Lucene实现自己的英文空格小写分词器
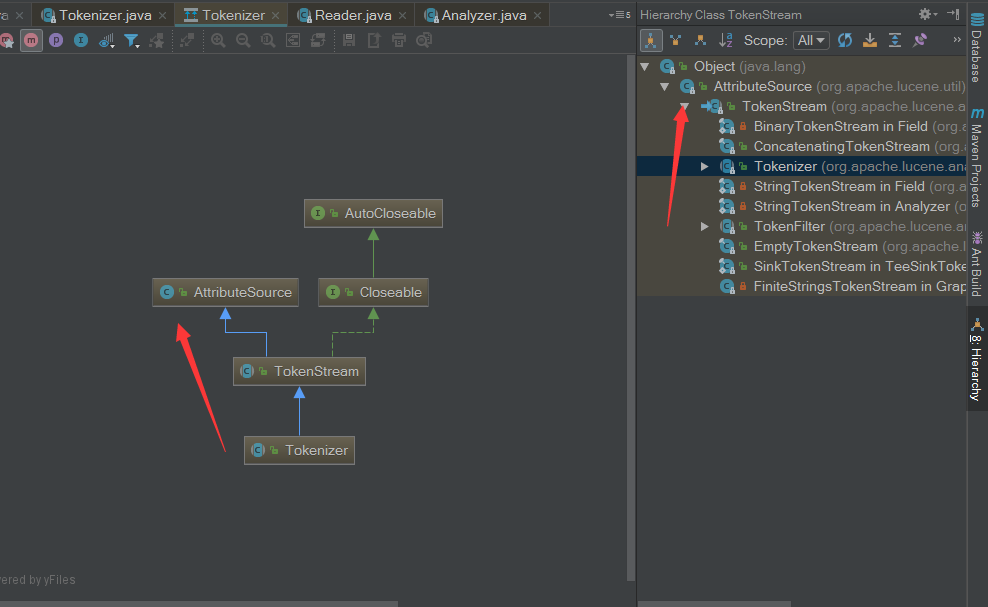
看一下继承图,Tokenizer和TokenFilter都是继承于TokenStream,TokenStream继承了AttributeSource
package com.lucene.demo.analizer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.util.Attribute;
import org.apache.lucene.util.AttributeImpl;
import org.apache.lucene.util.AttributeReflector;
import java.io.IOException;
public class SansamAnalyzer extends Analyzer{
/**
*
*/
@Override
protected TokenStreamComponents createComponents(String fieldName) {
//装饰器模式,将分出的词项用filter进行处理,可以链式装饰实现多个filter
MyTokenizer myTokenizer = new MyTokenizer();
MyLowerCaseTokenFilter myLowerCaseTokenFilter = new MyLowerCaseTokenFilter(myTokenizer);
return new TokenStreamComponents(myTokenizer, myLowerCaseTokenFilter);
}
public static class MyTokenizer extends Tokenizer{
//调用AttributeSource-addAttribute方法
//维护了一个attributes Map,实现可复用
//private final Map<Class<? extends Attribute>, AttributeImpl> attributes;
//private final Map<Class<? extends AttributeImpl>, AttributeImpl> attributeImpls;
MyAttribute attribute = this.addAttribute(MyAttribute.class);
char[] buffer = new char[255];
int length = 0;
int c;
@Override
public boolean incrementToken() throws IOException {
//进行分析处理逻辑
clearAttributes();
length = 0;
while (true){
c = this.input.read();
if(c == -1){
if(length > 0){
this.attribute.setChar(buffer,length);
return true;
}else {
return false;
}
}
if(Character.isWhitespace(c)){
if(length > 0){
this.attribute.setChar(buffer,length);
return true;
}
}
buffer[length++] = (char)c;
}
}
}
public static class MyLowerCaseTokenFilter extends TokenFilter{
public MyLowerCaseTokenFilter(TokenStream s){
super(s);
}
MyAttribute attribute = this.addAttribute(MyAttribute.class);
@Override
public boolean incrementToken() throws IOException {
//获取一个分词项进行处理
boolean b = this.input.incrementToken();
if (b){
char[] chars = this.attribute.getChar();
int length = this.attribute.getLength();
if(length > 0){
for (int i = 0; i < length; i++) {
chars[i] = Character.toLowerCase(chars[i]);
}
}
}
return b;
}
}
/**
* 自定义Attribute属性接口 继承Attribute
*/
public static interface MyAttribute extends Attribute {
void setChar(char [] c, int length);
char [] getChar();
int getLength();
String getString();
}
/**
* 必须使用interface+Impl 继承AttributeImpl
*/
public static class MyAttributeImpl extends AttributeImpl implements MyAttribute {
char [] term = new char[255];
int length = 0;
@Override
public void setChar(char[] c, int length) {
this.length = length;
if(c.length > 0){
System.arraycopy(c,0,term,0,length);
}
}
@Override
public char[] getChar() {
return term;
}
@Override
public int getLength() {
return length;
}
@Override
public String getString() {
if(length > 0){
return new String(term,0,length);
}
return null;
// return new String(term); //不能直接返回 因为长度问题 默认255字符
}
@Override
public void clear() {
term = null;
term = new char[255];
this.length = 0;
}
@Override
public void reflectWith(AttributeReflector reflector) {
}
@Override
public void copyTo(AttributeImpl target) {
}
}
public static void main(String[] args) {
String text = "Hello World A b C";
try(SansamAnalyzer analyzer = new SansamAnalyzer();
//调用tokenStream()时 会先得到TokenStreamComponents对象 得到了MyLowerCaseTokenFilter 对象 观察其构造方法及此方法的返回值
TokenStream stream = analyzer.tokenStream("title",text);){
MyAttribute attribute = stream.getAttribute(MyAttribute.class);
stream.reset();
while (stream.incrementToken()){
System.out.print(attribute.getString()+" | ");
}
stream.end();
}catch (Exception e){
e.printStackTrace();
}
}
}
Lucene实现自己的英文空格小写分词器的更多相关文章
- lucene整理3 -- 排序、过滤、分词器
1. 排序 1.1. Sort类 public Sort() public Sort(String field) public Sort(String field,Boolean reverse ...
- Lucene的中文分词器IKAnalyzer
分词器对英文的支持是非常好的. 一般分词经过的流程: 1)切分关键词 2)去除停用词 3)把英文单词转为小写 但是老外写的分词器对中文分词一般都是单字分词,分词的效果不好. 国人林良益写的IK Ana ...
- Lucene介绍及简单入门案例(集成ik分词器)
介绍 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和 ...
- elasticsearch 分析器 分词器
参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html 在全文搜索(Fu ...
- Elasticsearch之文档的增删改查以及ik分词器
文档的增删改查 增加文档 使用elasticsearch-head查看 修改文档 使用elasticsearch-head查看 删除文档 使用elasticsearch-head查看 查看文档的三种方 ...
- Restful认识和 IK分词器的使用
什么是Restful风格 Restful是一种面向资源的架构风格,可以简单理解为:使用URL定位资源,用HTTP动词(GET,POST,DELETE,PUT)描述操作. 使用Restful的好处: 透 ...
- IK分词器 原理分析 源码解析
IK分词器在是一款 基于词典和规则 的中文分词器.本文讲解的IK分词器是独立于elasticsearch.Lucene.solr,可以直接用在java代码中的部分.关于如何开发es分词插件,后续会有文 ...
- ElasticSearch-IK分词器和集成使用
1.查询存在问题分析 在进行字符串查询时,我们发现去搜索"搜索服务器"和"钢索"都可以搜索到数据: 而在进行词条查询时,我们搜索"搜索"却没 ...
- 三、Solr多核心及分词器(IK)配置
多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索,不使用多核也没问题,这样带来的问题是 ...
随机推荐
- pyqt5-数据库加载错误解决
1.无法连接postgresql 直接在pycharm上安装pyqt5没有QT这个文件夹, 在ancanda中装好使用. 切换加载环境,或者将第二个ptqt5拷贝替换第一个环境中的pyqt5
- DataGridView操作小记(1)
1.获取总列数 int Column_num = DataGridView1.ColumnCount; 2.获取总行数 int Column_num = DataGridView1.RowCount; ...
- sybase的ASE和IQ版本有什么区别
原文:ASE是sybase OLTP数据库,行式存储.IQ是Sybase OLAP和DSS的数据库,采用列式存储,适合数据仓库.数据集市等分析性应用,不符合并发压力大的联机场景.
- 剑指offer——包含min函数的栈
题目:定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的min函数(时间复杂度为O(1)) 该题是自己第一次采用编程的方式来实现Java中栈的功能,故直接借鉴了大牛的代码 import ...
- [SF] Symfony 标准 HttpFoundation\Request 实现分析
使用方式 /** * 如果直接示例化 Request 默认是没有参数的,可以自己传入 * 本方法将 PHP 超全局变量作为参数然后实例化自身(Request)进行初始化. */ $request = ...
- 第8章 IO库 自我综合练习
要求: 文本内容: Tom 11144455 12345678998 Jone 88888888 99999999999 1.将文本文件中的内容读入,并显示到屏幕上: 2.手动输入“Mary 77 ...
- CSS 布局术语
这一节的知识非常重要,它关系到能否做出漂亮的网站.下面的概念.术语需要好好理解. 构建块:CSS采用盒子模型来处理每个HTML元素.盒子可以是一个“块级”盒子,也可以是一个“内联”盒子. 包含元素:包 ...
- javaMail实现收发邮件(五)
控制台打印出的内容,我们无法阅读,其实,让我们自己来解析一封复杂的邮件是很不容易的,邮件里面格式.规范复杂得很.不过,我们所用的浏览器内置了解析各种数据类型的数据处理模块,我们只需要在把数据流传输给浏 ...
- Could not HEAD 'https://dl.google.com/dl/android/maven2/com/android/tools/build/gradle/3.2.0/gradle-3.2.0.pom'.
- ThinkPHP3.2 --- 中文乱码问题
在thinkphp中初次运行时 会出现中文乱码问题,解决方法也很简单 只需要在入口文件index.php加上这段代码即可: <?php header("Content-Type: te ...