python网络爬虫笔记(六)
1、获取属性如果不存在就返回404,通过内置一系列函数,我们可以对任意python对象进行剖析,拿到其内部数据,但是要注意的是,只是在不知道对象信息的时候,我们可以获得对象的信息。

2、实例属性和类属性的绑定,由于python是 动态语言,根据类创建的实例可以任意绑定属性,给实例绑定属性的方法通过实例变量或者self变量。实例属性属于各个实例所有,互不干扰,类的属性属于类所有,所有实例共享一个属性,不要对实例属性和类属性使用相同的名字,否则将产生难以发现的错误。
3、使用__slots__变量限制class实例添加的属性。就是限制给class绑定属性。
class Student(object): @property
def score(self):
return self._score @score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value@property的实现比较复杂,我们先考察如何使用。把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值,于是,我们就拥有一个可控的属性操作:
4、多重继承,通过多重继承,一个子类可以获得多个父类的所用功能
5、 文档测试
6、IO测试,注意:>>> f = open('/Users/michael/test.jpg', 'rb') >>> f.read() b'\xff\xd8\xff\xe1\x00\x18Exif\x00\x00...' # 十六进制表示的字节


要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数,例如,读取GBK编码的文件:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk')
>>> f.read()
'测试'遇到有些编码不规范的文件,你可能会遇到UnicodeDecodeError,因为在文本文件中可能夹杂了一些非法编码的字符。遇到这种情况,open()函数还接收一个errors参数,表示如果遇到编码错误后如何处理。最简单的方式是直接忽略:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk', errors='ignore'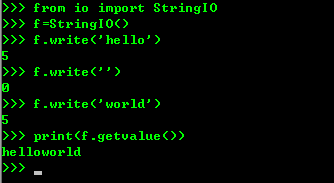
python网络爬虫笔记(六)的更多相关文章
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- [Python]网络爬虫(六):一个简单的百度贴吧的小爬虫
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8927832 # -*- coding: utf-8 -*- #----------- ...
- Python网络爬虫笔记(二):链接爬虫和下载限速
(一)代码1(link_crawler()和get_links()实现链接爬虫) import urllib.request as ure import re import urllib.parse ...
- python网络爬虫笔记(九)
4.1.1 urllib2 和urllib是两个不一样的模块 urllib2最简单的就是使用urllie2.urlopen函数使用如下 urllib2.urlopen(url[,data[,timeo ...
- python网络爬虫笔记(八)
一.pthon 序列化json格式 1.将python内置对象转换成json 模块,dumps()方法返回的是一个str,内容是标准的JSON,dump()方法可以直接吧JSON写入一个file-li ...
- python网络爬虫笔记(五)
一.python的类对象的继承 1.所有的父类都是object类,由于类可以起到模块的作用,因此,可以在创建实例的时候,巴西一些认为必须要绑定的属性填写上去,通过定义一个特殊的方法 __init__, ...
- python网络爬虫笔记(四)
一.python中的高阶函数算法 1.sorted()函数的排序 sorted()函数是一个高阶函数,还可以接受一个key函数来实现自定义的函数排序,key指定的函数作用于每个序列元素上,并根据k ...
- python网络爬虫笔记(三)
一.切片和迭代 1.列表生成式 2.生成器的generate,但是generate保存的是算法,所以可以迭代计算,没有必要,每次调用generate 二.iteration 循环 1.凡是作用于for ...
- python网络爬虫笔记(一)
一.查询数据字典型数据 1.先说说dictionary查找和插入的速度极快,不会随着key的增加减慢速度,但是占用的内存大 2.list查找和插入的时间随着元素的增加而增加,但还是占用的空间小,内存浪 ...
随机推荐
- mybatis执行批量更新数据
1.业务需求:同时执行多记录批量操作 2.实现方法: 1)mapping: 2) dao 层 3)Service 层(注意要使用Transactional,否则可能会导致数据紊乱) 4)Con ...
- webstorm更改scss输出路径
--no-cache --update $FileName$:$FileParentDir$\css\$FileNameWithoutExtension$.css $FileNameWithoutEx ...
- .Net core 使用特性Attribute验证Session登陆状态
1.新建一个.net core mvc项目 2.在Models文件夹下面添加一个类MyAttribute,专门用来保存我们定义的特性 在这里我只写了CheckLoginAttribute用来验证登陆情 ...
- Android视频压缩
最推荐(使用方便,默认压缩为原来视频大小的1/4左右): https://blog.csdn.net/qq_35373333/article/details/79564991 https://git ...
- 20165231 2017-2018-2 《Java程序设计》第9周学习总结
教材学习内容总结 第十三章 URL类 URL类是java.net包中的一个重要的类,URL的实例封装着一个统一资源定位符(Uniform Resource Locator),使用URL创建对象的应用程 ...
- 积分从入门到放弃<2>
这部分重新从定积分学了 1,lnx 的导数就是x^(-1) = 1/x 那么求∫(1/x)dx = ln|x|+C 2,初值问题.就是求∫f(x)dx = F(x) + C 求C . 3,Houdi ...
- 【转】模块(configparser+shutil+logging)
[转]模块(configparser+shutil+logging) 一.configparser模块 1.模块介绍 configparser用于处理特定格式的文件,其本质上是利用open来操作文件. ...
- jenkins服务器上安装配置Android SDK
1.下载Android SDK http://tools.android-studio.org/index.php/sdk/ 我下载的是:android-sdk_r24.4.1-linux.tgz ...
- 测试cpu的简单工具-dhrystone【转】
转自:https://blog.csdn.net/feixiaoxing/article/details/9005587 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog ...
- Delphi 使用 Datasnap 的几种三层应用技术总结
Delphi 使用 Datasnap 进行三层应用开发,积累了几种技术,总结如下: 1.(推荐!)在 Datasnap 服务端 使用 TDatasetProvider,客户端 使用 TDSProv ...