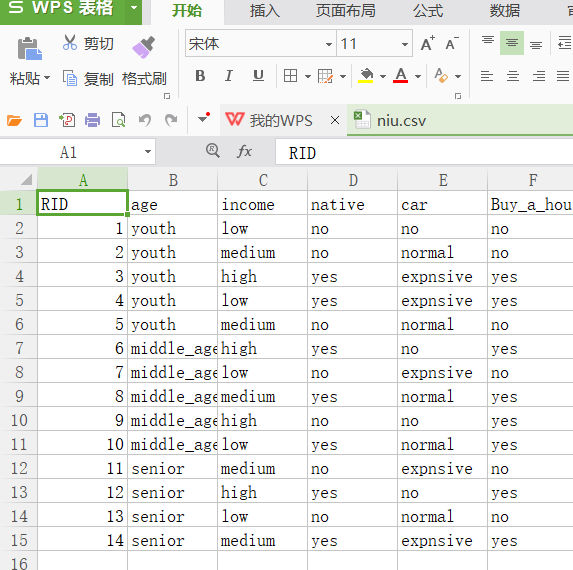
Decision Trees:机器学习根据大量数据,已知年龄、收入、是否上海人、私家车价格的人,预测Ta是否有真实购买上海黄浦区楼房的能力—Jason niu
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO allElectronicsData = open(r'F:/AI/DL_month1201/01DTree/niu.csv', 'rt')
reader = csv.reader(allElectronicsData)
headers = next(reader)
print(headers)
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row)-1]) rowDict = {}
for i in range(1, len(row)-1):
rowDict[headers[i]] = row[i] featureList.append(rowDict) print(featureList) vec = DictVectorizer()
dummyX = vec.fit_transform(featureList) .toarray() print("dummyX: " + str(dummyX))
print(vec.get_feature_names()) print("labelList: " + str(labelList)) lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY)) clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf)) with open("niu.dot", 'w') as f:
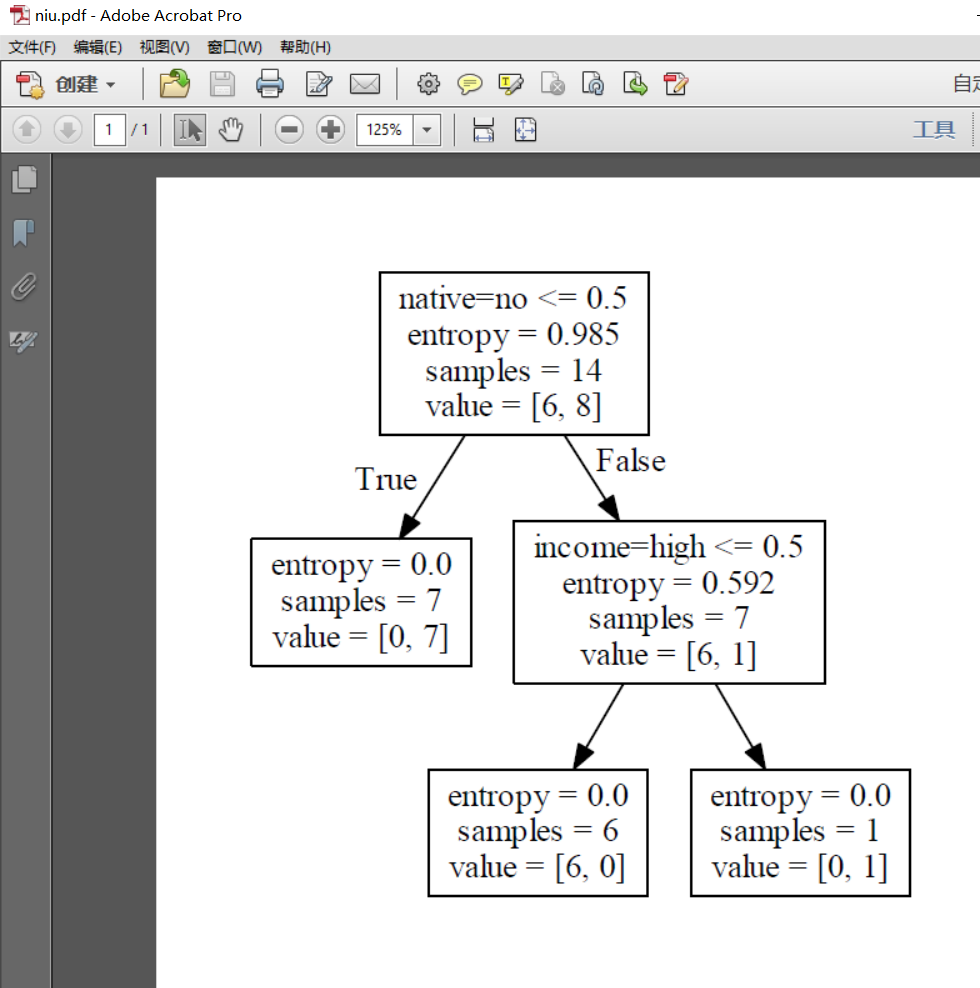
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f) oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX)) newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX)) predictedY = clf.predict([newRowX])
print("predictedY: " + str(predictedY))
Decision Trees:机器学习根据大量数据,已知年龄、收入、是否上海人、私家车价格的人,预测Ta是否有真实购买上海黄浦区楼房的能力—Jason niu的更多相关文章
- 机器学习算法 --- Decision Trees Algorithms
一.Decision Trees Agorithms的简介 决策树算法(Decision Trees Agorithms),是如今最流行的机器学习算法之一,它即能做分类又做回归(不像之前介绍的其他学习 ...
- 如何利用AI识别未知——加入未知类(不太靠谱),检测待识别数据和已知样本数据的匹配程度(例如使用CNN降维,再用knn类似距离来实现),将问题转化为特征搜索问题而非决策问题,使用HTM算法(记忆+模式匹配预测就是智能),GAN异常检测,RBF
https://www.researchgate.net/post/How_to_determine_unknown_class_using_neural_network 里面有讨论,说是用rbf神经 ...
- WCF数据契约代理和已知类型的使用
using Bll; using System; using System.CodeDom; using System.Collections.Generic; using System.Collec ...
- 机器学习算法 --- Pruning (decision trees) & Random Forest Algorithm
一.Table for Content 在之前的文章中我们介绍了Decision Trees Agorithms,然而这个学习算法有一个很大的弊端,就是很容易出现Overfitting,为了解决此问题 ...
- 《大数据日知录》读书笔记-ch15机器学习:范型与架构
机器学习算法特点:迭代运算 损失函数最小化训练过程中,在巨大参数空间中迭代寻找最优解 比如:主题模型.回归.矩阵分解.SVM.深度学习 分布式机器学习的挑战: - 网络通信效率 - 不同节点执行速度不 ...
- HDU - 6096 :String (AC自动机,已知前后缀,匹配单词,弱数据)
Bob has a dictionary with N words in it. Now there is a list of words in which the middle part of th ...
- sql 先查出已知的数据或者需要的数据再筛选
sql 先查出已知的数据或者需要的数据再筛选
- Logistic Regression vs Decision Trees vs SVM: Part II
This is the 2nd part of the series. Read the first part here: Logistic Regression Vs Decision Trees ...
- SIGAI机器学习第九集 数据降维2
讲授LDA基本思想,寻找最佳投影矩阵,PCA与LDA的比较,LDA的实际应用 大纲: 非线性降维算法流形的概念流形学习的概念局部线性嵌入拉普拉斯特征映射局部保持投影等距映射实验环节 非线性降维算法: ...
随机推荐
- 关于STM32 __IO 的变量定义
这个_IO 是指静态 这个 _IO 是指静态 volatile uint32_t 是指32位的无符号整形变量uint32_t 是指32位的无符号整形变量: 搞stm32这么久了,经常看到stm32里面 ...
- 按照勾选 删除表格的行<tr>
需求描述:有一个产品列表,有一个删减按钮,点击删减按钮,按照产品勾选的行,删除产品列表中对应的行数据 代码: //html代码<table id="table1"> & ...
- MySQL报错: Character set ‘utf8mb4‘ is not a compiled character set and is not specified in the ‘/usr/share/mysql/charsets/Index.xml‘ file
由于日常程序使用了字符集utf8mb4,为了避免每次更新时,set names utf8mb4,就把配置文件改了,如下: [root@~]# vim /etc/my.cnf #my.cnf [clie ...
- yslow V2 准则详细讲解
主要有12条: 1. Make fewer HTTP requests 尽可能少的http请求..我们有141个请求(其中15个JS请求,3个CSS请求,47个CSS background ima ...
- C++中的继承(1) 继承方式
1.继承与派生 继承是使代码可以复用的重要手段,也是面向对象程序设计的核心思想之一.简单的说,继承是指一个对象直接使用另一对象的属性和方法.继承呈现了 面向对象程序设 计的层次结构, 体现了 由简单 ...
- ubuntu下直接可视化访问服务器文件夹方法
任意打开一个文件夹在文件夹的左下角输入 sftp://list-2018@10.192.229.62/home/list-2018 list-2018:想登陆的服务器下的帐号 10.192.229 ...
- 常见的爬虫分析库(2)-xpath语法
xpath简介 1.xpath使用路径表达式在xml和html中进行导航 2.xpath包含标准函数库 3.xpath是一个w3c的标准 xpath节点关系 1.父节点 2.子节点 3.同胞节点 4. ...
- python之ORM操作
1. SQLalchemy简介 SQLAlchemy是一个开源的SQL工具包,基本Python编程语言的MIT许可证而发布的对象关系映射器.SQLAlchemy提供了“一个熟知的企业级全套持久性模式, ...
- 支持向量机-完整Platt-SMO算法加速优化
完整版SMO算法与简单的SMO算法: 实现alpha的更改和代数运算的优化环节一模一样,唯一的不同就是选择alpha的方式.完整版应用了一些能够提速的方法. 同样使用Jupyter实现,后面不在赘述 ...
- POJ 1364 / HDU 3666 【差分约束-SPFA】
POJ 1364 题解:最短路式子:d[v]<=d[u]+w 式子1:sum[a+b+1]−sum[a]>c — sum[a]<=sum[a+b+1]−c−1 ...