大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
一、集群提交任务流程分析
1.集群提交操作
参考:https://www.jianshu.com/p/6783f1ec2da0
2.任务分配与启动流程
参考:https://www.cnblogs.com/heitaok/p/5531535.html
二、相关目录树
1.组件本地目录树

2.storm zk目录树

三、集群通信
Worker间的通信经常需要通过网络跨节点进行,Storm使用ZeroMQ或Netty(0.9以后默认使用)作为进程间通信的消息框架。
Worker进程内部通信:不同worker的thread通信使用LMAX Disruptor来完成。
不同topologey之间的通信,Storm不负责,需要自己想办法实现,例如使用kafka等;
通信图解:
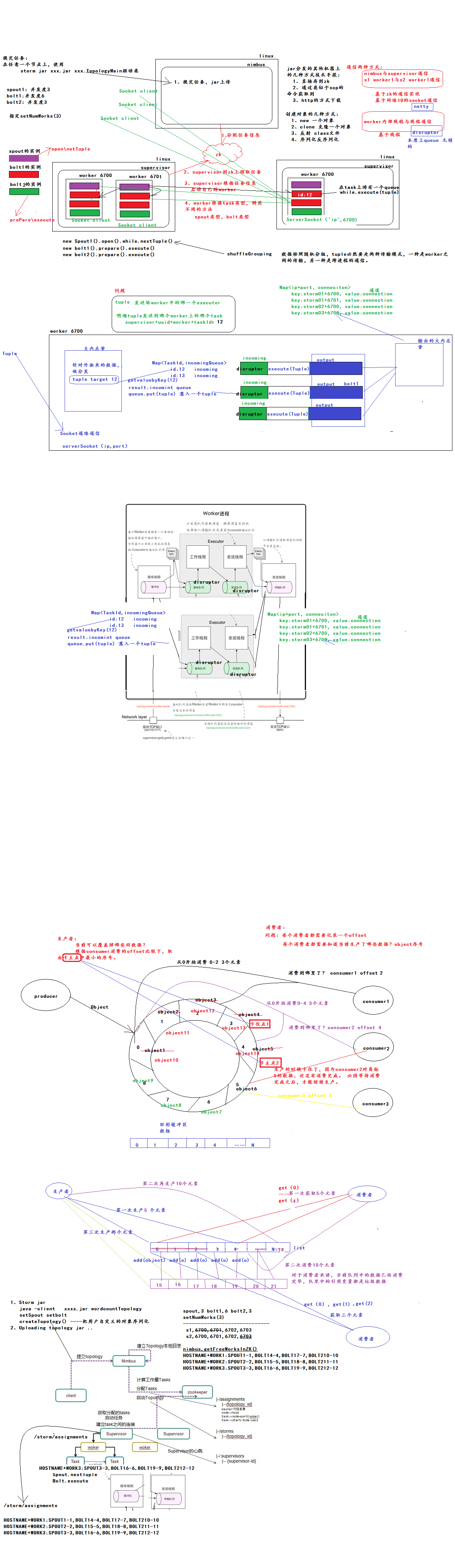
相关博文参考:http://blog.csdn.net/bbaiggey/article/details/55510010?locationNum=10&fps=1
四、消息容错机制ack-fail
1.概述
l 在storm中,可靠的信息处理机制是从spout开始的。
l 一个提供了可靠的处理机制的spout需要记录他发射出去的tuple,当下游bolt处理tuple或者子tuple失败时spout能够重新发射。
l Storm通过调用Spout的nextTuple()发送一个tuple。为实现可靠的消息处理,首先要给每个发出的tuple带上唯一的ID,并且将ID作为参数传递给 SoputOutputCollector的emit()方法:collector.emit(new Values("value1","value2"), msgId); messageid就是用来标示唯一的tuple的,而rootid是随机生成的
给每个tuple指定ID告诉Storm系统,无论处理成功还是失败,spout都要接收tuple树上所有节点返回的通知。
如果处理成功,spout的ack()方法将会对编号是 msgId的消息应答确认;如果处理失败或者超时,会调用fail()方法。
2.基本实现
Storm 系统中有一组叫做"acker"的特殊的任务,它们负责跟踪DAG(有向无环图)中的每个消息。
acker任务保存了spout id到一对值的映射。第一个值就是spout的任务id,通过这个id,acker就知道消息处理完成时该通知哪个spout任务。第二个值是一个64bit的数字,我们称之为"ack val", 它是树中所有消息的随机id的异或计算结果。
ack val表示了整棵树的的状态,无论这棵树多大,只需要这个固定大小的数字就可以跟踪整棵树。当消息被创建和被应答的时候都会有相同的消息id发送过来做异或。 每当acker发现一棵树的ack val值为0的时候,它就知道这棵树已经被完全处理了
要实现ack机制:
,spout发射tuple的时候指定messageId
,spout要重写BaseRichSpout的fail和ack方法
,spout对发射的tuple进行缓存(否则spout的fail方法收到acker发来的messsageId,
spout也无法获取到发送失败的数据进行重发),看看系统提供的接口,
只有msgId这个参数,这里的设计不合理,其实在系统里是有cache整个msg的,只给用户一个messageid,
用户如何取得原来的msg貌似需要自己cache,然后用这个msgId去查询,太坑爹了
,spout根据messageId对于ack的tuple则从缓存队列中删除,对于fail的tuple可以选择重发。
,设置acker数至少大于0;Config.setNumAckers(conf, ackerParal);
3.代码示例
package ackfail; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder; /**
* Created by maoxiangyi on 2016/4/25.
*/
public class MyAckFailTopology { public static void main(String[] args) throws Exception {
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("mySpout", new MySpout(), 1);
topologyBuilder.setBolt("mybolt1", new MyBolt1(), 1).shuffleGrouping("mySpout"); Config conf = new Config();
String name = MyAckFailTopology.class.getSimpleName();
if (args != null && args.length > 0) {
String nimbus = args[0];
conf.put(Config.NIMBUS_HOST, nimbus);
conf.setNumWorkers(1);
StormSubmitter.submitTopologyWithProgressBar(name, conf, topologyBuilder.createTopology());
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(name, conf, topologyBuilder.createTopology());
Thread.sleep(60 * 60 * 1000);
cluster.shutdown();
}
}
}
MyAckFailTopology
package ackfail; import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IControlSpout;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values; import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import java.util.UUID; /**
* Created by maoxiangyi on 2016/4/25.
*/
public class MySpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private Random rand;
private Map<String,Values> buffer = new HashMap<>(); @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
rand = new Random();
} @Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
} @Override
public void nextTuple() {
String[] sentences = new String[]{"the cow jumped over the moon",
"the cow jumped over the moon",
"the cow jumped over the moon",
"the cow jumped over the moon", "the cow jumped over the moon"};
String sentence = sentences[rand.nextInt(sentences.length)];
String messageId = UUID.randomUUID().toString().replace("-", "");
Values tuple = new Values(sentence);
collector.emit(tuple, messageId);
buffer.put(messageId,tuple);
try {
Thread.sleep(20000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} @Override
public void ack(Object msgId) {
System.out.println("消息处理成功,id= " + msgId);
buffer.remove(msgId);
} @Override
public void fail(Object msgId) {
System.out.println("消息处理失败,id= " + msgId);
Values tuple = buffer.get(msgId);
collector.emit(tuple,msgId);
}
}
MySpout
package ackfail; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.*;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; import java.util.Map; /**
* Created by maoxiangyi on 2016/4/25.
*/
public class MyBolt1 extends BaseRichBolt {
private OutputCollector collector; @Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
} @Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for (String word : words) {
word = word.trim();
if (!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(input, new Values(word));
}
}
collector.ack(input);
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
} }
MyBolt1
4.参考阅读
https://www.cnblogs.com/intsmaze/p/5918087.html
大数据入门第十六天——流式计算之storm详解(三)集群相关进阶的更多相关文章
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 大数据入门第十六天——流式计算之storm详解(二)常用命令与wc实例
一.常用命令 1.提交命令 提交任务命令格式:storm jar [jar路径] [拓扑包名.拓扑类名] [拓扑名称] torm jar examples/storm-starter/storm-st ...
- 大数据入门第十四天——Hbase详解(一)入门与安装配置
一.概述 1.什么是Hbase 根据官网:https://hbase.apache.org/ Apache HBase™ is the Hadoop database, a distributed, ...
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- 大数据入门第十四天——Hbase详解(二)基本概念与命令、javaAPI
一.hbase数据模型 完整的官方文档的翻译,参考:https://www.cnblogs.com/simple-focus/p/6198329.html 1.rowkey 与nosql数据库们一样, ...
- 大数据入门第十五天——HBase整合:云笔记项目
一.功能简述 1.笔记本管理(增删改) 2.笔记管理 3.共享笔记查询功能 4.回收站 效果预览: 二.库表设计 1.设计理念 将云笔记信息分别存储在redis和hbase中. redis(缓存):存 ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(一)入门与集群安装
一.概述 1.kafka是什么 根据标题可以有个概念:kafka是storm的上游数据源之一,也是一对经典的组合,就像郭德纲和于谦 根据官网:http://kafka.apache.org/intro ...
随机推荐
- Kubernetes+Docker的云平台在CentOS7系统上的安装
Kubernetes+Docker的云平台在CentOS7系统上的安装 1.运行VirtualBox5. 2.安装CentOS7系统. 注意:选择Basic Server类型 安装过程略. 3.修改计 ...
- Linux 中 awk命令应用
ls -la | awk '{printf ("%8s %8s %8s %8s %8s %8s %8s %8s %8s\n",$1,$2,$3,$4,$5,$6,$7,$8,sub ...
- ActiveReports 报表控件V12新特性 -- RPX报表转换为RDL报表
ActiveReports是一款专注于 .NET 平台的报表控件,全面满足 HTML5 / WinForms / ASP.NET / ASP.NET MVC / WPF 等平台下报表设计和开发工作需求 ...
- windows 服务的安装与卸载
卸载服务 Cmd 执行 Sc delete axXinkong(服务名称) 安装服务
- python学习笔记之——操作mysql数据库
Python 标准数据库接口为 Python DB-API,Python DB-API为开发人员提供了数据库应用编程接口. Python 数据库接口支持非常多的数据库,你可以选择适合你项目的数据库: ...
- flutter 防止键盘弹出 导致超出屏幕
return Scaffold( appBar: AppBar( elevation: 0.0, title: new Text("登陆"), ), resizeToAvoidBo ...
- Problem5-Project Euler
Smallest multiple 2520 is the smallest number that can be divided by each of the numbers from 1 to ...
- sql server对并发的处理-乐观锁和悲观锁(转)
假如两个线程同时修改数据库同一条记录,就会导致后一条记录覆盖前一条,从而引发一些问题. 例如: 一个售票系统有一个余票数,客户端每调用一次出票方法,余票数就减一. 情景: 总共300张票,假设两个售票 ...
- 异常System.BadImageFormatException
[问题描述] Server Error in '/' Application. Could not load file or assembly 'WebDemo' or one of its depe ...
- Freemarket语法
<#--freemarker HashMap取值--> <#assign maps={"1":"张三丰","2":&quo ...