Python爬虫教程-19-数据提取-正则表达式(re)
本篇主页内容:match的基本使用,search的基本使用,findall,finditer的基本使用,匹配中文,贪婪与非贪婪模式
Python爬虫教程-19-数据提取-正则表达式(re)
- 正则表达式:一套规则,可以在字符串文本中进行搜查替换等
- 正则使用步骤:
- 1.使用 compile 函数将正则表达式的字符串编译成一个 pattern 对象
- 2.通过 pattern 对象的一些方法对文本进行匹配,匹配结果是一个 match 对象
- 3.用 match 对象的方法,对结果进行操作
- 正则的常用方法:
- match:从开始位置开始查找,一次匹配,即1次匹配成功则退出
- search:从任何位置开始查找,一次匹配
- findall:全部匹配,返回列表
- finditer:全部匹配,返回迭代器
- split:分割字符串,返回列表
- sub:替换
- 匹配中文
- 中文是Unicode编码(utf-8也是Unicode编码),范围:主要在[u4e00-u9fa5]
- 中文全角逗号一类的不在[u4e00-u9fa5]范围内
- 贪婪与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配
- python里面数量词默认是贪婪模式
- 例如:
- 查找文本abbbbbbbccc
- re结果是: ab*
- 贪婪模式结果是:abbbbbbb
- 非贪婪模式结果是:a
案例v23 match的基本使用
# 正则结果match的使用案例
import re
# 以下正则分成2个组,以小括号为单位
# [a-z]表示出现小写a-z任意字母都可以,+表示至少出现1次
# 两组之间有一个空格,表示匹配的两个英文字符之间有空格
s = r"([a-z]+) ([a-z]+)"
# 编译
pattern = re.compile(s, re.I) # s, I表示忽略大小写
m = pattern.match("Hello world wide web")
# group(0) 表示返回整个匹配成功的字符串,即所有小组
s = m.group(0)
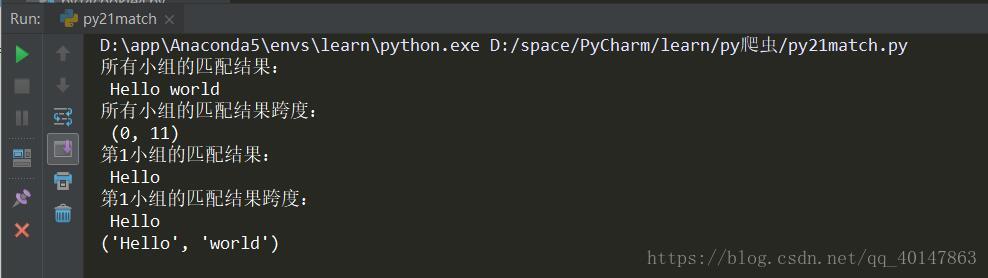
print("所有小组的匹配结果:\n", s)
# 返回匹配成功的整个字符串的跨度,即所有小组
a = m.span(0)
print("所有小组的匹配结果跨度:\n", a)
# group(0) 表示返回的第一个分组匹配成功的字符串
s = m.group(1)
print("第1小组的匹配结果:\n", s)
# 返回匹配成功的整个字符串的跨度
a = m.span(1)
print("第1小组的匹配结果跨度:\n", s)
# groups() 打印出所有的小组,等价于m.group(1), m.group(2)...
s = m.groups()
print(s)
运行结果
从结果可以看到:匹配到两个小组,一个Hello,一个world,中间的空格是外面的,代码中包含一些具体的输出格式
案例v24 search的基本使用
# search的基本使用
import re
s = r'\d+'
pattern = re.compile(s)
# 无参数表示从头开始查找,到最后结束
m = pattern.search("one12two34three56")
print(m.group(0))
# 参数表明搜查的范围,例如:10-40
m = pattern.search("one12two34three56", 10, 40)
print(m.group(0))
运行结果
因为是从第10个开始查找,所以查到的是56

案例v25 findall,finditer的基本使用
# findall,finditer的基本使用
import re
s = r'\d+'
pattern = re.compile(s)
m = pattern.findall("I am 18 years old, and 185 high")
print(m)
n = pattern.finditer("I am 18 years old, and 185 high")
print(type(n))
# 迭代器使用for循环输出
for i in n:
# 只输出i会包含无用数据
print(i.group())
运行结果
查找所有匹配的字符串

匹配中文
# 中文unicode案例
import re
hello = u'你好,再见陌生人'
# 中文全角逗号一类的不在[u4e00-u9fa5]范围内
pattern = re.compile(r'[\u4e00-\u9fa5]+')
m = pattern.findall(hello)
print(m)
运行结果
因为中文全角逗号一类的不在[u4e00-u9fa5]范围内,所在 findall 返回的是一个列表,包含两个值

更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-19-数据提取-正则表达式(re)的更多相关文章
- Python爬虫教程-24-数据提取-BeautifulSoup4(二)
Python爬虫教程-24-数据提取-BeautifulSoup4(二) 本篇介绍 bs 如何遍历一个文档对象 遍历文档对象 contents:tag 的子节点以列表的方式输出 children:子节 ...
- Python爬虫教程-23-数据提取-BeautifulSoup4(一)
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc. ...
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫 什么是分布式爬虫 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集.单机爬虫就是只在一 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
随机推荐
- ajax 的error参数
ajax发生错误会进入到error中,我们在这里把错误信息从控制台中输出出来,为了避免每次写ajax都得写好几个console.log(). 我在这里写一个模板,需要用的时候直接过来拷贝. error ...
- mysql 设置默认时间为now()
TIMESTAMP的变体1,TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP在创建新记录和修改现有记录的时候都对这个数据列 ...
- 深刻理解Python中的元类(metaclass)(转)
转载地址:http://blog.jobbole.com/21351/ 另外有几点理解记录下: 创建一个实例时,有时会传入参数,这些参数会同时传入 __init__() 和 __new__(),如: ...
- webpack+vue解决前端跨域问题
webpack 跨域,在这里整理了一下逻辑首先不是为了axios库来进行跨域的,而是直接通过node的webpack设置代理来完成跨域的. 先贴一条自己请求的连接 1.设置自定义域: 在config目 ...
- [转] Hive函数大全
1.内置运算符 1.1关系运算符 运算符 类型 说明 A = B 所有原始类型 如果A与B相等,返回TRUE,否则返回FALSE A == B 无 失败,因为无效的语法. SQL使用”=”,不使用”= ...
- CentOS6.5安装testlink1.9.14
前提条件:准备一台CentOS6.5虚拟机,配置好IP,关闭iptables和selinux. 这里提供上我的云盘软件,可以去这里下载:http://pan.baidu.com/s/1qXymele ...
- 一个数字键盘引发的血案——移动端H5输入框、光标、数字键盘全假套件实现
https://juejin.im/post/5a44c5eef265da432d2868f6 为啥要写假键盘? 还是输入框.光标全假的假键盘? 手机自带的不用非得写个假的,吃饱没事干吧? 装逼?炫技 ...
- iis支持asp.net4.0的注册命令使用方法及部署网站注意事项
如果没有按照正常的先装iis后装.net的顺序,可以使用以下命令重新注册一下,这样iis就可以支持asp.net 4.0了 32位的Windows: 1. 运行->cmd,打开窗口时请以管理 ...
- 浅谈Supermap iClient for JavaScript 弹窗类
地图作为信息的载体和呈现方式,是GIS的重要组成部分,它是一个浏览信息的窗口,在信息日益发达的今天 ,各种地图应用如雨后春笋一般出现在大众眼前,而不是像以往一样太过局限于专业的领域.而弹窗,是作为地图 ...
- [Unity3D]Shader编程之动态屏幕遮罩
转载 https://blog.csdn.net/u012741077/article/details/78425834 屏幕可视范围跟随目标物体移动,可修改可视范围大小,边缘渐变大小.以及遮罩颜色, ...