2.深度学习中的batch_size的理解
Batch_Size(批尺寸)是机器学习中一个重要参数,涉及诸多矛盾,下面逐一展开。
首先,为什么需要有 Batch_Size 这个参数?
Batch 的选择,首先决定的是下降的方向。如果数据集比较小,完全可以采用全数据集 ( Full Batch Learning )的形式,这样做至少有 2 个好处:其一,由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。其二,由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。 Full Batch Learning 可以使用 Rprop只基于梯度符号并且针对性单独更新各权值。
对于更大的数据集,以上 2 个好处又变成了 2 个坏处:其一,随着数据集的海量增长和内存限制,一次性载入所有的数据进来变得越来越不可行。其二,以 Rprop 的方式迭代,会由于各个 Batch 之间的采样差异性,各次梯度修正值相互抵消,无法修正。这才有了后来 RMSProp 的妥协方案。
既然 Full Batch Learning 并不适用大数据集,那么走向另一个极端怎么样?
所谓另一个极端,就是每次只训练一个样本,即 Batch_Size = 1。这就是在线学习(Online Learning)。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。使用在线学习,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。如图所示:
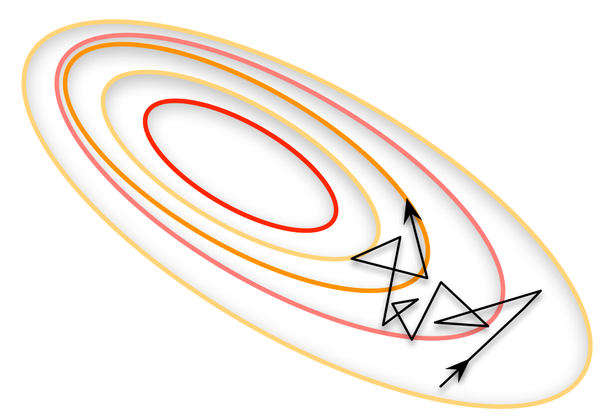
可不可以选择一个适中的 Batch_Size 值呢?
当然可以,这就是批梯度下降法(Mini-batches Learning)。因为如果数据集足够充分,那么用一半(甚至少得多)的数据训练算出来的梯度与用全部数据训练出来的梯度是几乎一样的。
在合理范围内,增大 Batch_Size 有何好处?
- 内存利用率提高了,大矩阵乘法的并行化效率提高。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
- 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
盲目增大 Batch_Size 有何坏处?
- 内存利用率提高了,但是内存容量可能撑不住了。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
- Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
调节 Batch_Size 对训练效果影响到底如何?
这里跑一个 LeNet 在 MNIST 数据集上的效果。MNIST 是一个手写体标准库,我使用的是 Theano 框架。这是一个 Python 的深度学习库。安装方便(几行命令而已),调试简单(自带 Profile),GPU / CPU 通吃,官方教程相当完备,支持模块十分丰富(除了 CNNs,更是支持 RBM / DBN / LSTM / RBM-RNN / SdA / MLPs)。在其上层有 Keras 封装,支持 GRU / JZS1, JZS2, JZS3 等较新结构,支持 Adagrad / Adadelta / RMSprop / Adam 等优化算法。如图所示:
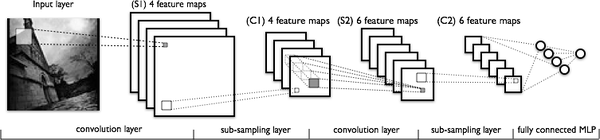
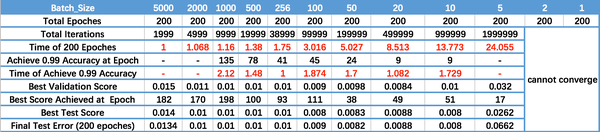
运行结果如上图所示,其中绝对时间做了标幺化处理。运行结果与上文分析相印证:
- Batch_Size 太小,算法在 200 epoches 内不收敛。
- 随着 Batch_Size 增大,处理相同数据量的速度越快。
- 随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
- 由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
- 由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优
2.深度学习中的batch_size的理解的更多相关文章
- 关于深度学习中的batch_size
5.4.1 关于深度学习中的batch_size 举个例子: 例如,假设您有1050个训练样本,并且您希望设置batch_size等于100.该算法从训练数据集中获取前100个样本(从第1到第100个 ...
- 深度学习中dropout策略的理解
现在有空整理一下关于深度学习中怎么加入dropout方法来防止测试过程的过拟合现象. 首先了解一下dropout的实现原理: 这些理论的解释在百度上有很多.... 这里重点记录一下怎么实现这一技术 参 ...
- 深度学习中的batch_size,iterations,epochs等概念的理解
在自己完成的几个有关深度学习的Demo中,几乎都出现了batch_size,iterations,epochs这些字眼,刚开始我也没在意,觉得Demo能运行就OK了,但随着学习的深入,我就觉得不弄懂这 ...
- 从极大似然估计的角度理解深度学习中loss函数
从极大似然估计的角度理解深度学习中loss函数 为了理解这一概念,首先回顾下最大似然估计的概念: 最大似然估计常用于利用已知的样本结果,反推最有可能导致这一结果产生的参数值,往往模型结果已经确定,用于 ...
- 【转载】深度学习中softmax交叉熵损失函数的理解
深度学习中softmax交叉熵损失函数的理解 2018-08-11 23:49:43 lilong117194 阅读数 5198更多 分类专栏: Deep learning 版权声明:本文为博主原 ...
- 深度学习中的Data Augmentation方法(转)基于keras
在深度学习中,当数据量不够大时候,常常采用下面4中方法: 1. 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data Augm ...
- 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- 卷积在深度学习中的作用(转自http://timdettmers.com/2015/03/26/convolution-deep-learning/)
卷积可能是现在深入学习中最重要的概念.卷积网络和卷积网络将深度学习推向了几乎所有机器学习任务的最前沿.但是,卷积如此强大呢?它是如何工作的?在这篇博客文章中,我将解释卷积并将其与其他概念联系起来,以帮 ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
随机推荐
- [转载]WebConfig配置文件详解
<?xml version="1.0"?> <!--注意: 除了手动编辑此文件以外,您还可以使用 Web 管理工具来配置应用程序的设置.可以使用 Visual S ...
- 【llinux】yum命令出现Loaded plugins: fastestmirror Determining fastest mirrors
在进行yum 安装的时候.报错了. Loaded plugins: fastestmirror Determining fastest mirrors fastestmirror是yum的一个加速插件 ...
- 题目1144:Freckles(最小生成树进阶)
题目链接:http://ac.jobdu.com/problem.php?pid=1144 详解链接:https://github.com/zpfbuaa/JobduInCPlusPlus 参考代码: ...
- Android 源码下载,国内 镜像
AOSP(Android) 镜像使用帮助 https://lug.ustc.edu.cn/wiki/mirrors/help/aosp 首先下载 repo 工具. mkdir ~/bin PATH=~ ...
- 一辈子只有1次成为BAT的机会,你如何把握?
本文转自:http://www.fmi.com.cn/index.php?m=content&c=index&a=show&catid=9&id=614308 感谢作者 ...
- 一、laya学习笔记 --- layabox环境搭建 HelloWorld(坑:ts版本问题解决方案)
好吧,使用layabox需要从官网下载些啥呢 一.下载layabox 官网 https://www.layabox.com/ 首页上有两个,一个Engine,一个IDE Engine我下载的TS版本, ...
- 23种设计模式之单例模式(Singleton)
单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,它提供全局访问的方法. public class SingleTon { private static Si ...
- 解决启动Distributed Transaction Coordinator服务出错的问题
解决启动Distributed Transaction Coordinator服务出错的问题 "Windows 不能在 本地计算机 启动 Distributed Transaction ...
- Node学习HTTP模块(HTTP 服务器与客户端)
Node学习HTTP模块(HTTP 服务器与客户端) Node.js 标准库提供了 http 模块,其中封装了一个高效的 HTTP 服务器和一个简易的HTTP 客户端.http.Server 是一个基 ...
- where are you from
where are you from 如果问美国人这句话的话,他们一般会说: I'm from California. I'm from Pennsylvanian. 一般是说州,而不是说Americ ...