.probability, feed_dict={self.observations: input_x})
return act_prob def new_grads(self, observations, actions, discounted_rewards):
# 返回神经网络各参数对应loss的梯度
n_grads = self.sess.run(self.newGrads, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards})
return n_grads def update_grads(self, input_gradBuffer):
self.sess.run(self.updateGrads, feed_dict=dict(zip(self.batchGrad, input_gradBuffer))) def update_opt(self, observations, actions, discounted_rewards):
self.sess.run(self.opt, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards}) batch_size = 32
p_net = Policy_Net(config)
exp_observation = np.random.normal(size=(batch_size, 4))
exp_action = np.random.randint(2, size=[batch_size, 1])*1.0
exp_reward = np.random.randint(99, size=[batch_size, 1])*1.0
a = time.time()
for _ in range(10000*100): observation = np.random.normal(size=[1, 4])
observation= observation*observation+np.matmul(observation, observation.transpose())
p_net.action_prob(observation) p_net.update_opt(exp_observation, exp_action, exp_reward)
b = time.time()
print(b-a)
A、C操作在CPU上时:
用时:
403.56523847579956
CPU利用率:

GPU利用率: 0%
A、C操作在GPU上时:
用时:
915.9552888870239
CPU利用率:

GPU利用率:

------------------------
batch数据较大情况:(batch_size 为8096)
代码:
import tensorflow as tf
import numpy as np
import time flags = tf.app.flags
flags.DEFINE_integer('D', 4, '输入层维度')
flags.DEFINE_integer('H', 50, '隐藏层维度')
flags.DEFINE_float('learning_rate', 1e-4, '学习率')
config = flags.FLAGS """
这个module是对神经网络的定义
"""
import tensorflow as tf class Policy_Net(object):
def __init__(self, config):
self.learning_rate = config.learning_rate # 1e-2
self.D = config.D # 4 输入向量维度
self.H = config.H # 50 隐藏层维度
# 设置新的graph
self.graph = tf.Graph()
# 设置显存的上限大小
gpu_options = tf.GPUOptions(allow_growth=True) # 按照计算需求动态申请内存
# 设置新的session
self.sess = tf.Session(graph=self.graph, config=tf.ConfigProto(gpu_options=gpu_options)) self.net_build() # 构建网络
self.sess.run(self.op_init) # 全局变量初始化 def net_build(self): # 构建网络
with self.graph.as_default():
observations = tf.placeholder(tf.float32, [None, self.D], name="input_states") # 传入的观测到的状态tensor
actions = tf.placeholder(tf.float32, [None, 1], name="input_actions")
advantages = tf.placeholder(tf.float32, [None, 1], name="reward_signal") # 根据策略网络计算出选动作action_0的概率probability, action_1的概率为1-probability
w1 = tf.get_variable("w1", shape=[self.D, self.H],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable("b1", shape=[self.H], initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.add(tf.matmul(observations, w1), b1))
w2 = tf.get_variable("w2", shape=[self.H, 1],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable("b2", shape=[1], initializer=tf.constant_initializer(0.0))
score = tf.add(tf.matmul(layer1, w2), b2)
""" probability为选择action=2 的概率, action=1的选择概率为 1-probability """
probability = tf.nn.sigmoid(score) # 动作0的actions=0, 动作1的actions=1 # advantages 为选择动作actions后所得到的累计折扣奖励
loglik = tf.log(actions * (actions - probability) + (1 - actions) * (actions + probability))
# loss为一个episode内所有observation,actions,advantages得到的损失的均值,reduce_mean
loss = -tf.reduce_mean(loglik * advantages) trainable_vars = tf.trainable_variables() # 获得图内需要训练的 variables
# 设置batch更新trainable_variables的placeholder
batchGrad = []
for var in tf.trainable_variables():
var_name = "batch_" + var.name.split(":")[0]
batchGrad.append(tf.placeholder(tf.float32, name=var_name)) newGrads = tf.gradients(loss, trainable_vars) # 获得loss对于图内需要训练的 variables 的梯度
adam = tf.train.AdamOptimizer(learning_rate=self.learning_rate) # 优化器
# 定义对参数 tvars 进行梯度更新的操作, 使用adam优化器对参数进行更新
updateGrads = adam.apply_gradients(zip(batchGrad, trainable_vars))
# 直接优化
self.opt = adam.minimize(loss) self.op_init = tf.global_variables_initializer()
self.observations = observations
self.actions = actions
self.advantages = advantages
self.batchGrad = batchGrad
self.probability = probability
self.trainable_vars = trainable_vars
self.newGrads = newGrads
self.updateGrads = updateGrads def grad_buffer(self):
return self.sess.run(self.trainable_vars) def action_prob(self, input_x):
act_prob = self.sess.run(self.probability, feed_dict={self.observations: input_x})
return act_prob def new_grads(self, observations, actions, discounted_rewards):
# 返回神经网络各参数对应loss的梯度
n_grads = self.sess.run(self.newGrads, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards})
return n_grads def update_grads(self, input_gradBuffer):
self.sess.run(self.updateGrads, feed_dict=dict(zip(self.batchGrad, input_gradBuffer))) def update_opt(self, observations, actions, discounted_rewards):
self.sess.run(self.opt, feed_dict={self.observations: observations, \
self.actions: actions, self.advantages: discounted_rewards}) batch_size = 8096
p_net = Policy_Net(config)
exp_observation = np.random.normal(size=(batch_size, 4))
exp_action = np.random.randint(2, size=[batch_size, 1])*1.0
exp_reward = np.random.randint(99, size=[batch_size, 1])*1.0
a = time.time()
for _ in range(10000*100): observation = np.random.normal(size=[1, 4])
observation= observation*observation+np.matmul(observation, observation.transpose())
p_net.action_prob(observation) p_net.update_opt(exp_observation, exp_action, exp_reward)
b = time.time()
print(b-a)
A、C操作在CPU上时:
用时:
1069.901896238327
CPU利用率:

GPU利用率: 0%
A、C操作在GPU上时:
用时:
1042.1329367160797
CPU利用率:

GPU利用率:

===============================================
总结:
CPU上运行TensorFlow,由于CPU并行能力弱于GPU,如果数据的计算量较大并且能很好的进行并行化,那么GPU的运算效果优于CPU。但是如果计算量较小并且不能很好的并行化(或者只能串行话),那么由于CPU的串行运算能力优于GPU,此时使用CPU运算效果将会由于GPU。
根据上面对决策学习的分析,如果再更新网络时使用较少数据或者网络过于简单,那么在CPU上进行运算将会优于在GPU上进行运算,而在决策学习中该种情况更为常见,也就是说在决策学习(强化学习)中使用CPU计算往往会优于使用GPU进行运算。
从上面的分析来看如何在强化学习中更好的提高运算速度并且不影响模型效果是一个有实际价值的事情。
===========================================
深度学习中使用TensorFlow或Pytorch框架时到底是应该使用CPU还是GPU来进行运算???的更多相关文章
- 常用深度学习框——Caffe/ TensorFlow / Keras/ PyTorch/MXNet
常用深度学习框--Caffe/ TensorFlow / Keras/ PyTorch/MXNet 一.概述 近几年来,深度学习的研究和应用的热潮持续高涨,各种开源深度学习框架层出不穷,包括Tenso ...
- 深度学习利器:TensorFlow在智能终端中的应用——智能边缘计算,云端生成模型给移动端下载,然后用该模型进行预测
前言 深度学习在图像处理.语音识别.自然语言处理领域的应用取得了巨大成功,但是它通常在功能强大的服务器端进行运算.如果智能手机通过网络远程连接服务器,也可以利用深度学习技术,但这样可能会很慢,而且只有 ...
- 问题集录--新手入门深度学习,选择TensorFlow 好吗?
新手入门深度学习,选择 TensorFlow 有哪些益处? 佟达:首先,对于新手来说,TensorFlow的环境配置包装得真心非常好.相较之下,安装Caffe要痛苦的多,如果还要再CUDA环境下配合O ...
- 针对深度学习(神经网络)的AI框架调研
针对深度学习(神经网络)的AI框架调研 在我们的AI安全引擎中未来会使用深度学习(神经网络),后续将引入AI芯片,因此重点看了下业界AI芯片厂商和对应芯片的AI框架,包括Intel(MKL CPU). ...
- 英特尔与 Facebook 合作采用第三代英特尔® 至强® 可扩展处理器和支持 BFloat16 加速的英特尔® 深度学习加速技术,提高 PyTorch 性能
英特尔与 Facebook 曾联手合作,在多卡训练工作负载中验证了 BFloat16 (BF16) 的优势:在不修改训练超参数的情况下,BFloat16 与单精度 32 位浮点数 (FP32) 得到了 ...
- 人工智能不过尔尔,基于Python3深度学习库Keras/TensorFlow打造属于自己的聊天机器人(ChatRobot)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_178 聊天机器人(ChatRobot)的概念我们并不陌生,也许你曾经在百无聊赖之下和Siri打情骂俏过,亦或是闲暇之余与小爱同学谈 ...
- 浅谈深度学习中的激活函数 - The Activation Function in Deep Learning
原文地址:http://www.cnblogs.com/rgvb178/p/6055213.html版权声明:本文为博主原创文章,未经博主允许不得转载. 激活函数的作用 首先,激活函数不是真的要去激活 ...
- The Activation Function in Deep Learning 浅谈深度学习中的激活函数
原文地址:http://www.cnblogs.com/rgvb178/p/6055213.html 版权声明:本文为博主原创文章,未经博主允许不得转载. 激活函数的作用 首先,激活函数不是真的要去激 ...
- 《深度学习原理与TensorFlow实践》喻俨,莫瑜
1. 深度学习简介 2. TensorFlow系统介绍 3. Hello TensorFlow 4. CNN看懂世界 5. RNN能说会道 6. CNN LSTM看图说话 7. 损失函数与优化算法 T ...
- 深度学习中GPU和显存分析
刚入门深度学习时,没有显存的概念,后来在实验中才渐渐建立了这个意识. 下面这篇文章很好的对GPU和显存总结了一番,于是我转载了过来. 作者:陈云 链接:https://zhuanlan.zhihu. ...
随机推荐
- fontawesome-webfont.woff:1 Failed to load resource: the server responded with a status of 404 ()
fontawesome-webfont.woff2:1 Failed to load resource: the server responded with a status of 404 ()fon ...
- 编程语言界的丐帮 C#.NET FRAMEWORK 4.6 EF 连接MYSQL
1.nuget 引用 EntityFramework .和 MySql.Data.EntityFramework. EntityFramework 版本:6.4.4,MySql.Data.Entit ...
- LNMP单机架构
黄金架构LNMP LNMP是网站架构初期最合适的单体架构.因为初创型技术团队对于技术的选型,需要考虑如下因素 在创业初期,研发资源有限,研发人力有限,技术储备有限,需要选择一个易维护.简单的技术架构: ...
- Spring源码——ConfigurationClassPostProcessor类
引言 Spring容器中提供很多方便的注解供我们在工作中使用,比如@Configuration注解,里面可以在方法上定义@Bean注解,将调用方法返回的对象交由Bean容器进行管理,那么Spring框 ...
- 爬虫、Selenium、webUI自动化使用PIL+pytesseract识别验证码以及识别错误解决方案
背景:大家在做爬虫或web端的UI自动化时会经常遇到的就是验证码,那怎么识别这验证码也是我们目前遇到的难题.(在这里咱们先不讨论:1.点击类的验证 2.滑动类的验证 3.中文类的验证)简单地说,计算机 ...
- python 将查询到数据,处理成包含列名和数据的字典类型数据
try: self.connect_dbserver() self.cursor.execute(sql) res = self.cursor.fetchall() # 返回的是数组的类型 print ...
- Git配置环境变量
由于学习需要装了git,使用终端查看版本号时 提示 'git' 不是内部或外部命令,也不是可运行的程序 或批处理文件. 原因 因为没有配置Git环境变量 解决方法:配置环境变量 开始菜单=>设置 ...
- 实验6.交换机MAC地址表简单实验
# 实验6.交换机Mac地址表 本实验用于验证和测试交换机的Mac地址表的特性. 实验组 测试 测试在PC1没有pingPC2时,此时mac表为空 当PC1ping一个其他的ip而不是PC2时,无论是 ...
- shell 根据 指定列 进行 去除 重复行
根据指定列进行去除重复行 这里的重复是指如果两行的某一列数据相同,则认为是重复数据. 例如:第1行与第2行数据,其中的第2列(以- 作为分隔符)明显是重复的. 100069 - ARM Compile ...
- qt中的 connect 函数
1.connect()函数实现的是信号与槽的关联. 注意:只有QO bject类及其派生的类才能使用信号和槽的机制 2.函数原型 static QMetaObject::Connection conn ...