大数据学习——mapreduce程序单词统计
项目结构
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId>
<artifactId>MyWordCount</artifactId>
<packaging>jar</packaging>
<version>1.0</version> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.4</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>cn.itcast.mapreduce.WordCountDriver</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
WordCountMapper.java
package cn.itcast.mapreduce; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import static com.sun.corba.se.spi.activation.IIOP_CLEAR_TEXT.value; /**
* @author AllenWoon
* <p>
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN:是指框架读取到的数据的key类型
* 在默认的读取数据组件InputFormat下,读取的key是一行文本的偏移量,所以key的类型是long类型的
* <p>
* VALUEIN指框架读取到的数据的value类型
* 在默认的读取数据组件InputFormat下,读到的value就是一行文本的内容,所以value的类型是String类型的
* <p>
* keyout是指用户自定义逻辑方法返回的数据中key的类型 这个是由用户业务逻辑决定的。
* 在我们的单词统计当中,我们输出的是单词作为key,所以类型是String
* <p>
* VALUEOUT是指用户自定义逻辑方法返回的数据中value的类型 这个是由用户业务逻辑决定的。
* 在我们的单词统计当中,我们输出的是单词数量作为value,所以类型是Integer
* <p>
* 但是,String ,Long都是jdk中自带的数据类型,在序列化的时候,效率比较低。hadoop为了提高序列化的效率,他就自己自定义了一套数据结构。
* <p>
* 所以说在我们的hadoop程序中,如果该数据需要进行序列化(写磁盘,或者网络传输),就一定要用实现了hadoop序列化框架的数据类型
* <p>
* <p>
* Long------->LongWritable
* String----->Text
* Integer---->IntWritable
* null------->nullWritable
*/ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /**
* 这个map方法就是mapreduce程序中被主体程序MapTask所调用的用户业务逻辑方法
* Maptask会驱动我们的读取数据组件inputFormat去读取数据(KEYIN,VALUEIN),每读取一个(k,v),也就会传入到这个用户写的map方法中去调用一次
* 在默认的inputFormat实现中,此处的key就是一行的起始偏移量,value就是一行的内容
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String lines = value.toString();
String[] words = lines.split(" ");
for (String word : words) {
context.write(new Text(word), new IntWritable(1)); }
} }
WordCountReducer.java
package cn.itcast.mapreduce; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /***
* @author AllenWoon
* <p>
* reducetask在调用我们的reduce方法
* <p>
* reducetask应该接收到map阶段(前一阶段)中所有maptask输出的数据中的一部分;
* (key.hashcode% numReduceTask==本ReduceTask编号)
* <p>
* reducetask将接收到的kv数据拿来处理时,是这样调用我们的reduce方法的:
* <p>
* 先讲自己接收到的所有的kv对按照k分组(根据k是否相同)
* <p>
* 然后将一组kv中的k传给我们的reduce方法的key变量,把这一组kv中的所有的v用一个迭代器传给reduce方法的变量values
*/ public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0; for (IntWritable v : values) {
count += v.get();
}
context.write(key, new IntWritable(count));
} }
WordCountDriver.java
package cn.itcast.mapreduce; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; /**
* @author AllenWoon
* <p>
* 本类是客户端用来指定wordcount job程序运行时候所需要的很多参数
* <p>
* 比如:指定哪个类作为map阶段的业务逻辑类 哪个类作为reduce阶段的业务逻辑类
* 指定用哪个组件作为数据的读取组件 数据结果输出组件
* 指定这个wordcount jar包所在的路径
* <p>
* ....
* 以及其他各种所需要的参数
*/
public class WordCountDriver { public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//告诉框架,我们的程序所在jar包的位置
job.setJar("/root/wordcount.jar"); //告诉程序,我们的程序所用好的mapper类和reduce类是什么 job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class); //告诉框架,我们的程序输出的数据类型
job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputKeyClass(IntWritable.class); //告诉框架我们程序使用的数据读取组件 结果输出所用的组件是什么
//TextInputFormat是mapreduce程序中内置的一种读取数据的组件 准确的说叫做读取文本文件的输入组件 job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); //告诉框架,我们要处理的数据文件在哪个路径下
FileInputFormat.setInputPaths(job, new Path("/wordcount/input"));
//告诉框架我们的输出结果输出的位置 FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); Boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
} }
先建两个文件1.txt 2.txt
内容如下
1.txt
hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello
2.txt
hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello
在hdfs上创建文件夹
hadoop fs -mkdir -p /wordcount/input
把1.txt 2.txt放在/wordcount/input目录下
hadoop fs -put 1.txt 2.txt /wordcount/input
上传wordcount.jar

运行
hadoop jar wordcount.jar cn.itcast.mapreduce.WordCountDriver
查看生成的结果文件
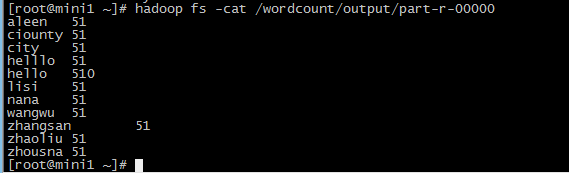
hadoop fs -cat /wordcount/output/part-r-00000



大数据学习——mapreduce程序单词统计的更多相关文章
- 大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF
1. 练习 数据: (1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额 第一步:将每天的金额求和(同一天可能会有多个订单) SELECT sid,dt,SUM(mone ...
- 大数据学习——MapReduce学习——字符统计WordCount
操作背景 jdk的版本为1.8以上 ubuntu12 hadoop2.5伪分布 安装 Hadoop-Eclipse-Plugin 要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 ...
- 大数据学习——mapreduce倒排索引
数据 a.txt hello jerry hello tom b.txt allen tom allen jerry allen hello c.txt hello jerry hello tom 1 ...
- 大数据学习——mapreduce汇总手机号上行流量下行流量总流量
时间戳 手机号 MAC地址 ip 域名 上行流量包个数 下行 上行流量 下行流量 http状态码 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 12 ...
- 大数据学习——mapreduce运营商日志增强
需求 1.对原始json数据进行解析,变成普通文本数据 2.求出每个人评分最高的3部电影 3.求出被评分次数最多的3部电影 数据 https://pan.baidu.com/s/1gPsQXVYSQE ...
- 大数据学习——mapreduce案例join算法
需求: 用mapreduce实现select order.orderid,order.pdtid,pdts.pdt_name,oder.amount from orderjoin pdtson ord ...
- 大数据学习——mapreduce学习topN问题
求每一个订单中成交金额最大的那一笔 top1 数据 Order_0000001,Pdt_01,222.8 Order_0000001,Pdt_05,25.8 Order_0000002,Pdt_05 ...
- 大数据学习——mapreduce共同好友
数据 commonfriends.txt A:B,C,D,F,E,O B:A,C,E,K C:F,A,D,I D:A,E,F,L E:B,C,D,M,L F:A,B,C,D,E,O,M G:A,C,D ...
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
随机推荐
- 学习JavaScript数据结构与算法 (二)
学习JavaScript数据结构与算法 的笔记 包含第四章队列, 第五章链表 本人所有文章首发在博客园: http://www.cnblogs.com/zhangrunhao/ 04队列 实现基本队列 ...
- Node.Js的Module System 以及一些常用 Module
Node.Js学习就按照这本书的流程来. 在第7章结束与第10章结束时分别自己出一个小项目练练手.Node.Js的入门学习计划是这样. 目录:, QQ:1045642972 欢迎来索书以及讨论Node ...
- Java关键字-volatile
关键字volatile可以说是Java虚拟机提供的最轻量级的同步机制. 一旦某个共享变量(类的成员变量.类的静态成员变量)被volatile修饰之后,那么就具备了两层语义: 1.保证了不同线程对这个变 ...
- java读取大文件 超大文件的几种方法
java 读取一个巨大的文本文件既能保证内存不溢出又能保证性能 import java.io.BufferedReader; import java.io.File; import jav ...
- (C#)Xamarin.ios 发布到 App Store
项目做到尾声了,IOS要发布,程序猿力Max来了. 不过就公司开发者账号就弄了一个月多,期间因为申请过D-U-N-S客服联系要公司资料时我们中途说取消了,后来再申请不知多少次了都没再回复... 给美国 ...
- 一个PHP开发APP接口的视频教程
感觉php做接口方面的教程很少,无意中搜到了这个视频教程,希望能给一些人带来帮助http://www.imooc.com/learn/163
- 吸顶条 ---- jQ写法
<script> $(function () { var barTop = $('#bar').offset().top; //on方法相当于原生的绑定 $(window).on('scr ...
- Dreamoon and MRT
Dreamoon and MRT 题目链接: http://codeforces.com/group/gRkn7bDfsN/contest/212299/problem/B 只需要考虑相对位置,设a0 ...
- python爬虫---实现项目(一) Requests爬取HTML信息
上面的博客把基本的HTML解析库已经说完了,这次我们来给予几个实战的项目. 这次主要用Requests库+正则表达式来解析HTML. 项目一:爬取猫眼电影TOP100信息 代码地址:https://g ...
- Linux Shell参数扩展(Parameter Expansion)
Shell Command Language在线文档: http://pubs.opengroup.org/onlinepubs/9699919799/utilities/V3_chap02.html ...