Java自定义线程池-记录每个线程执行耗时
ThreadPoolExecutor是可扩展的,其提供了几个可在子类化中改写的方法,如下:
protected void beforeExecute(Thread t, Runnable r) { }
protected void afterExecute(Runnable r, Throwable t) { }
protected void terminated() { }
现基于此,完成一个统计每个线程执行耗时,并计算平均耗时的 自定义线程池样例。通过 beforeExecute、afterExecute、terminated 方法来添加日志记录和统计信息收集。为了测量任务的运行时间,beforeExecute必须记录开始时间并把它保存到一个ThreadLocal变量中,然后由afterExecute来读取。同时,使用两个 AtomicLong变量,分别用以记录已处理的任务数和总的处理时间,并通过terminated来输出包含平均任务时间的日志消息。
自定义线程池代码如下:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
import java.util.logging.Logger; /**
* 自定义线程池
*/
public class TimingThreadPool extends ThreadPoolExecutor { private final ThreadLocal<Long> startTime = new ThreadLocal<>();
private final Logger log = Logger.getLogger("TimingThreadPool");
private final AtomicLong numTasks = new AtomicLong();
private final AtomicLong totalTime = new AtomicLong(); public TimingThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
} @Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
log.info(String.format("Thread %s: start %s",t,r));
startTime.set(System.nanoTime());
} @Override
protected void afterExecute(Runnable r, Throwable t) {
try {
long endTime = System.nanoTime();
long taskTime = endTime - startTime.get();
numTasks.incrementAndGet();
totalTime.addAndGet(taskTime);
log.info(String.format("Thread %s: end %s, time=%dns",t,r,taskTime)); } finally {
super.afterExecute(r,t);
}
} @Override
protected void terminated() {
try {
log.info(String.format("Terminated: avg time=%dns",totalTime.get() / numTasks.get()));
} finally {
super.terminated();
}
}
}
测试执行效果代码如下:
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.Future;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit; /**
* 测试自定义线程池
*/
public class TestCustomThreadPool { public static void main(String[] args) { try {
TimingThreadPool threadPool = new TimingThreadPool(,,0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()); List<TestCallable> tasks = new ArrayList<>(); for (int i = ; i < ; i++) {
tasks.add(new TestCallable());
} List<Future<Long>> futures = threadPool.invokeAll(tasks);
for (Future<Long> future :
futures) {
System.out.print(" - "+future.get());
}
threadPool.shutdown(); } catch (Exception e) {
e.printStackTrace();
} } static class TestCallable implements Callable<java.lang.Long> { @Override
public Long call() throws Exception {
long total = ;
for (int i = ; i < ; i++) {
long now = getRandom();
total += now;
}
Thread.sleep(total);
return total;
} public long getRandom () {
return Math.round(Math.random() * );
}
} }
执行结果:
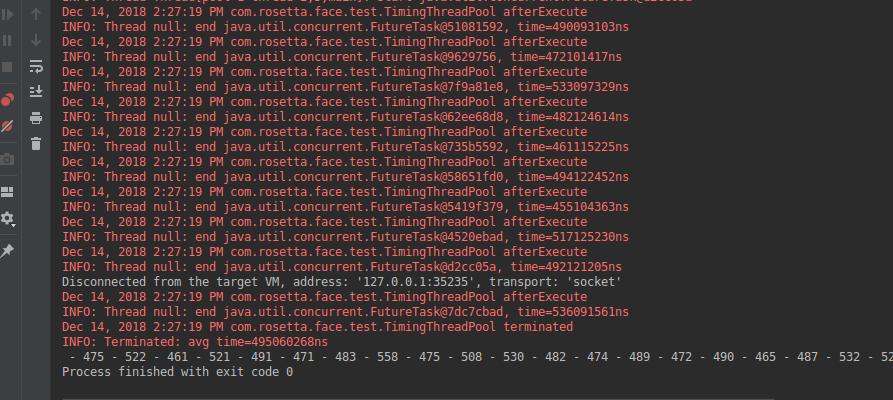
Java自定义线程池-记录每个线程执行耗时的更多相关文章
- Java如何判断线程池所有任务是否执行完毕
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class Tes ...
- Java 线程池记录
Java通过Executors提供四种线程池,分别为:newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程.newFixe ...
- Java多线程系列--“JUC线程池”03之 线程池原理(二)
概要 在前面一章"Java多线程系列--“JUC线程池”02之 线程池原理(一)"中介绍了线程池的数据结构,本章会通过分析线程池的源码,对线程池进行说明.内容包括:线程池示例参考代 ...
- Java多线程系列--“JUC线程池”04之 线程池原理(三)
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3509960.html 本章介绍线程池的生命周期.在"Java多线程系列--“基础篇”01之 基 ...
- Java线程池二:线程池原理
最近精读Netty源码,读到NioEventLoop部分的时候,发现对Java线程&线程池有些概念还有困惑, 所以深入总结一下 Java线程池一:线程基础 为什么需要使用线程池 Java线程映 ...
- Java多线程系列--“JUC线程池”01之 线程池架构
概要 前面分别介绍了"Java多线程基础"."JUC原子类"和"JUC锁".本章介绍JUC的最后一部分的内容——线程池.内容包括:线程池架构 ...
- Java多线程系列--“JUC线程池”02之 线程池原理(一)
概要 在上一章"Java多线程系列--“JUC线程池”01之 线程池架构"中,我们了解了线程池的架构.线程池的实现类是ThreadPoolExecutor类.本章,我们通过分析Th ...
- Java多线程系列--“JUC线程池”05之 线程池原理(四)
概要 本章介绍线程池的拒绝策略.内容包括:拒绝策略介绍拒绝策略对比和示例 转载请注明出处:http://www.cnblogs.com/skywang12345/p/3512947.html 拒绝策略 ...
- 深入浅出 Java Concurrency (34): 线程池 part 7 线程池的实现及原理 (2)[转]
线程池任务执行流程 我们从一个API开始接触Executor是如何处理任务队列的. java.util.concurrent.Executor.execute(Runnable) Executes t ...
随机推荐
- 调试CAS源码步骤
1.先安装gradle2.eclipse安装gradle(sts)插件3.克隆cas源码 这一块需要很长时间4.gradle build 会遇到安装node.js 的模块 不存在的问题. 按提示解决就 ...
- JS判断当前设备是 PC IOS Andriod
JS判断当前设备是 PC IOS Andriod <script > window.onload = function(){ var isPc = IsPC(); var isAndroi ...
- .NET-记一次架构优化实战与方案-前端优化
目录 .NET-记一次架构优化实战与方案-梳理篇 .NET-记一次架构优化实战与方案-前端优化 .NET-记一次架构优化实战与方案-底层服务优化 前言 上一篇<.NET-记一次架构优化实战与方案 ...
- 几何学观止(Lie群部分)
上承这个页面,这次把Lie群的部分写完了 几何学观止-微分几何部分(20181102).pdf 我觉得其他部分(尤其是代数几何部分)我目前没有把握写得令自己满意,总之希望在毕业前能写完吧. 这次调整了 ...
- 海康威视笔试(C++)
1. select和epoll的区别 2.服务器并发量之高性能服务器设计 3.SQL关键字 4.TCP乱序和重传的问题 5.c++对象内存分配问题 6.c++多线程 join的用法: Thread类的 ...
- 用Flask+Redis维护Cookies池
Redis数据库:存储微博账号密码 这里需要购买账号 登录后的cookies:键值对的形式保存 GitHub:https://github.com/LXL-YAN/CookiesPool 视频讲解:h ...
- 动态规划-数位dp
大佬讲的清楚 [https://blog.csdn.net/wust_zzwh/article/details/52100392] 例子 不要62或4 l到r有多少个数不含62或者4 代码 #incl ...
- Yii框架的增删改查总结分析
一.查询数据 1.findAll(根据一个条件查询一个集合) $admin=Admin::model()->findAll($condition,$params); $admin=Admin:: ...
- Dapper.NET
关于Dapper.NET的相关论述 年少时,为何不为自己的梦想去拼搏一次呢?纵使头破血流,也不悔有那年少轻狂.感慨很多,最近事情也很多,博客也很少更新了,毕竟每个人都需要为自己的生活去努力. 最近 ...
- Linux 典型应用之缓存服务
memcached 安装和简单使用 yum install memcached 启动 -d 表示以守护进程的方式启动 memcached -d 安装telnet 它可以检测某个端口是否是通的,可以发送 ...