Python 信息提取-爬虫

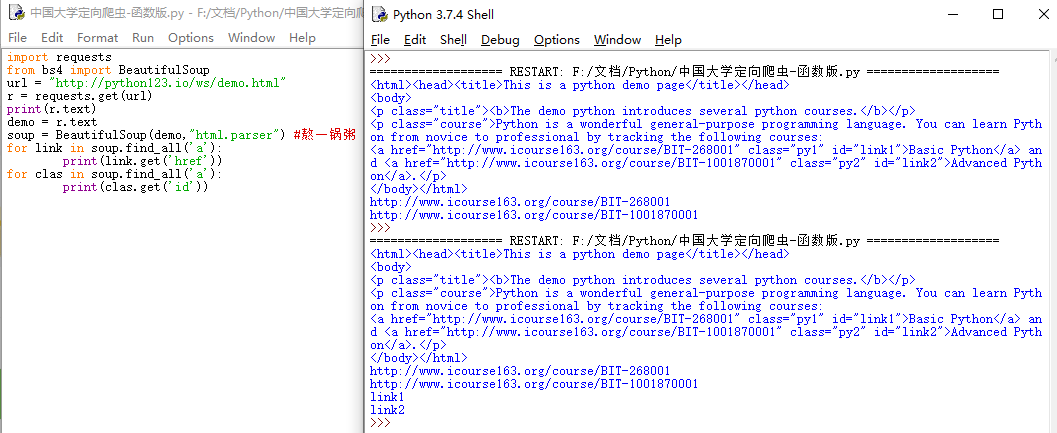

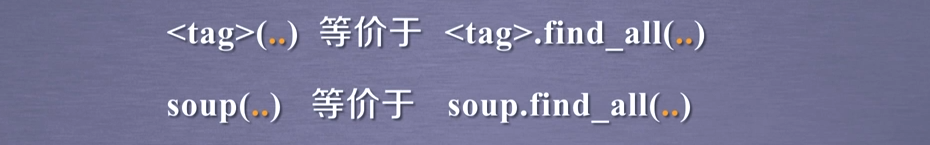

import requests
import re
from bs4 import BeautifulSoup
url = "http://python123.io/ws/demo.html"
r = requests.get(url)
print(r.text)
demo = r.text
soup = BeautifulSoup(demo,"html.parser") #熬一锅粥
for link in soup.find_all('a'):
print(link.get('href'))
for clas in soup.find_all('a'):
print(clas.get('class'))
#以下介绍find_all 正则表达式
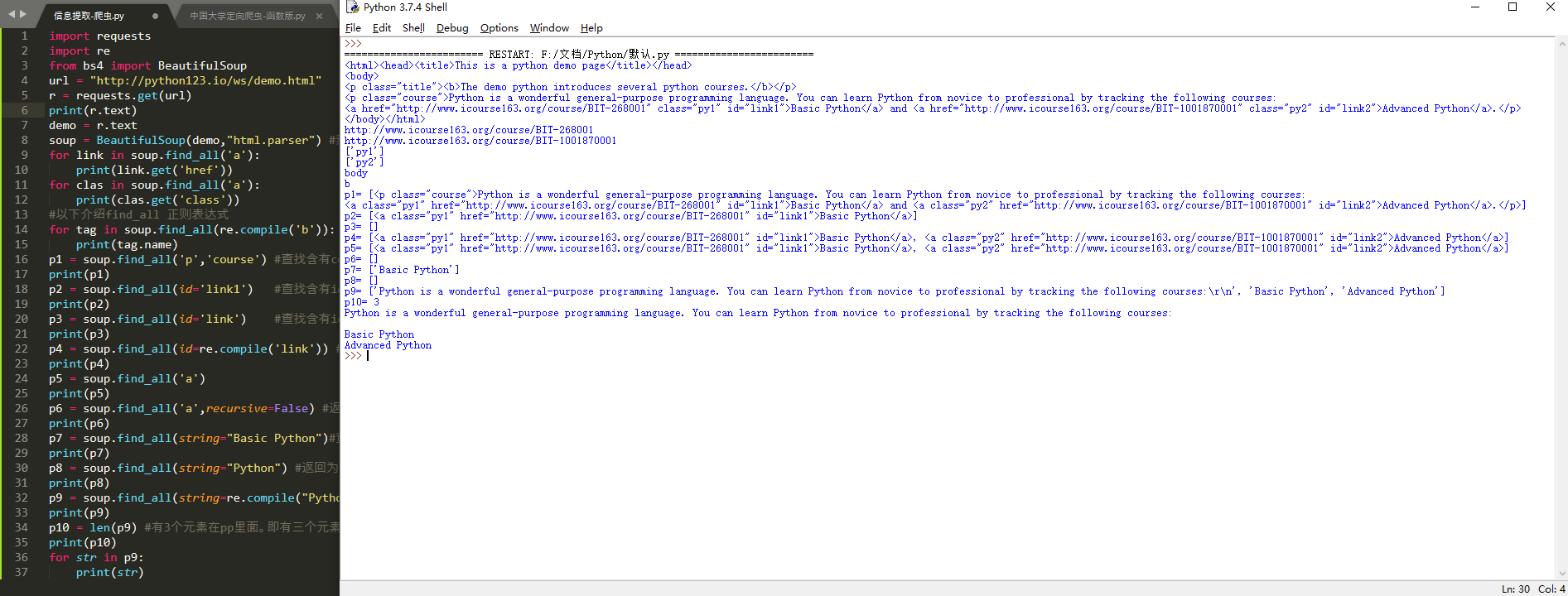
for tag in soup.find_all(re.compile('b')): #查找所有以b开头的标签,第一个属性
print(tag.name)
p1 = soup.find_all('p','course') #查找含有course的p标签内容
print(p1)
p2 = soup.find_all(id='link1') #查找含有id='link1'属性的标签内容,注意:属性不等于文本
print(p2)
p3 = soup.find_all(id='link') #查找含有id='link'属性的标签内容,没有,所以返回未空,即[]
print(p3)
p4 = soup.find_all(id=re.compile('link')) #使用正则表达式查找id属性含有link的内容
print(p4)
p5 = soup.find_all('a') #返回不为空,说明soup的子孙节点含有a标签
print(p5)
p6 = soup.find_all('a',recursive=False) #返回为空,说明soup的子节点无a标签
print(p6)
p7 = soup.find_all(string="Basic Python")#查找正文为且仅为Basic Python的元素
print(p7)
p8 = soup.find_all(string="Python") #返回为空
print(p8)
p9 = soup.find_all(string=re.compile("Python")) #正则表达式查找含有Python的元素,返回列表类型
print(p9)
p10 = len(p9) #有3个元素在pp里面。即有三个元素含Python
print(p10)
for str in p9:
print(str)
Python 信息提取-爬虫的更多相关文章
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
随机推荐
- Catalan数的理解
Catalan数的理解 f(0)=1 f(1)=1 f(2)=2 f(3)=5 f(4)=14 f(5)=42 f(2)=f(1)+f(1) f(3)=f(2)+f(1)*f(1)*f(2 ...
- 两行代码玩转SUMO!
两行代码玩转SUMO! 这篇博客很简单,但是内容很丰富 如何生成如下所示的研究型路网结构? 只需要打开ubuntu终端输入如下代码即可,grid.number代表路口数量,grid.length代表路 ...
- 构造函数语义学——Copy Constructor 的构造操作
前言 在三种情况下,会以一个 object 的内容作为另一个 class object 的初值: object明确初始化 class X{...}; X x; X xx = x; object 被当作 ...
- 学习c++11 ThreadPool【转】
#ifndef THREAD_POOL_H #define THREAD_POOL_H #include <vector> #include <queue> #include ...
- 【gradle使用前篇—Groovy简介】
Groovy介绍 Groovy是一种动态语言,对它的定义是:Groovy是在java平台上的,具有像Python.Ruby和smalltalk语言特性的灵活动态语言,Groovy保证了这些特性像jav ...
- 使用Typescript重构axios(七)——实现基础功能:处理响应header
0. 系列文章 1.使用Typescript重构axios(一)--写在最前面 2.使用Typescript重构axios(二)--项目起手,跑通流程 3.使用Typescript重构axios(三) ...
- C# - VS2019 通过DataGridView实现对Oracle数据表的增删改查
前言 通过VS2019建立WinFrm应用程序,搭建桌面程序后,通过封装数据库操作OracleHelper类和业务逻辑操作OracleSQL类,进而通过DataGridView实现对Oracle数据表 ...
- m98 lsc rp-- 赛
lsc 这次又烧rp了! T1随机化艹spj 本机测试输出字符串长度没有低于1W的,考完发现凉凉 但是lemon又救了我的*命,垃圾lsc又烧rp了!
- vue-snippet-模板
"template": { "prefix": "template", "body": [ "<temp ...
- Scrapy进阶知识点总结(二)——选择器Selectors
1. Selectors选择器 在抓取网页时,您需要执行的最常见任务是从HTML源提取数据.有几个库可用于实现此目的,例如: BeautifulSoup是Python程序员中非常流行的Web抓取库,它 ...