Decision Trees:机器学习根据大量数据,已知年龄、收入、是否上海人、私家车价格的人,预测Ta是否有真实购买上海黄浦区楼房的能力—Jason niu
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
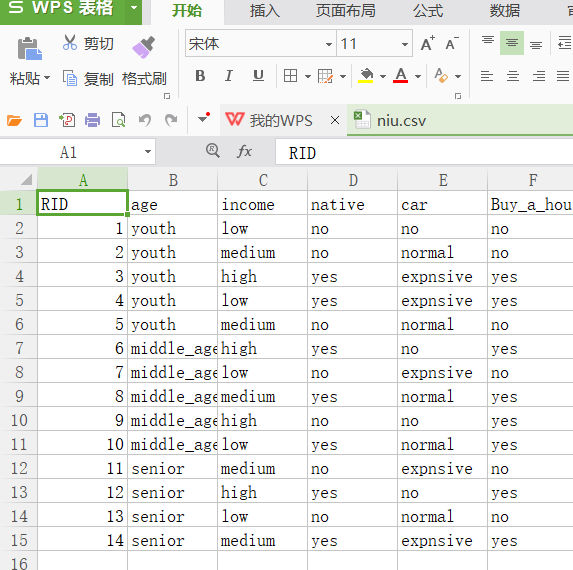
from sklearn.externals.six import StringIO allElectronicsData = open(r'F:/AI/DL_month1201/01DTree/niu.csv', 'rt')
reader = csv.reader(allElectronicsData)
headers = next(reader)
print(headers)
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row)-1]) rowDict = {}
for i in range(1, len(row)-1):
rowDict[headers[i]] = row[i] featureList.append(rowDict) print(featureList) vec = DictVectorizer()
dummyX = vec.fit_transform(featureList) .toarray() print("dummyX: " + str(dummyX))
print(vec.get_feature_names()) print("labelList: " + str(labelList)) lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY)) clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX, dummyY)
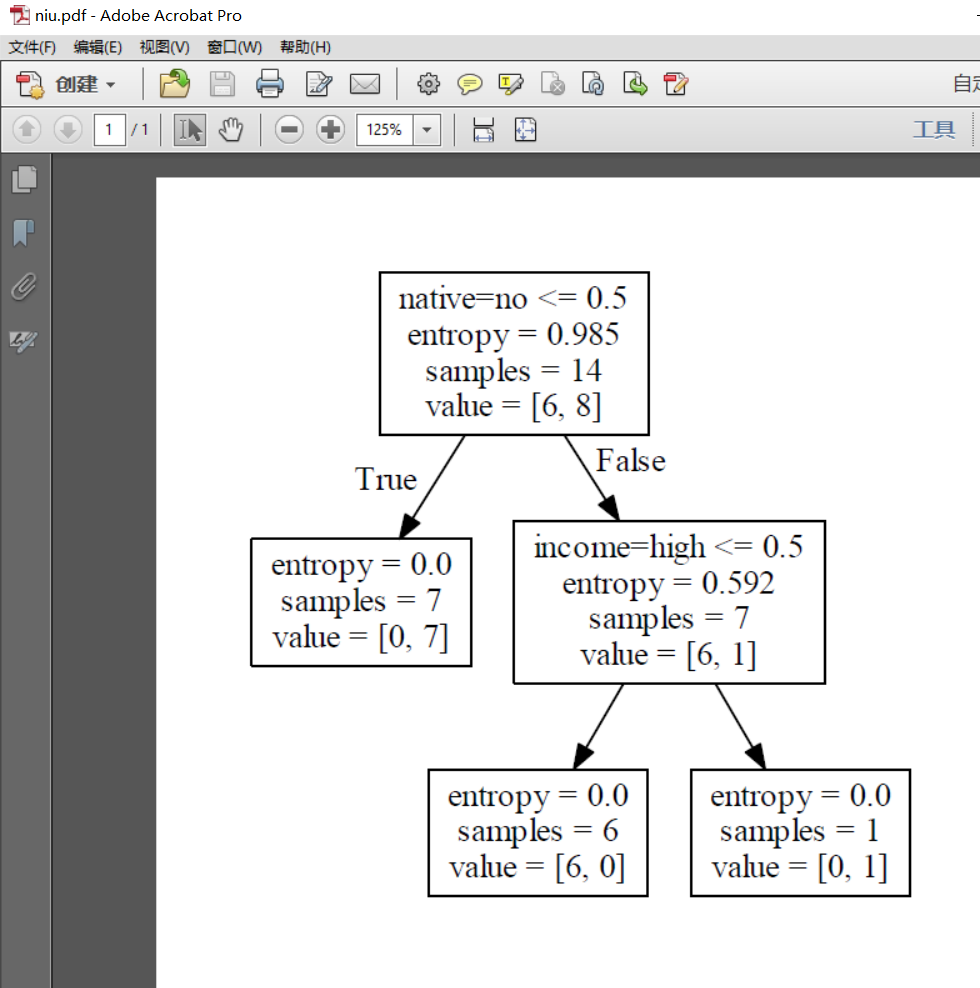
print("clf: " + str(clf)) with open("niu.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f) oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX)) newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX)) predictedY = clf.predict([newRowX])
print("predictedY: " + str(predictedY))
Decision Trees:机器学习根据大量数据,已知年龄、收入、是否上海人、私家车价格的人,预测Ta是否有真实购买上海黄浦区楼房的能力—Jason niu的更多相关文章
- 机器学习算法 --- Decision Trees Algorithms
一.Decision Trees Agorithms的简介 决策树算法(Decision Trees Agorithms),是如今最流行的机器学习算法之一,它即能做分类又做回归(不像之前介绍的其他学习 ...
- 如何利用AI识别未知——加入未知类(不太靠谱),检测待识别数据和已知样本数据的匹配程度(例如使用CNN降维,再用knn类似距离来实现),将问题转化为特征搜索问题而非决策问题,使用HTM算法(记忆+模式匹配预测就是智能),GAN异常检测,RBF
https://www.researchgate.net/post/How_to_determine_unknown_class_using_neural_network 里面有讨论,说是用rbf神经 ...
- WCF数据契约代理和已知类型的使用
using Bll; using System; using System.CodeDom; using System.Collections.Generic; using System.Collec ...
- 机器学习算法 --- Pruning (decision trees) & Random Forest Algorithm
一.Table for Content 在之前的文章中我们介绍了Decision Trees Agorithms,然而这个学习算法有一个很大的弊端,就是很容易出现Overfitting,为了解决此问题 ...
- 《大数据日知录》读书笔记-ch15机器学习:范型与架构
机器学习算法特点:迭代运算 损失函数最小化训练过程中,在巨大参数空间中迭代寻找最优解 比如:主题模型.回归.矩阵分解.SVM.深度学习 分布式机器学习的挑战: - 网络通信效率 - 不同节点执行速度不 ...
- HDU - 6096 :String (AC自动机,已知前后缀,匹配单词,弱数据)
Bob has a dictionary with N words in it. Now there is a list of words in which the middle part of th ...
- sql 先查出已知的数据或者需要的数据再筛选
sql 先查出已知的数据或者需要的数据再筛选
- Logistic Regression vs Decision Trees vs SVM: Part II
This is the 2nd part of the series. Read the first part here: Logistic Regression Vs Decision Trees ...
- SIGAI机器学习第九集 数据降维2
讲授LDA基本思想,寻找最佳投影矩阵,PCA与LDA的比较,LDA的实际应用 大纲: 非线性降维算法流形的概念流形学习的概念局部线性嵌入拉普拉斯特征映射局部保持投影等距映射实验环节 非线性降维算法: ...
随机推荐
- Android 应用防止被二次打包指南
前言 “Android APP二次打包”则是盗版正规Android APP,破解后植入恶意代码重新打包.不管从性能.用户体验.外观它都跟正规APP一模一样但是背后它确悄悄运行着可怕的程序,它会在不知不 ...
- Confluence 6 数据库和临时目录
数据库 所有的其他数据库,包括有页面,内容都存储在数据库中.如果你安装的 Confluence 是用于评估或者你选择使用的是 Embedded H2 Database 数据库.数据库有关的文件将会存储 ...
- 从 Confluence 5.3 及其早期版本中恢复空间
如果你需要从 Confluence 5.3 及其早期版本中的导出文件恢复到晚于 Confluence 5.3 的 Confluence 中的话.你可以使用临时的 Confluence 空间安装,然后将 ...
- Confluence 6 手动备份
Confluence 的 Attachment Storage Configuration 可以配置 Confluence 将附件存储在 home directory,或者是存储在数据库中. Dat ...
- Confluence 6 中样式化字体
Confluence 提供了通过层叠样式表(CSS)调整页面展示情况的能力.本页面帮助你理解如何在 Confluence 中使用一些 CSS 样式修改字体样式和字体大小. 下面的代码为自定义的字体代码 ...
- 官方版sublime Text3汉化和激活注册码
转载:https://www.cnblogs.com/chaonuanxi/p/9371837.html sublimeText3 很不错,前面几天下了vscore学习Node.js,感觉有点懵,今天 ...
- Java在线备份和还原MySQL数据库。
2018年6月29日14:00:48 阅读数:1534 今天整了整整一整天,终于使用Java在线备份和还原MySQL数据库了,哎,备份倒是很快,就是在还原的时候遇到了一个问题,也不报错,结果将sql语 ...
- 如果拷贝项目出现各种找不到文件的时候,基本就是没有标记,或者文件名的问题,Could not find resource mybatis.xml,解决方法
Could not find resource mybatis.xml
- CSS常见Bugs及解决方案列表
以下实例默认运行环境都为Standard mode 如何在IE6及更早浏览器中定义小高度的容器? 方法: #test{overflow:hidden;height:1px;font-size:0;li ...
- JavaScript学习:取数组中最大值和最小值
在实际业务中有的时候要取出数组中的最大值或最小值.但在数组中并没有提供arr.max()和arr.min()这样的方法.那么是不是可以通过别的方式实现类似这样的方法呢?那么今天我们就来整理取出数组中最 ...