Java基础-爬虫实战之爬去校花网网站内容
Java基础-爬虫实战之爬去校花网网站内容
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
爬虫这个实现点我压根就没有把它当做重点,也没打算做网络爬虫工程师,说起爬虫我更喜欢用Python实现!下面是Java爬虫的代码如下:
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.reptilian; import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL; public class ReptilianDemo {
public static void main(String[] args) throws IOException {
//定义需要爬取的网站
URL url = new URL("http://www.xiaohuar.com/");
//建立连接
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
//设置请求方式
conn.setRequestMethod("GET");
//获取服务器响应的状态码
int code = conn.getResponseCode();
//判断状态码是否为200,如果是说明访问成功,那么就开始下载页面
if(code == 200){
InputStream in = conn.getInputStream() ;
FileOutputStream out = new FileOutputStream("D:\\BigData\\JavaSE\\yinzhengjieData\\校花网.html",false) ;
byte[] buf = new byte[1024] ;
int len = 0 ;
while((len = in.read(buf)) != -1){
// System.out.println(new String(buf ,0 ,len , "utf-8" ));
out.write(buf , 0 , len);
}
in.close();
out.close();
System.out.println("下载完成!");
}
}
} /*
以上代码执行结果如下:
下载完成!
*/
查看爬去后的文件:
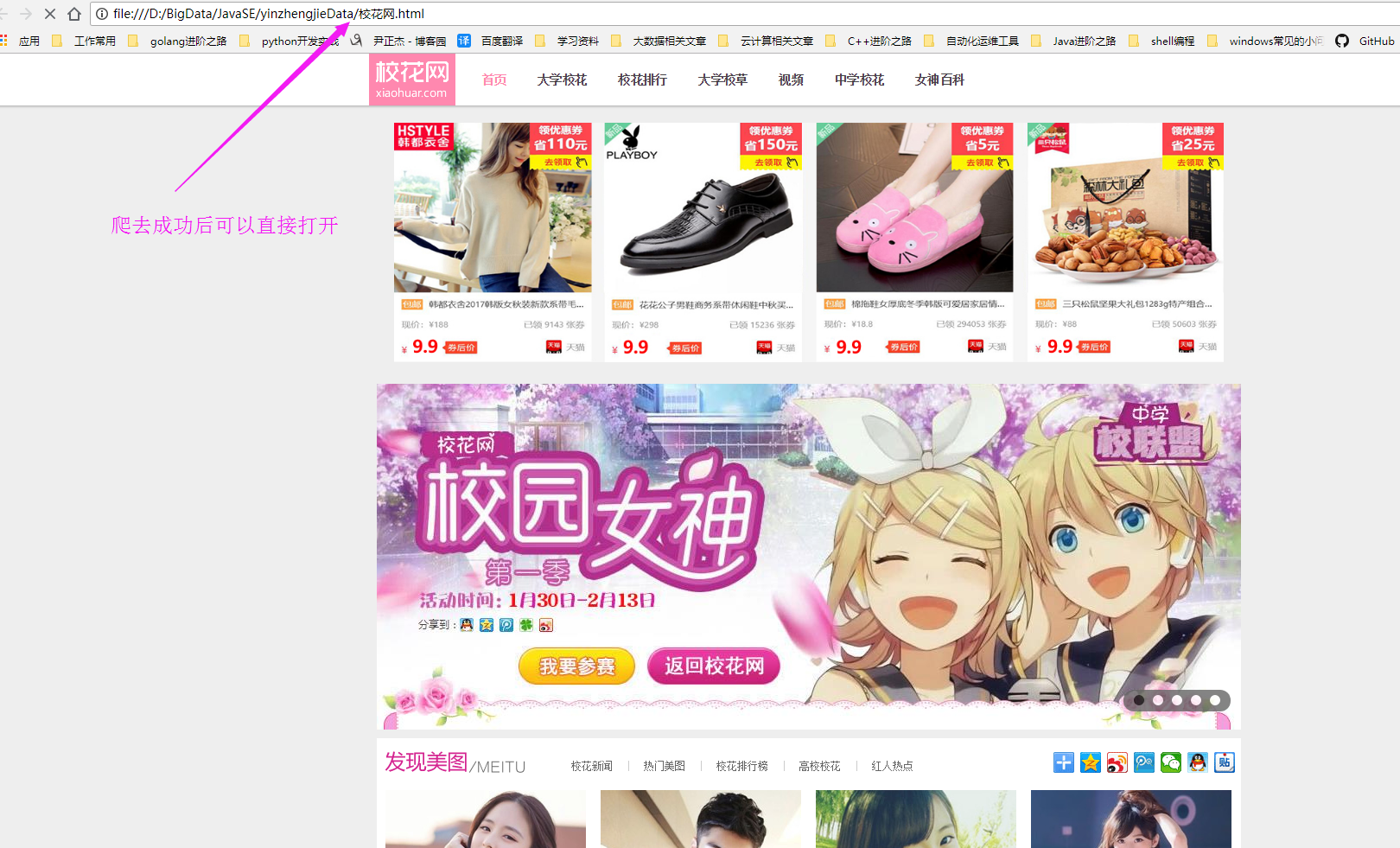
Java基础-爬虫实战之爬去校花网网站内容的更多相关文章
- Scrapy爬虫框架之爬取校花网图片
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- python实战项目 — 爬取 校花网图片
重点: 1. 指定路径创建文件夹,判断是否存在 2. 保存图片文件 # 获得校花网的地址,图片的链接 import re import requests import time import os ...
- python爬虫基础应用----爬取校花网视频
一.爬虫简单介绍 爬虫是什么? 爬虫是首先使用模拟浏览器访问网站获取数据,然后通过解析过滤获得有价值的信息,最后保存到到自己库中的程序. 爬虫程序包括哪些模块? python中的爬虫程序主要包括,re ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- Go语言实战-爬取校花网图片
一.目标网站分析 爬取校花网http://www.xiaohuar.com/大学校花所有图片. 经过分析,所有图片分为四个页面,http://www.xiaohuar.com/list-1-0.htm ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战——反爬策略之模拟登录【CSDN】
在<Python爬虫实战-- Request对象之header伪装策略>中,我们就已经讲到:=="在header当中,我们经常会添加两个参数--cookie 和 User-Age ...
- 爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章 一.简说安装相关环境及依赖包 1.安装Python(2或3都行,我这里用的是3) 2.虚拟环境搭建: 依赖包:virtualenv,virtualenvwr ...
随机推荐
- 【ORACLE】oracle11g单实例安装
-- 上传安装包 p13390677_112040_Linux-x86-64_1of7.zip p13390677_112040_Linux-x86-64_2of7.zip -- 解压安装包 unzi ...
- flask_admin 笔记二 授权和权限
权限当然就是让有应该权限的用户能执行某些操作,把没有权限的用户限制在外面.Flask-admin提供了几种方法来处理: 1, Http basic Auth 最简单的身份验证形式是HTTP基本身份验证 ...
- SonarQube 平台搭建代码审查平台步骤
SonarQube 平台1.下载包,安装启动2.在sonar.properties 配置mysql数据库的sonar.jdbc.username=sonarsonar.jdbc.password=so ...
- Redux系列x:源码解析
写在前面 redux的源码很简洁,除了applyMiddleware比较绕难以理解外,大部分还是 这里假设读者对redux有一定了解,就不科普redux的概念和API啥的啦,这部分建议直接看官方文档. ...
- ECS centos7 使用外部邮件服务商的465加密端口
ECS centos7 使用外部邮件服务商的465加密端口发送邮件. 1.修改/etc/mail.rc 文件中添加以下的 set smtp="smtps://smtp.163.com:465 ...
- PAT甲题题解-1121. Damn Single (25)-水题
博主欢迎转载,但请给出本文链接,我尊重你,你尊重我,谢谢~http://www.cnblogs.com/chenxiwenruo/p/6789787.html特别不喜欢那些随便转载别人的原创文章又不给 ...
- 20135202闫佳歆--week7 可执行程序的装载--学习笔记
此为个人学习笔记存档 week 7 可执行程序的装载 一.预处理.编译.链接和目标文件的格式 可执行文件的创建--预处理.编译和链接 cd Code vi hello.c gcc -E -o hell ...
- 20135337朱荟潼 Linux第四周学习总结——扒开系统调用的三层皮(上)
朱荟潼 + 原创作品转载请注明出处 + <Linux内核分析>MOOC课http://mooc.study.163.com/course/USTC 1000029000 知识点梳理 一.用 ...
- 英语学习APP
第一部分 调研, 评测 下载并使用,描述最简单直观的个人第一次上手体验. 界面高大上,看起来很美观,是个不错的英语学习软件.我很喜欢. 2.按照<构建之法>13.1节描述的 bug 定义, ...
- springboot+mybatis结合使用
springboot+mybatis结合使用与普通的ssm配置差别不大,但是少了很多的配置,如spring.xml web.xml, 给程序员减轻了很多负担 首先创建带有mybatis框架的项目 ...