ElasticSearch(六):IK分词器的安装与使用IK分词器创建索引
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了。
1. ik分词器的下载和安装,测试
第一: 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases ,这里你需要根据你的Es的版本来下载对应版本的IK,这里我使用的是6.3.2的ES,所以就下载ik-6.3.2.zip的文件。
第二: 解压-->将文件复制到 es的安装目录/plugin/ik下面即可,完成之后效果如下:
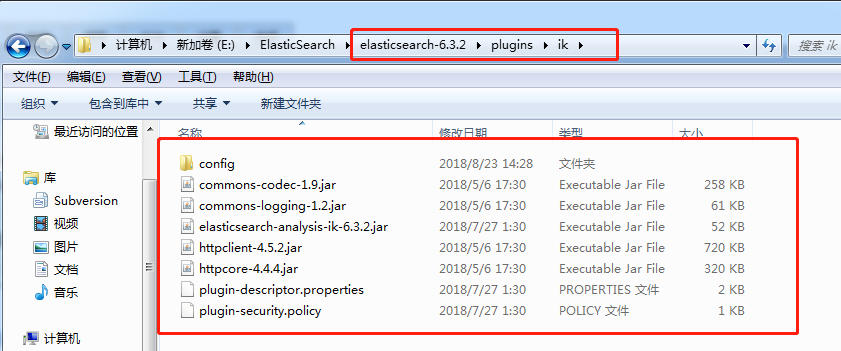
到这里已经完成了,不需要去elasticSearch的 elasticsearch.yml 文件去配置。
第三:重启ElasticSearch
第四:测试效果
未使用ik分词器的时候测试分词效果:
POST book/_analyze
{
"text": "我是中国人"
}
//结果是:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "中",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "国",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "人",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
}
]
}
使用IK分词器之后,结果如下:
POST book_v6/_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
//结果如下:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国人",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}
对于上面两个分词效果的解释:
1. 如果未安装ik分词器,那么,你如果写 "analyzer": "ik_max_word",那么程序就会报错,因为你没有安装ik分词器
2. 如果你安装了ik分词器之后,你不指定分词器,不加上 "analyzer": "ik_max_word" 这句话,那么其分词效果跟你没有安装ik分词器是一致的,也是分词成每个汉字。
2. 创建指定分词器的索引
索引创建之后就可以使用ik进行分词了,当你使用ES搜索的时候也会使用ik对搜索语句进行分词,进行匹配。
PUT book_v5
{
"settings":{
"number_of_shards": "6",
"number_of_replicas": "1",
//指定分词器
"analysis":{
"analyzer":{
"ik":{
"tokenizer":"ik_max_word"
}
}
}
},
"mappings":{
"novel":{
"properties":{
"author":{
"type":"text"
},
"wordCount":{
"type":"integer"
},
"publishDate":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss || yyyy-MM-dd"
},
"briefIntroduction":{
"type":"text"
},
"bookName":{
"type":"text"
}
}
}
}
}
关于ik分词器的分词类型(可以根据需求进行选择):
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。如下:
POST book_v6/_analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
//结果
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}
ElasticSearch(六):IK分词器的安装与使用IK分词器创建索引的更多相关文章
- IK分词器的安装与使用IK分词器创建索引
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了. 1. i ...
- ElasticSearch从不懂到会用1—安装篇
连续加班近一个多月,项目终于告一段落了,也腾出时间写一写项目中用到的东西.在这个项目中,我负责的主要是多种业务场景下的数据查询和搜索,其中搜索用到了ElasticSearch搜索引擎.下面主要围绕El ...
- docker上安装elasticsearch和ik分词器插件和header,实现分词功能
docker run -di --name=tensquare_es -p 9200: -p 9300:9300 elasticsearch:5.6.8 创建elasticsearch容器(如果版本不 ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
- Elasticsearch之文档的增删改查以及ik分词器
文档的增删改查 增加文档 使用elasticsearch-head查看 修改文档 使用elasticsearch-head查看 删除文档 使用elasticsearch-head查看 查看文档的三种方 ...
- es的插件 ik分词器的安装和使用
今天折腾了一天,在es 5.5.0 上安装ik.一直通过官方给定的命令没用安装成功,决定通过手工是形式进行安装.https://github.com/medcl/elasticsearch-analy ...
- elasticsearch分词插件的安装
IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Luen ...
- Elasticsearch是一个分布式可扩展的实时搜索和分析引擎,elasticsearch安装配置及中文分词
http://fuxiaopang.gitbooks.io/learnelasticsearch/content/ (中文) 在Elasticsearch中,文档术语一种类型(type),各种各样的 ...
- 【elasticsearch】(3)centos7 安装中文分词插件elasticsearch-analyzer-ik
前言 elasticsearch(下面简称ES,安装ES点击这里)的自带standard分词只能把汉语分割成一个个字,而不能分词.分段,这就是我们需要分析器ik的地方了. 一.下载ik的相应版本 查看 ...
随机推荐
- hihoCoder 1513 小Hi的烦恼
hihoCoder 1513 小Hi的烦恼 思路: 用bitset判断交集个数 代码: #include<bits/stdc++.h> using namespace std; #defi ...
- Codeforces 431C - k-Tree
431C - k-Tree 思路:dp. dp[i][j][s] 如果s为1,表示第i层长度为j且至少包含一段>=d的距离的路径数 如果s为0,表示第i层长度为j且不包含一段>=d的距离的 ...
- 生成全球唯一标识GUID
有时候我们操作数据的时候需要给这些数据一些编码,而这些编码又希望永远不会重复!这个时候微软的C#给了我们一个函数,这个函数产生的编码全球唯一,永远不会重复! 方法如下: 1.C#生成方式 string ...
- protected internal == internal
总结:在同程序集下,protected internal类型修饰的成员变量可以在基类或派生类的类内.类外访问(同程序集下protected internal和internal访问性质相同,此处保留了i ...
- 20170617xlVBA销售数据分类汇总
Public Sub SubtotalData() AppSettings 'On Error GoTo ErrHandler Dim StartTime, UsedTime As Variant S ...
- CentOS 配置Tomcat服务脚本
#!/bin/bash # description: Tomcat7 Start Stop Restart # processname: tomcat7 # chkconfig: JAVA_HOME= ...
- Python Install for windows X64
download python 3.7.2 for windows, https://www.python.org/ run python-3.7.2.exe
- JavaScript语言简介
Web程序不论是B/S还是C/S构架,分为客户端程序与服务器端程序两种. ASP.NET是开发服务器端程序的强大工具,但有时为了降低服务器负担与通信流量,这就需要编写能够在客户端执行的程序. 脚本语言 ...
- 规格化设计-----JSF(第三次博客作业)
从20世纪60年代开始,就存在着许多不同的形式规格说明语言和软件开发方法.在形式规格说明领域一些最主要的发展过程列举如下: 1969-1972 C.A.R Hoare撰写了"计算机编程的公理 ...
- textAlign
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head> < ...