Spark 学习笔记之 aggregateByKey
aggregateByKey:
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession object TransformationsDemo {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().appName("TransformationsDemo").master("local[1]").getOrCreate()
val sc = sparkSession.sparkContext
testAggregateByKey(sc) } private def testAggregateByKey(sc: SparkContext) = {
var data = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),1)
def seq(a:Int, b:Int) : Int ={
println("seq: " + a + "\t " + b)
math.max(a,b)
} def comb(a:Int, b:Int) : Int ={
println("comb: " + a + "\t " + b)
a + b
} data.aggregateByKey(0)(seq, comb).collect.foreach(println)
}
}
运行结果:
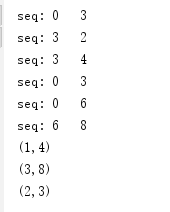
运行结果分析:
根据Key值的不同,可以分为3个组:
(1) (1,3),(1,2),(1,4);
(2) (2,3);
(3) (3,6),(3,8)。
这3个组分别进行seqOp,也就是(K,V)里面的V和0进行math.max()运算,运算结果和下一个V继续运算,以第一个组为例,运算过程是这样的:
0, 3 => 3
3, 2 => 3
3, 4 => 4
所以最终结果是(1,4)。
第二组结果是(2,3)。
第三组结果是(3,8)。
combOp是对把各分区的V加起来,由于这里并没有分区,所以实际上是不起作用的。
修改下代码,添加分区:
private def testAggregateByKey(sc: SparkContext) = {
var data = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
def seq(a:Int, b:Int) : Int ={
println("seq: " + a + "\t " + b)
math.max(a,b)
}
def comb(a:Int, b:Int) : Int ={
println("comb: " + a + "\t " + b)
a + b
}
data.aggregateByKey(0)(seq, comb).collect.foreach(println)
}
运行结果:

运行结果分析:
根据Key值的不同,可以分为3个区:
(1) (1,3),(1,2);
(2) (1,4),(2,3);
(3) (3,6),(3,8)。
区内先做求最大值
第一组结果是(1,3)。
第二组结果是(1,4),(2,3)。
第三组结果是(3,8)。
combOp是对把各分区的V加起来,由于此次有分区,所以(1,3)和(1,4),做合并操作,结果:(1, 7)。
Spark 学习笔记之 aggregateByKey的更多相关文章
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
随机推荐
- FZU - 2150-Fire Game BFS-枚举
Fire Game 题意: 两个小朋友可以任选一块草地点火,草地可以不同,也可以相同,问最少的烧光草地的时间. 思路: 一开始看到这个以为是联通块计数,没想到这道题通过枚举两个起始点作为队列的初始点, ...
- XML序列化CDATA
不可避免的遇到对接需要使用XML文档的第三方系统,某些节点内容特殊,序列化时需特殊处理,解决方案是实现IXmlSerializable接口. /// <summary> /// Perso ...
- 你真的了解Grid布局吗?
Grid网格布局 概述:Grid将容器划分为一个个网格,通过任意组合不同的网格,做出你想想要的布局 Grid与flex布局相似,将整个Grid分为了容器与子项(格子) Grid容器的三个重要的概念: ...
- HTTPS加密协议
使用JDK自带的keytool工具生成一个证书(keystore文件),其中包含了密钥. a.在命令行输入以下命令:keytool -genkey -alias tbb -keyalg RSA -ke ...
- Netty源码分析 (八)----- write过程 源码分析
上一篇文章主要讲了netty的read过程,本文主要分析一下write和writeAndFlush. 主要内容 本文分以下几个部分阐述一个java对象最后是如何转变成字节流,写到socket缓冲区中去 ...
- 基于Python的多线程与多进程
1.I/O密集型与计算密集型 多进程适用于I/O密集型 多进程适用于计算密集型 2.没有sleep(T)的多个死循环只能用多进程 3.模块介绍: 1)threading模块(_thread模块已淘汰) ...
- Unity3D_04_GameObject,Component,Time,Input,Physics
Unity3D是一个Component-Based的游戏引擎,并且为GamePlay Programmer提供了很多游戏性层上的支持. 1.可以在图形界面上设计动画状态转换的Animator. 2.可 ...
- ZK Watcher 的原理和实现
什么是 ZK Watcher 基于 ZK 的应用程序的一个常见需求是需要知道 ZK 集合的状态.为了达到这个目的,一种方法是 ZK 客户端定时轮询 ZK 集合,检查系统状态是否发生了变化.然而,轮询并 ...
- Linux 笔记 - 第八章 文档的打包与压缩
博客地址:http://www.moonxy.com 一.前言 在 Linux 系统中,文件的后缀名没有实际的意义,加或者不加都无所谓.但是为了便于区分,我们习惯在定义文件名时加一个后缀名,比如常见的 ...
- 词义消除歧义NLP项目实验
词义消除歧义NLP项目实验 本项目主要使用https://github.com/alvations/pywsd 中的pywsd库来实现词义消除歧义 目前,该库一部分已经移植到了nltk中,为了获得更好 ...