Python 信息提取-爬虫

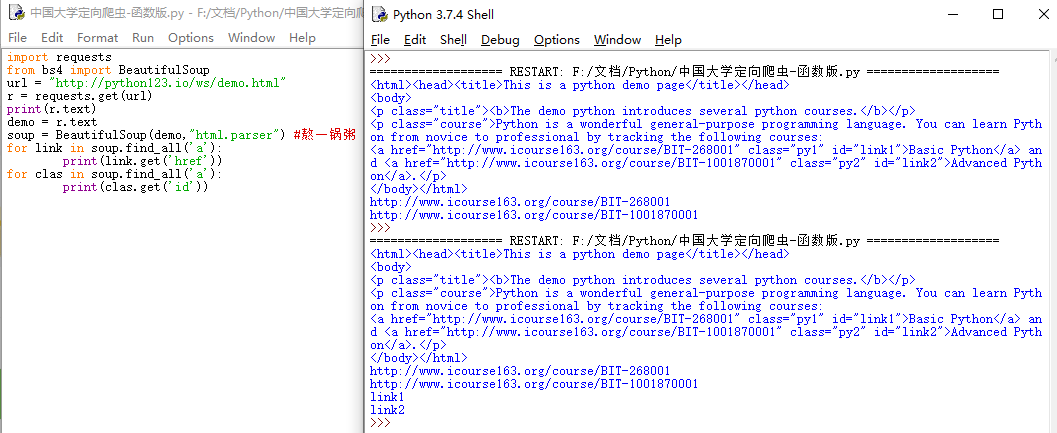

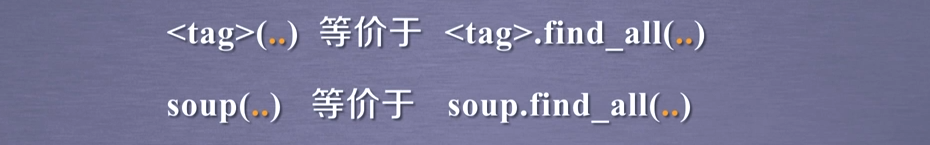

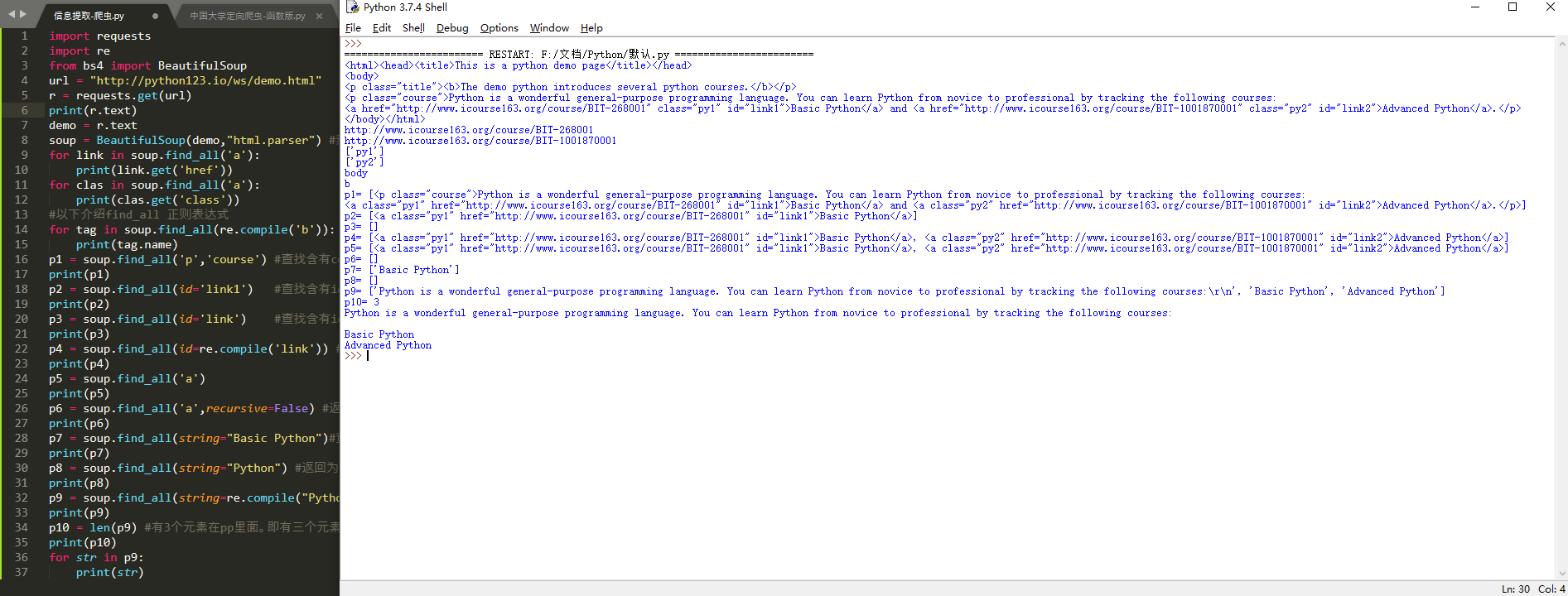
import requests
import re
from bs4 import BeautifulSoup
url = "http://python123.io/ws/demo.html"
r = requests.get(url)
print(r.text)
demo = r.text
soup = BeautifulSoup(demo,"html.parser") #熬一锅粥
for link in soup.find_all('a'):
print(link.get('href'))
for clas in soup.find_all('a'):
print(clas.get('class'))
#以下介绍find_all 正则表达式
for tag in soup.find_all(re.compile('b')): #查找所有以b开头的标签,第一个属性
print(tag.name)
p1 = soup.find_all('p','course') #查找含有course的p标签内容
print(p1)
p2 = soup.find_all(id='link1') #查找含有id='link1'属性的标签内容,注意:属性不等于文本
print(p2)
p3 = soup.find_all(id='link') #查找含有id='link'属性的标签内容,没有,所以返回未空,即[]
print(p3)
p4 = soup.find_all(id=re.compile('link')) #使用正则表达式查找id属性含有link的内容
print(p4)
p5 = soup.find_all('a') #返回不为空,说明soup的子孙节点含有a标签
print(p5)
p6 = soup.find_all('a',recursive=False) #返回为空,说明soup的子节点无a标签
print(p6)
p7 = soup.find_all(string="Basic Python")#查找正文为且仅为Basic Python的元素
print(p7)
p8 = soup.find_all(string="Python") #返回为空
print(p8)
p9 = soup.find_all(string=re.compile("Python")) #正则表达式查找含有Python的元素,返回列表类型
print(p9)
p10 = len(p9) #有3个元素在pp里面。即有三个元素含Python
print(p10)
for str in p9:
print(str)
Python 信息提取-爬虫的更多相关文章
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
随机推荐
- p6spy打印SQL
一 Springboot项目 <dependency> <groupId>p6spy</groupId> <artifactId>p6spy</a ...
- List、Set集合系列之剖析HashSet存储原理(HashMap底层)
目录 List接口 1.1 List接口介绍 1.2 List接口中常用方法 List的子类 2.1 ArrayList集合 2.2 LinkedList集合 Set接口 3.1 Set接口介绍 Se ...
- Rust 中的类型转换
1. as 运算符 as 运算符有点像 C 中的强制类型转换,区别在于,它只能用于原始类型(i32 .i64 .f32 . f64 . u8 . u32 . char 等类型),并且它是安全的. 例 ...
- 学习笔记59_python字符串处理
python中,字符串可以使用 '或"括起来 1. 要想写成 "hellow "aaaa" ",在python中,可以"hellow ' ...
- 创建 numpy.array
# 导包 import numpy as np numpy.array nparr = np.array([i for i in range(10)]) nparr # array([0, 1, 2, ...
- [转载]2.5 UiPath循环活动Do While的介绍和使用
一.Do While的介绍 先执行循环体, 再判断条件是否满足, 如果满足, 则再次执行循环体, 直到判断条件不满足, 则跳出循环. 二.Do While在UiPath中的使用 1. 打开设计器,在设 ...
- Mybatis MapperScannerConfigurer 自动扫描 将Mapper接口生成代理注入到Spring - 大新博客 - 推酷 - 360安全浏览器 7.1
Mybatis MapperScannerConfigurer 自动扫描 将Mapper接口生成代理注入到Spring - 大新博客 时间 2014-02-11 21:08:00 博客园-所有随笔区 ...
- 深入理解计算机系统 第二章 信息的表示和处理 Part2 第二遍
<深入理解计算机系统> 第三版 第二遍读这本书,每周花两到三小时时间,能读多少读多少(这次看了 29 ~ 34 页) 第一遍对应笔记链接 https://www.cnblogs.com/s ...
- IDEA中WEB项目本地调试和发布的配置分开配置
一个Web项目,开发的时候设置了一些本地内容,比如IP地址,还有本地目录等.开发完成后,要发布到服务器上时,这些本地相关的配置,就需要配置成服务器上IP或目录. 原先的做法就是部署打包的时候,把相关的 ...
- thinkphp分页样式css代码
<style type="text/css"> .Pagination a:hover,.current{background-color: #f54281;borde ...