分布式存储Minio集群环境搭建
MinIO 分布式集群搭建
分布式 Minio 可以让你将多块硬盘(甚至在不同的机器上)组成一个对象存储服务。由于硬盘分布在不同的节点上,分布式 Minio 避免了单点故障。
Minio 分布式模式可以搭建一个高可用的对象存储服务,你可以使用这些存储设备,而不用考虑其真实物理位置。
(1)数据保护
分布式 Minio 采用纠删码(erasure code)来防范多个节点宕机和位衰减(bit rot)。
分布式 Minio 至少需要 4 个节点,使用分布式 Minio 就自动引入了纠删码功能。
纠删码是一种恢复丢失和损坏数据的数学算法, Minio 采用 Reed-Solomon code 将对象拆分成 N/2 数据和 N/2 奇偶校验块。 这就意味着如果是 12 块盘,一个对象会被分成 6 个数据块、6 个奇偶校验块,你可以丢失任意 6 块盘(不管其是存放的数据块还是奇偶校验块),你仍可以从剩下的盘中的数据进行恢复。
纠删码的工作原理和 RAID 或者复制不同,像 RAID6 可以在损失两块盘的情况下不丢数据,而 Minio 纠删码可以在丢失一半的盘的情况下,仍可以保证数据安全。 而且 Minio 纠删码是作用在对象级别,可以一次恢复一个对象,而RAID 是作用在卷级别,数据恢复时间很长。 Minio 对每个对象单独编码,存储服务一经部署,通常情况下是不需要更换硬盘或者修复。Minio 纠删码的设计目标是为了性能和尽可能的使用硬件加速。
位衰减又被称为数据腐化 Data Rot、无声数据损坏 Silent Data Corruption ,是目前硬盘数据的一种严重数据丢失问题。硬盘上的数据可能会神不知鬼不觉就损坏了,也没有什么错误日志。正所谓明枪易躲,暗箭难防,这种背地里犯的错比硬盘直接故障还危险。 所以 Minio 纠删码采用了高速 HighwayHash 基于哈希的校验和来防范位衰减。
(2)高可用
单机 Minio 服务存在单点故障,相反,如果是一个 N 节点的分布式 Minio ,只要有 N/2 节点在线,你的数据就是安全的。不过你需要至少有 N/2+1 个节点来创建新的对象。
例如,一个 8 节点的 Minio 集群,每个节点一块盘,就算 4 个节点宕机,这个集群仍然是可读的,不过你需要 5 个节点才能写数据。
(3)限制
分布式 Minio 单租户存在最少 4 个盘最多 16 个盘的限制(受限于纠删码)。这种限制确保了 Minio 的简洁,同时仍拥有伸缩性。如果你需要搭建一个多租户环境,你可以轻松的使用编排工具(Kubernetes)来管理多个Minio实例。
注意,只要遵守分布式 Minio 的限制,你可以组合不同的节点和每个节点几块盘。比如,你可以使用 2 个节点,每个节点 4 块盘,也可以使用 4 个节点,每个节点两块盘,诸如此类。
(4)一致性
Minio 在分布式和单机模式下,所有读写操作都严格遵守 read-after-write 一致性模型。
搭建分布式集群
启动一个分布式 Minio 实例,你只需要把硬盘位置做为参数传给 minio server 命令即可,然后,你需要在所有其它节点运行同样的命令。
注意
- 分布式 Minio 里所有的节点需要有同样的 access 秘钥和 secret 秘钥,这样这些节点才能建立联接。为了实现这个,你需要在执行 minio server 命令之前,先将 access 秘钥和 secret 秘钥 export 成环境变量。
- 分布式 Minio 使用的磁盘里必须是干净的,里面没有数据。
- 下面示例里的 IP 仅供示例参考,你需要改成你真实用到的 IP 和文件夹路径。
- 分布式 Minio 里的节点时间差不能超过 3 秒,你可以使用 NTP 来保证时间一致。
- 在 Windows 下运行分布式 Minio 处于实验阶段,不建议用于生产环境。
示例1:
启动分布式Minio实例,8个节点,每节点1块盘,需要在8个节点上都运行下面的命令。
export MINIO_ACCESS_KEY=<ACCESS_KEY>
export MINIO_SECRET_KEY=<SECRET_KEY>
minio server http://192.168.1.11/export1 http://192.168.1.12/export2 \
http://192.168.1.13/export3 http://192.168.1.14/export4 \
http://192.168.1.15/export5 http://192.168.1.16/export6 \
http://192.168.1.17/export7 http://192.168.1.18/export8
示例2:
启动分布式Minio实例,4节点,每节点2块盘,需要在4个节点上都运行下面的命令。
export MINIO_ACCESS_KEY=<ACCESS_KEY>
export MINIO_SECRET_KEY=<SECRET_KEY>
minio server http://192.168.1.11/export1 http://192.168.1.11/export2 \
http://192.168.1.12/export1 http://192.168.1.12/export2 \
http://192.168.1.13/export1 http://192.168.1.13/export2 \
http://192.168.1.14/export1 http://192.168.1.14/export2 \
实战部分
此次计划在61-64四台centOs机器上安装minio集群,均位于/opt/minio目录
(1)下载minio
mkdir /opt/minio
cd /opt/minio(2)编写start.sh脚本

将61下/opt/minio文件夹所有内容可通过scp命令复制到62-64的/opt/minio下
然后在61-64的机器上逐个执行start.sh脚本,大功告成!
为方便起见,编写批量启动脚本,仅在61的目录下编写cluster_start.sh
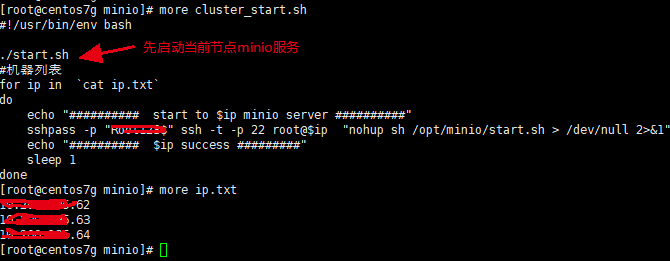
将62-64的ip存放在ip.txt文件内采用cat 逐行读取。
注意点:
1. accessKey大于3字符, secretKey必须大于8字符,否则启动不了,下图我将secretKey设置6位字符,然后启动

查看minio进程并没有启动

查看minio.log

2. 配置的多台机器 secretKey accessKey必须完全一致,否则会出现意想不到的错误,因为多台机器之间的信息同步就是通过这两个key进行,否则肯定会认证失败
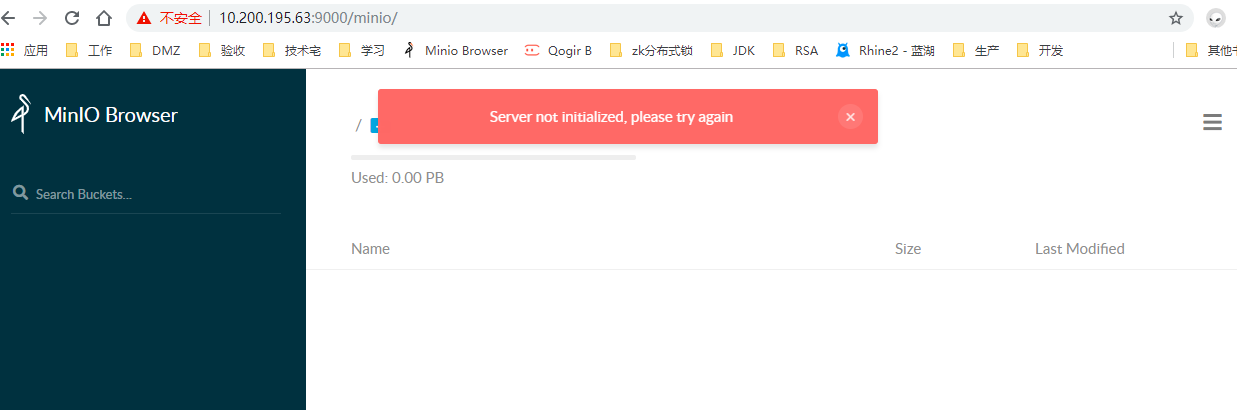
查看minio.log

3.当集群中的某个节点down了,会影响整体的使用,我手动将64的节点停掉

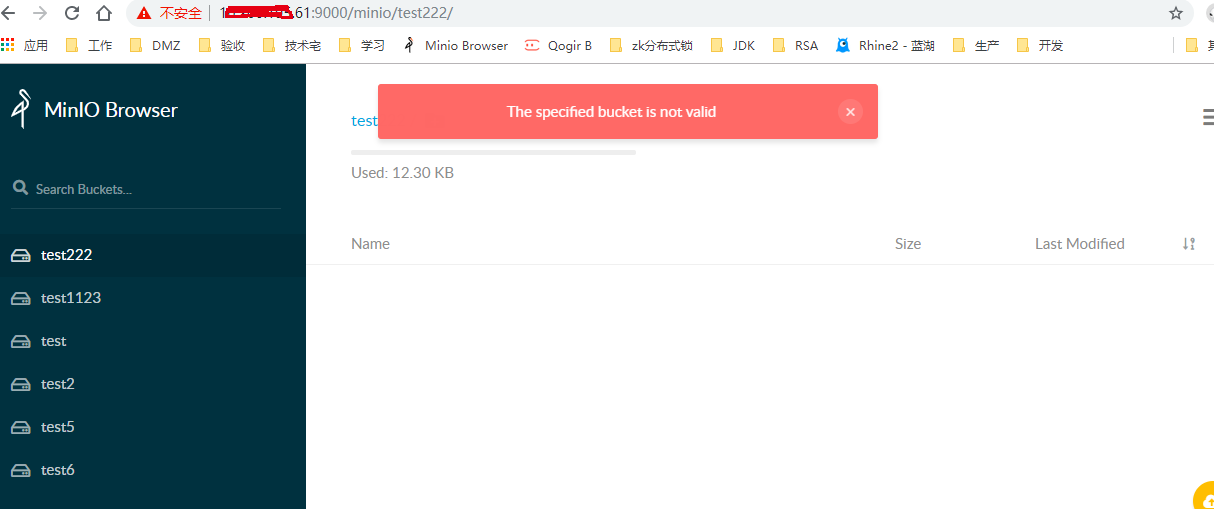
尝试在63及61上创建bucket,尝试失败,注意不要在kill64后立即测试,要稍等一会儿,否则可能不会复现这个问题。 个人猜测,可能是64的状态同步需要发送心跳给至集群内的其他机器,这个需要一些时间。

再次启动64的服务后,再进行63 61的创建bucket ,就成功了,


再登录 64查看,会同步到其他节点创建的bucket,再创建2112buckt,其他的节点也能同步到。

以上是本次安装的踩坑经历,但愿能帮助一些人,如有疑问或有误,烦请指出,以免误人。
分布式存储Minio集群环境搭建的更多相关文章
- ZooKeeper 介绍及集群环境搭建
本篇由鄙人学习ZooKeeper亲自整理的一些资料 包括:ZooKeeper的介绍,我们要学习ZooKeeper的话,首先就要知道他是干嘛的对吧. 其次教大家如何去安装这个精巧的智慧品! 相信你能研究 ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- 项目进阶 之 集群环境搭建(三)多管理节点MySQL集群
上次的博文项目进阶 之 集群环境搭建(二)MySQL集群中,我们搭建了一个基础的MySQL集群,这篇博客咱们继续讲解MySQL集群的相关内容,同时针对上一篇遗留的问题提出一个解决方案. 1.单管理节点 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Ningx集群环境搭建
Ningx集群环境搭建 Nginx是什么? Nginx ("engine x") 是⼀个⾼性能的 HTTP 和 反向代理 服务器,也是⼀个 IMAP/ POP3/SMTP 代理服务 ...
随机推荐
- github 下载子目录内容 亲测可用!
下载我的LYBTouchID项目的Kit目录内容 (1)在github上点开这个目录,浏览器地址栏可以得到这个地址 https://github.com/Liuyubao/LYBTouchID/tre ...
- Python安装pyinstaller方法,以及将项目生成可执行程序的步骤
pyinstaller安装方法 前提:确保计算机安装了Python语言环境,并且正确配置了环境变量. 方法一:联网在线自动安装 选择一 Windows OS下进入cmd(命令行窗口) 输入:pip i ...
- net core WebApi——公用库April.Util公开及发布
前言 在之前鼓捣过一次基础工程April.WebApi后,就考虑把常用的类库打包做成一个公共类库,这样既方便维护也方便后续做快速开发使用,仓库地址:April.Util_github,April.Ut ...
- python基础-列表List及内置方法
数据类型之列表-List 用途:用于存一个或多个不同类型的值 定义:通过中括号存值,每个值之间通过逗号进行分隔 l1 = [1,'a',3,'b'] 特性:有序.可变.存多个值的数据类型 常用方法: ...
- Java 用单向循环链表实现 约瑟夫问题
public class lianbiao2 { class Node{ Node next; int number; public Node getNext() { return next; } p ...
- ThinkCMF 框架上的任意内容包含漏洞
0x01 背景 ThinkCMF是一款基于PHP+MYSQL开发的中文内容管理框架,底层采用ThinkPHP3.2.3构建. ThinkCMF提出灵活的应用机制,框架自身提供基础的管理功能,而开发者 ...
- RTKLib的Manual解读
Key-word: integer ambiguity resolution :整周模糊度解算 navigation:导航 Kinematic:动态,RTK的K rover:漫游 validation ...
- 学习笔记57_WCF基础
参考书籍<WCF揭秘> 参考博客园“xfrog” 1.做一个接口,例如: 2.使用一个类,例如:FirstSrvice这个类,来实现这个接口. 3.建立WCF的 宿主 程序: 4.配 ...
- Alibaba 镜像
<mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> ...
- NOIP模拟 34
次芝麻,喝喝喝,长寿花! 什么鬼畜题面...一看就不是什么正经出题人 skyh双双双AK了..太巨了... T1 次芝麻 稍稍手玩就能发现分界点以一个优美的方式跳动 然后就愉快地帮次货们次掉了这个题- ...