ElasticSearch-IK分词器和集成使用
1.查询存在问题分析
在进行字符串查询时,我们发现去搜索"搜索服务器"和"钢索"都可以搜索到数据;
而在进行词条查询时,我们搜索"搜索"却没有搜索到数据;
究其原因是ElasticSearch的标准分词器导致的,当我们创建索引时,字段使用的是标准分词器:
如果使用ES搜索中文内容,默认是不支持中文分词,英文支持
例如:How are you!
How
are
you
!
例如:我是一个好男人!
我
是
一
个
好
男
人
!
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,
"index":false
},
"title": {
"type": "text",
"store": true,
"index":true,
"analyzer":"standard" //标准分词器 standard 内置的不支持中文分词
},
"content": {
"type": "text",
"store": true,
"index":true,
"analyzer":"standard" //标准分词器
}
}
}
}
}
例如对 "我是程序员" 进行分词
标准分词器分词效果测试:
GET http://localhost:9200/_analyze
{ "analyzer": "standard", "text": "我是程序员" }
分词结果:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "程",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "序",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
而我们需要的分词效果是:我、是、程序、程序员
这样的话就需要对中文支持良好的分析器的支持,支持中文分词的分词器有很多,word分词器、庖丁解牛、盘古分词、Ansj分词等,但我们常用的还是下面要介绍的IK分词器。
2.IK分词器简介
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
1)采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
2)采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
3)对中英联合支持不是很好,在这方面的处理比较麻烦.需再做一次查询,同时是支持个人词条的优化的词典存储,更小的内存占用。
4)支持用户词典扩展定义。
5)针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
3. IK分词器的安装
1)下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
课程资料也提供了IK分词器的压缩包:
 2)解压,将解压后的elasticsearch文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名文件夹为analysis-ik
2)解压,将解压后的elasticsearch文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名文件夹为analysis-ik
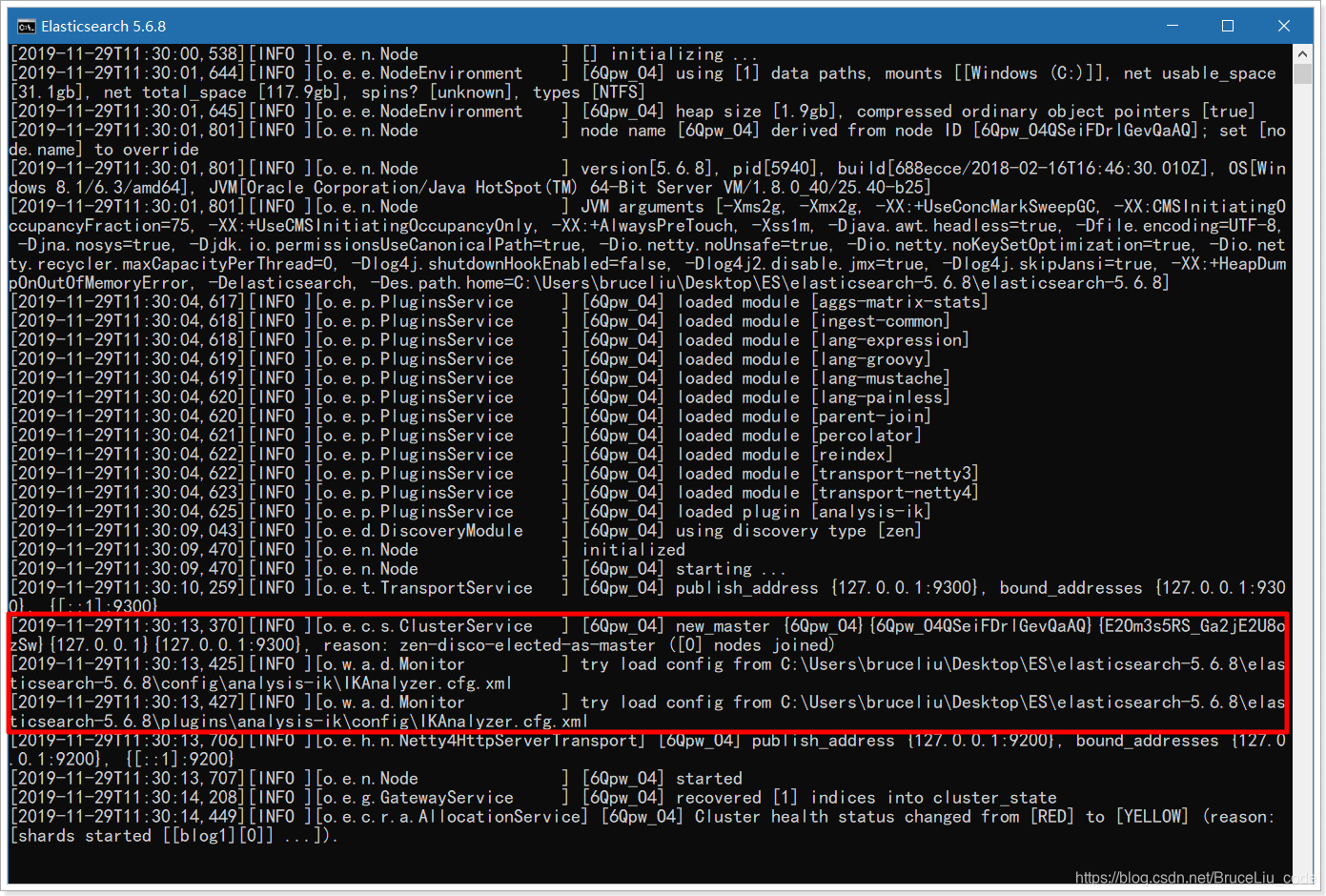
3)重新启动ElasticSearch,即可加载IK分词器
4.IK分词器测试
IK提供了两个分词算法ik_smart 和 ik_max_word
其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
我们分别来试一下
1)最小切分:在浏览器地址栏输入地址
GET http://localhost:9200/_analyze
{ "analyzer": "ik_smart", "text": "我是程序员" }
输出的结果为:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
2)最细切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员
输出的结果为:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "程序",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 4
}
]
}
6. 修改索引映射mapping
6.1 重建索引
删除原有blog1索引
DELETE localhost:9200/blog1
创建blog1索引,此时分词器使用ik_max_word
PUT localhost:9200/blog1
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,
"index":false
},
"title": {
"type": "text",
"store": true,
"index":true,
"analyzer":"ik_max_word"
},
"content": {
"type": "text",
"store": true,
"index":true,
"analyzer":"ik_max_word"
}
}
}
}
}
创建文档
POST localhost:9200/blog1/article/1
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。"
}
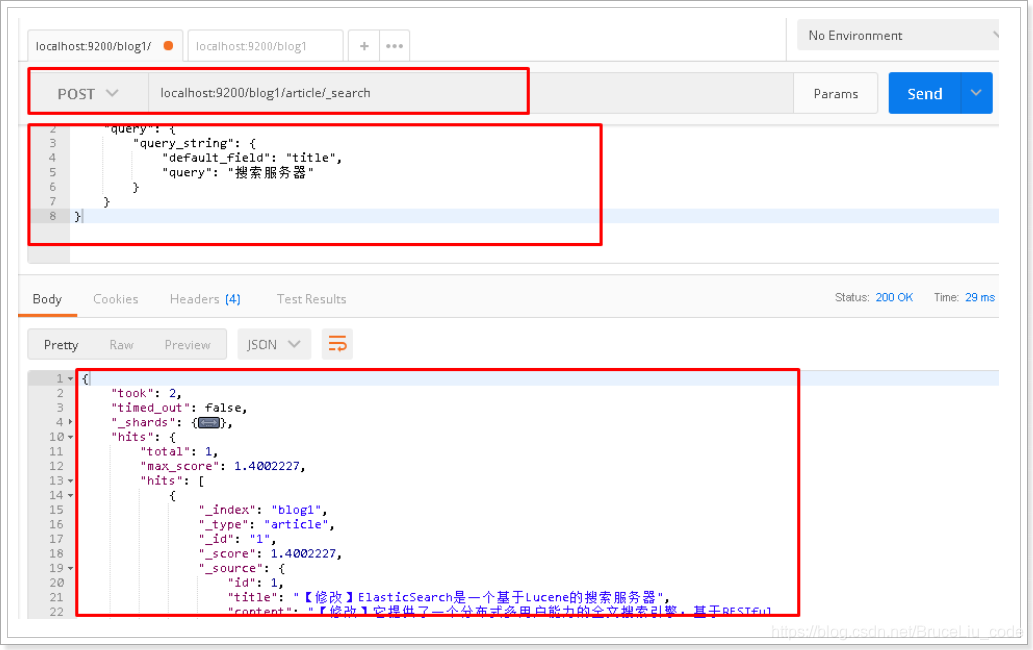
6.2 再次测试queryString查询
请求url:
POST localhost:9200/blog1/article/_search
请求体:
{
"query": {
"query_string": {
"default_field": "title",
"query": "搜索服务器"
}
}
}
postman截图:
将请求体搜索字符串修改为"钢索",再次查询:
{
"query": {
"query_string": {
"default_field": "title",
"query": "钢索"
}
}
}
postman截图: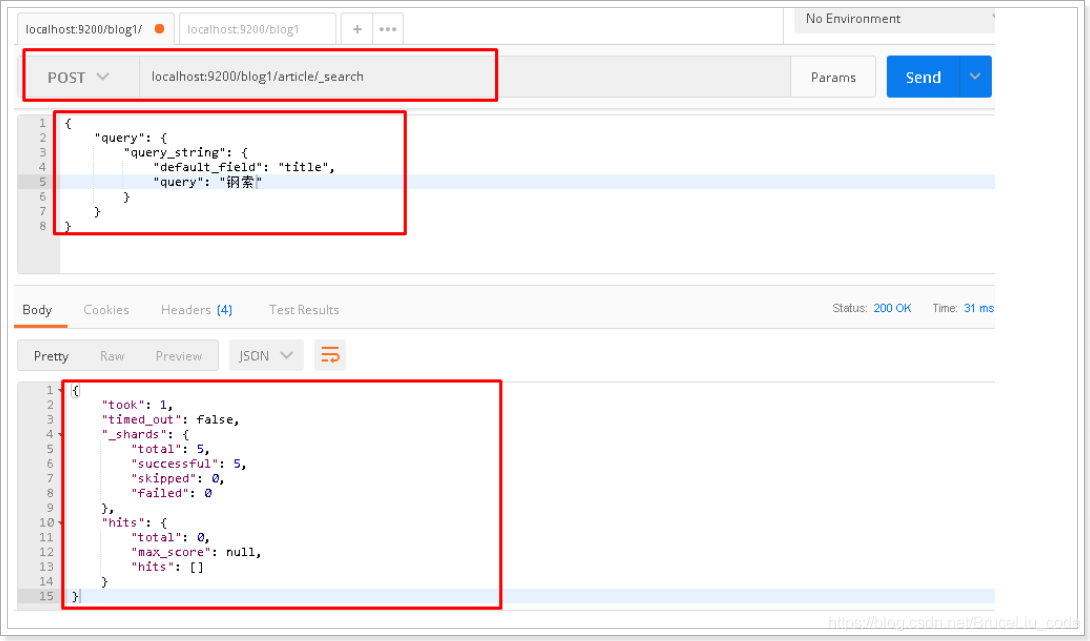
6.3 再次测试term测试
请求url:
POST localhost:9200/blog1/article/_search
请求体:
{
"query": {
"term": {
"title": "搜索"
}
}
}
postman截图:
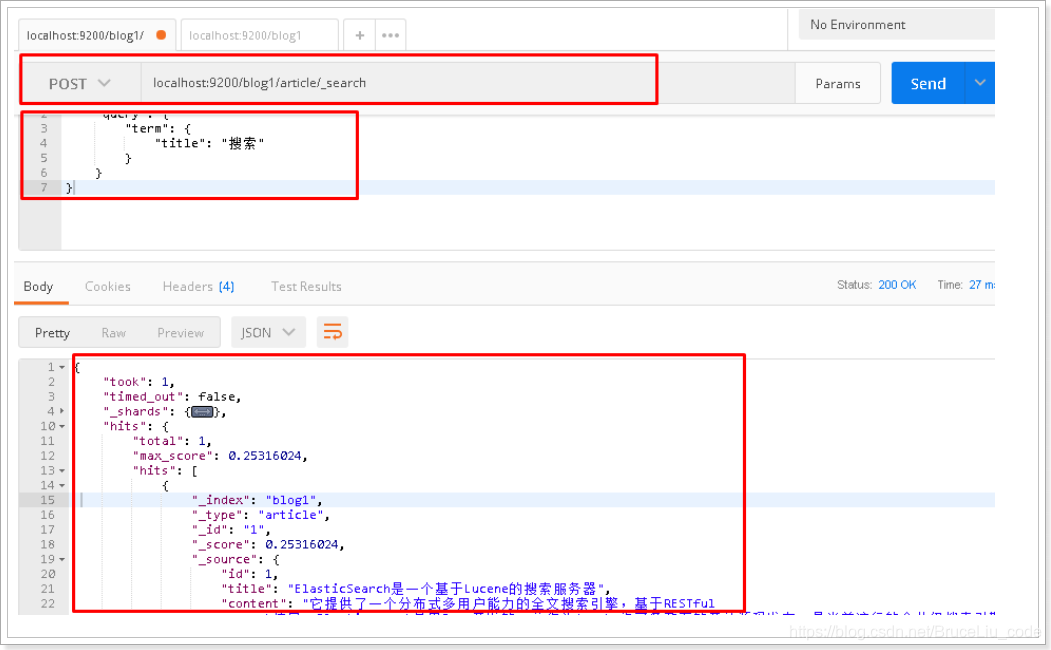
ElasticSearch-IK分词器和集成使用的更多相关文章
- SpringBoot整合Elasticsearch+ik分词器+kibana
话不多说直接开整 首先是版本对应,SpringBoot和ES之间的版本必须要按照官方给的对照表进行安装,最新版本对照表如下: (官网链接:https://docs.spring.io/spring-d ...
- Elasticsearch IK分词器
Elasticsearch-IK分词器 一.简介 因为Elasticsearch中默认的标准分词器(analyze)对中文分词不是很友好,会将中文词语拆分成一个一个中文的汉字,所以引入中文分词器-IK ...
- 七、Elasticsearch+elasticsearch-head的安装+Kibana环境搭建+ik分词器安装
一.安装JDK1.8 二.安装ES 三个节点:master.slave01.slave02 1.这里下载的是elasticsearch-6.3.1.rpm版本包 https://www.elastic ...
- IK 分词器
目录 IK 分词器-介绍 IK 分词器-安装 环境准备:Maven 安装 IK 分词器 IK 分词器-使用 IK 分词器-介绍 现有问题:ES 默认对中文分词并不友好,实际上是把中文进行了每个字的分词 ...
- (2)ElasticSearch在linux环境中集成IK分词器
1.简介 ElasticSearch默认自带的分词器,是标准分词器,对英文分词比较友好,但是对中文,只能把汉字一个个拆分.而elasticsearch-analysis-ik分词器能针对中文词项颗粒度 ...
- ES系列一、CentOS7安装ES 6.3.1、集成IK分词器
Elasticsearch 6.3.1 地址: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3. ...
- 【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
系列文章:[建议从第二章开始] [ELK][docker][elasticsearch]1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安 ...
- Lucene介绍及简单入门案例(集成ik分词器)
介绍 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和 ...
- Elasticsearch学习系列一(部署和配置IK分词器)
Elasticsearch简介 Elasticsearch是什么? Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储.检索数据.本身扩展性很好,可扩展 ...
- Elasticsearch入门之从零开始安装ik分词器
起因 需要在ES中使用聚合进行统计分析,但是聚合字段值为中文,ES的默认分词器对于中文支持非常不友好:会把完整的中文词语拆分为一系列独立的汉字进行聚合,显然这并不是我的初衷.我们来看个实例: POST ...
随机推荐
- 我们为什么选择VUE来构建前端
很多使用过VUE的程序员,对VUE的评价是"Vue.js 兼具angular.js和react.js的优点,并剔除了它们的缺点". 那么,他真的值得这么高的评价嘛? Vue.js的 ...
- 分布式事务MSDTC使用时,需要的配置
服务器最终配置 DTC服务 组件 防火墙 这里,跟下面的解决方案有点差异,在添加2个规则之后,原本就有分布式相关的规则,也给开启了. 网上的解决办法 在服务里打开 Distributed Transa ...
- 关于Git的一些常规操作
最近刚换了新的办公电脑,Git有重新安装了一遍,很多步骤久了不操作就忘了,又是好一顿折腾,于是这次就顺便记下来了. 不错的Git教程: https://www.liaoxuefeng.com/wiki ...
- @RequestBody,@RequestParam请求数据接收数据
一. @RequestBody 注解 @RequestBody是用于解析body中的json内容,对于我们使用时候我们需要指定Content-Type参数为application/json,标识我们需 ...
- [leetcode]49. Group Anagrams重排列字符串分组
是之前的重排列字符串的延伸,判断是重排列后存到HashMap中进行分组 这种HashMap进行分组的方式很常用 public List<List<String>> groupA ...
- MySQL索引优化,explain详细讲解
前言:这篇文章主要讲 explain 如何使用,还有 explain 各种参数概念,之后会讲优化 一.Explain 用法 模拟Mysql优化器是如何执行SQL查询语句的,从而知道Mysql是如何处理 ...
- 本地项目上传至GitHub
本地项目上传至GitHub 使用git上传 一.安装git 直接官网下载,安装即可. git官网下载 github下载 按照好后大概就是这个样子 二.创建公钥和私钥 有的就可跳过此步骤 我们双击打开g ...
- tail常用命令总结
tail命令作用: tail命令用途是依照要求将指定的文件的最后部分输出到标准设备,通常是终端,通俗讲来,就是把某个档案文件的最后几行显示到终端上,假设该档案有更新,tail会自己主动刷新,确保你看到 ...
- ABP框架中短信发送处理,包括阿里云短信和普通短信商的短信发送集成
在一般的系统中,往往也有短信模块的需求,如动态密码的登录,系统密码的找回,以及为了获取用户手机号码的短信确认等等,在ABP框架中,本身提供了对邮件.短信的基础支持,那么只需要根据自己的情况实现对应的接 ...
- Vue3.0聊天室|vue3+vant3仿微信聊天实例|vue3.x仿微信app界面
一.项目简介 基于Vue3.0+Vant3.x+Vuex4.x+Vue-router4+V3Popup等技术开发实现的仿微信手机App聊天实例项目Vue3-Chatroom.实现了发送图文表情消息/g ...