kube-state-metrics 详解
原文:https://mp.weixin.qq.com/s/176eyFBknzdA5wpiJrxDSg
概述
已经有了 cadvisor、heapster、metric-server,几乎容器运行的所有指标都能拿到,但是下面这种情况却无能为力:
我调度了多少个 replicas?现在可用的有几个?
多少个 Pod 是 running/stopped/terminated 状态?
Pod 重启了多少次?
我有多少 job 在运行中
而这些则是 kube-state-metrics 提供的内容,它基于 client-go 开发,轮询 Kubernetes API,并将 Kubernetes的结构化信息转换为metrics。
功能
kube-state-metrics 提供的指标,按照阶段分为三种类别:
1.实验性质的:k8s api 中 alpha 阶段的或者 spec 的字段。
2.稳定版本的:k8s 中不向后兼容的主要版本的更新
3.被废弃的:已经不在维护的。
指标类别包括:
- CronJob Metrics
- DaemonSet Metrics
- Deployment Metrics
- Job Metrics
- LimitRange Metrics
- Node Metrics
- PersistentVolume Metrics
- PersistentVolumeClaim Metrics
- Pod Metrics
- Pod Disruption Budget Metrics
- ReplicaSet Metrics
- ReplicationController Metrics
- ResourceQuota Metrics
- Service Metrics
- StatefulSet Metrics
- Namespace Metrics
- Horizontal Pod Autoscaler Metrics
- Endpoint Metrics
- Secret Metrics
- ConfigMap Metrics
以 Pod 为例:
- kube_pod_info
- kube_pod_owner
- kube_pod_status_phase
- kube_pod_status_ready
- kube_pod_status_scheduled
- kube_pod_container_status_waiting
- kube_pod_container_status_terminated_reason
- ...
使用
部署清单地址:https://github.com/kubernetes/kube-state-metrics/tree/master/kubernetes
主要镜像有: image: quay.io/coreos/kube-state-metrics:v1.5.0 image: k8s.gcr.io/addon-resizer:1.8.3(参考metric-server文章,用于扩缩容)
对于pod的资源限制,一般情况下:
200MiB memory 0.1 cores
超过100节点的集群:
2MiB memory per node 0.001 cores per node
kube-state-metrics 做过一次性能优化,具体内容参考下文
部署成功后,prometheus的target会出现如下标志
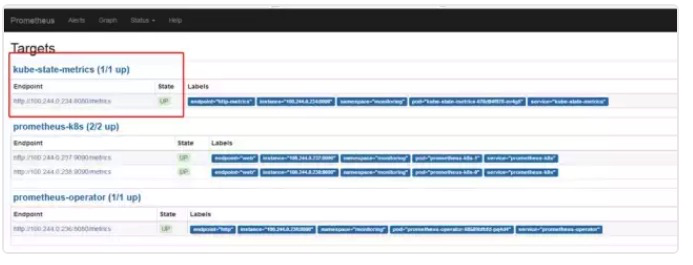
因为 kube-state-metrics-service.yaml 中有 prometheus.io/scrape:'true'标识,因此会将 metric 暴露给 Prometheus,而 Prometheus 会在 kubernetes-service-endpoints 这个 job 下自动发现kube-state-metrics,并开始拉取 metrics,无需其他配置。
使用 kube-state-metrics 后的常用场景有:
存在执行失败的 Job:
kube_job_status_failed{job="kubernetes-service-endpoints",k8s_app="kube-state-metrics"}==1集群节点状态错误:
kube_node_status_condition{condition="Ready",status!="true"}==1集群中存在启动失败的 Pod:
kube_pod_status_phase{phase=~"Failed|Unknown"}==1最近30分钟内有 Pod 容器重启:
changes(kube_pod_container_status_restarts[30m])>0
配合报警可以更好地监控集群的运行
与metric-server的对比
metric-server(或heapster)是从 api-server 中获取 cpu、内存使用率这种监控指标,并把他们发送给存储后端,如 influxdb 或云厂商,他当前的核心作用是:为 HPA 等组件提供决策指标支持。
kube-state-metrics 关注于获取 k8s 各种资源的最新状态,如 deployment 或者 daemonset,之所以没有把kube-state-metrics 纳入到 metric-server 的能力中,是因为他们的关注点本质上是不一样的。metric-server仅仅是获取、格式化现有数据,写入特定的存储,实质上是一个监控系统。而 kube-state-metrics 是将 k8s 的运行状况在内存中做了个快照,并且获取新的指标,但他没有能力导出这些指标
换个角度讲,kube-state-metrics 本身是 metric-server 的一种数据来源,虽然现在没有这么做。
另外,像 Prometheus 这种监控系统,并不会去用 metric-server 中的数据,他都是自己做指标收集、集成的(Prometheus包含了metric-server的能力),但 Prometheus 可以监控 metric-server 本身组件的监控状态并适时报警,这里的监控就可以通过 kube-state-metrics 来实现,如 metric-server pod 的运行状态。
深入解析
kube-state-metrics 本质上是不断轮询 api-server,代码结构也很简单,主要代码目录:
.├── collectors│ ├── builder.go│ ├── collectors.go│ ├── configmap.go│ ......│ ├── testutils.go│ ├── testutils_test.go│ └── utils.go├── constant│ └── resource_unit.go├── metrics│ ├── metrics.go│ └── metrics_test.go├── metrics_store│ ├── metrics_store.go│ └── metrics_store_test.go├── options│ ├── collector.go│ ├── options.go│ ├── options_test.go│ ├── types.go│ └── types_test.go├── version│ └── version.go└── whiteblacklist├── whiteblacklist.go└── whiteblacklist_test.go
所有类型:
var (DefaultNamespaces = NamespaceList{metav1.NamespaceAll}DefaultCollectors = CollectorSet{"daemonsets": struct{}{},"deployments": struct{}{},"limitranges": struct{}{},"nodes": struct{}{},"pods": struct{}{},"poddisruptionbudgets": struct{}{},"replicasets": struct{}{},"replicationcontrollers": struct{}{},"resourcequotas": struct{}{},"services": struct{}{},"jobs": struct{}{},"cronjobs": struct{}{},"statefulsets": struct{}{},"persistentvolumes": struct{}{},"persistentvolumeclaims": struct{}{},"namespaces": struct{}{},"horizontalpodautoscalers": struct{}{},"endpoints": struct{}{},"secrets": struct{}{},"configmaps": struct{}{},})
构建对应的收集器
Family即一个类型的资源集合,如 job 下的 kubejobinfo、kubejobcreated,都是一个 FamilyGenerator 实例
metrics.FamilyGenerator {Name: "kube_job_info",Type: metrics.MetricTypeGauge,Help: "Information about job.",GenerateFunc: wrapJobFunc(func(j *v1batch.Job) metrics.Family {return metrics.Family{&metrics.Metric{Name: "kube_job_info",Value: 1,}}}),},func (b *Builder) buildCronJobCollector() *Collector {// 过滤传入的白名单filteredMetricFamilies := filterMetricFamilies(b.whiteBlackList, cronJobMetricFamilies)composedMetricGenFuncs := composeMetricGenFuncs(filteredMetricFamilies)// 将参数写到header中familyHeaders := extractMetricFamilyHeaders(filteredMetricFamilies)// NewMetricsStore实现了client-go的cache.Store接口,实现本地缓存。store := metricsstore.NewMetricsStore(familyHeaders,composedMetricGenFuncs,)// 按namespace构建Reflector,监听变化reflectorPerNamespace(b.ctx, b.kubeClient, &batchv1beta1.CronJob{}, store, b.namespaces, createCronJobListWatch)return NewCollector(store)}
性能优化:
kube-state-metrics 在之前的版本中暴露出两个问题:
1./metrics 接口响应慢(10-20s)
2.内存消耗太大,导致超出 limit 被杀掉
问题一的方案就是基于 client-go 的 cache tool 实现本地缓存,具体结构为:
var cache = map[uuid][]byte{}
问题二的的方案是:对于时间序列的字符串,是存在很多重复字符的(如 namespace 等前缀筛选),可以用指针或者结构化这些重复字符。
优化点和问题
1.因为 kube-state-metrics 是监听资源的 add、delete、update 事件,那么在 kube-state-metrics 部署之前已经运行的资源,岂不是拿不到数据?kube-state-metric 利用 client-go 可以初始化所有已经存在的资源对象,确保没有任何遗漏
2.kube-state-metrics 当前不会输出 metadata 信息(如 help 和 description)
3.缓存实现是基于 golang 的 map,解决并发读问题当期是用了一个简单的互斥锁,可以解决问题,后续会考虑golang 的 sync.Map 安全 map。
4.kube-state-metrics 通过比较 resource version 来保证 event 的顺序
5.kube-state-metrics 并不保证包含所有资源
kube-state-metrics 详解的更多相关文章
- java.lang.Thread.State类详解
public static enum Thread.Stateextends Enum<Thread.State>线程状态.线程可以处于下列状态之一: 1.NEW 至今尚未启动的线程的状态 ...
- Ambari Metrics 详解
Ambari Metrics 原理 Ambari Metrics System 简称为 AMS,它主要为系统管理员提供了集群性能的监察功能.Metrics 一般分为 Cluster.Host 以及 S ...
- Android----drawable state各个属性详解----ListView几个比较特别的属性:
android:drawable 放一个drawable资源android:state_pressed 是否按下,如一个按钮触摸或者点击.android:state_focused 是否取得焦点,比如 ...
- 执行bin/hdfs haadmin -transitionToActive nn1时出现,Automatic failover is enabled for NameNode at bigdata-pro02.kfk.com/192.168.80.152:8020 Refusing to manually manage HA state的解决办法(图文详解)
不多说,直接上干货! 首先, 那么,你也许,第一感觉,是想到的是 全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解) 这里,nn1,不多赘述了.很简 ...
- “全栈2019”Java多线程第十章:Thread.State线程状态详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- vuex的使用及持久化state的方式详解
vuex的使用及持久化state的方式详解 转载 更新时间:2018年01月23日 09:09:37 作者:baby格鲁特 我要评论 这篇文章主要介绍了vuex的使用及持久化state的方 ...
- centos7.2环境elasticsearch-5.0.1+kibana-5.0.1+zookeeper3.4.6+kafka_2.9.2-0.8.2.1部署详解
centos7.2环境elasticsearch-5.0.1+kibana-5.0.1+zookeeper3.4.6+kafka_2.9.2-0.8.2.1部署详解 环境准备: 操作系统:centos ...
- hadoop2-MapReduce详解
本文是对Hadoop2.2.0版本的MapReduce进行详细讲解.请大家要注意版本,因为Hadoop的不同版本,源码可能是不同的. 以下是本文的大纲: 1.获取源码2.WordCount案例分析3. ...
- 基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8、0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口)
不多说,直接上干货! 至于为什么,要写这篇博客以及安装Kafka-manager? 问题详情 无奈于,在kafka里没有一个较好自带的web ui.启动后无法观看,并且不友好.所以,需安装一个第三方的 ...
- kafka启动时出现FATAL Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer) java.io.IOException: Permission denied错误解决办法(图文详解)
首先,说明,我kafk的server.properties是 kafka的server.properties配置文件参考示范(图文详解)(多种方式) 问题详情 然后,我启动时,出现如下 [hadoop ...
随机推荐
- 冰多多团队Beta阶段发布说明
Bingduoduo 语音Coding(Beta):项目Github地址 Beta版本新功能介绍 在beta阶段我们很好地将alpha阶段已经设计好的编辑器和shell整合了起来,推出了一个完整的ID ...
- Policy Gradient Algorithms
Policy Gradient Algorithms 2019-10-02 17:37:47 This blog is from: https://lilianweng.github.io/lil-l ...
- Redis 键的过期删除策略及缓存淘汰策略
前言 Redis缓存淘汰策略与Redis键的过期删除策略并不完全相同,前者是在Redis内存使用超过一定值的时候(一般这个值可以配置)使用的淘汰策略:而后者是通过定期删除+惰性删除两者结合的方式进行内 ...
- Java基础 awt Button 点击按钮后在控制台输出文字
JDK :OpenJDK-11 OS :CentOS 7.6.1810 IDE :Eclipse 2019‑03 typesetting :Markdown code ...
- Spring 内部机制 Spring AOP
https://my.oschina.net/zhangxufeng/blog/2219005 Spring Bean注册解析(一)和Spring Bean注册解析(二) 彻底征服 Spring AO ...
- Qt编写安防视频监控系统(界面很漂亮)
一.前言 视频监控系统在整个安防领域,已经做到了烂大街的程序,全国起码几百家公司做过类似的系统,当然这一方面的需求量也是非常旺盛的,各种定制化的需求越来越多,尤其是这几年借着人脸识别的东风,发展更加迅 ...
- WPF--控件模板的视觉效果呈现流程及逻辑
外部通过属性把数据--传递给-->(破拆后)内部可视化树 ----> 内部可视化树呈现出视觉效果 ----> 各种内部可视化组件的视觉效果组合 --- 呈现 --> 外部的 ...
- Grammar01 语法七要素之一_词类
1 词类 1.1 词类表格 实词 名词 -> n. -> noun -> 给所有人和物命名的词. 动词 -> v. (vt. vi.) -> verb ( transit ...
- Zipkin+Sleuth 链路追踪整合
1.Zipkin 是一个开放源代码分布式的跟踪系统 它可以帮助收集服务的时间数据,以解决微服务架构中的延迟问题,包括数据的收集.存储.查找和展现 每个服务向zipkin报告计时数据,zipkin会根据 ...
- 使用清华源进行pip install
pypi 镜像使用帮助 pypi 镜像每 5 分钟同步一次. 临时使用 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-pac ...