Python爬虫之三
1)使用Scrapy,什么叫做Scrapy
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
2)安装的Scrapy
$ : sudo pip3 install scrapy
3)确定要爬去网站
如:http://bolg.jobbole.com/
步骤为:
(1)在/home/下新建文件夹
如:testspider
(2)使用命令进入文件夹
$:cd ~/testspider
$~/testspider: scrapy startproject testspider
(3)在使用pycharm打开testspider

结构说明:
testSpider 项目的外壳
testSpider 项目目录
spiders 爬虫编写目录
__init__.py 包文件
__init__.py 包文件
item.py 数据模型文件
middlewares.py 中间件文件 proxy 代理ip
pipelines.py 数据输出管道文件
settings.py 项目的配置文件
scrapy.cfg scapy 的配置文件
(4)使用scrapy的基本模板创建
$~/testspider: scrapy startproject testspider

(5)查看pycharm工程
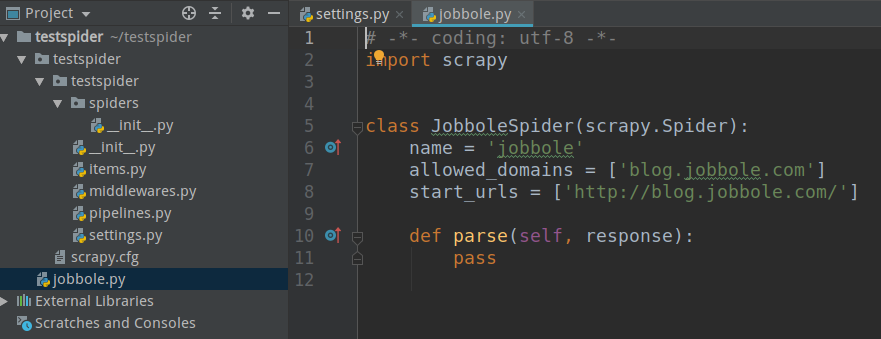
4)运行scrapy
书写程序
#启动程序
from scrapy.cmdline import execute
import sys
import os
print(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(os.path.dirname(os.path.abspath(__file__)))#获取当前路径
execute(["scrapy","crawl","jobbole"])
运行结果:
2019-03-23 20:09:58 [scrapy.utils.log] INFO: Versions: lxml 4.3.2.0, libxml2 2.9.9, cssselect 1.0.3, parsel 1.5.1, w3lib 1.20.0, Twisted 18.9.0, Python 3.6.7 (default, Oct 22 2018, 11:32:17) - [GCC 8.2.0], pyOpenSSL 19.0.0 (OpenSSL 1.1.0g 2 Nov 2017), cryptography 2.1.4, Platform Linux-4.18.0-16-generic-x86_64-with-Ubuntu-18.04-bionic
2019-03-23 20:09:58 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'testspider', 'NEWSPIDER_MODULE': 'testspider.spiders', 'SPIDER_MODULES': ['testspider.spiders']}
2019-03-23 20:09:58 [scrapy.extensions.telnet] INFO: Telnet Password: d217d79f472f437e
2019-03-23 20:09:58 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
...
5)xpath
使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
(1)xpath的简介

(2)xpath语法



(3)xpath的使用
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/114496/']
def parse(self, response):
re_selector_ = response.xpath("/html/body/div[3]/a/img")
pass
Python爬虫之三的更多相关文章
- Python爬虫之三种网页抓取方法性能比较
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块. 1. 正则表达式 如果你对正则表达式还不熟悉,或是需要一些提 ...
- Python爬虫之三种数据解析方式
一.引入 二.回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需 ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之三:Selenium 调用IEDriverServer 抓取数据
接着上一遍,在用Selenium+phantomjs 抓取数据过程中发现,有时候抓取不到,所以又测试了用Selenium+浏览器驱动的方式:具体代码如下: #coding=utf-8import os ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
随机推荐
- Vue slot插槽
插槽用于内容分发,存在于子组件之中. 插槽作用域 父级组件作用域为父级,子级组件作用域为子级,在哪定义的作用域就在哪. 子组件之间的内容是在父级作用域的,无法直接访问子组件里面的数据. 插槽元素 &l ...
- 虚拟机安装CentOS7(一)
软件环境 虚拟机:VMware Workstation Linux:CentOS-7-x86_64-DVD-1708.iso镜像文件 虚拟机所在电脑系统:win7 安装步骤 安装VMware 下载Li ...
- Java开发环境的搭建01——Eclipse篇(Windows)
搭建环境是换项目组和新入职的开发入项都必须面临的一件事情,搭搭环境,一天就过去了...本着不浪费生命不做重复的无用功,在这里写写环境搭建的基本功,这篇是介绍Java环境搭建,常见的开发IDE无非就两种 ...
- OpenCL——把vector变成scalar
https://stackoverflow.com/questions/46556471/how-may-i-convert-cast-scalar-to-vector-and-vice-versa- ...
- 【English】四、Y结尾名词变复数
一.辅音字母+y结尾的名词,将y改变为i,再加-es. 读音变化:加读[z]. 例: candy→candies; daisy→daisies; fairy→fairies; lady→ladies; ...
- java编译过程中出现了Exception in thread “main" java.lang.UnsupportedClassVersionError
原因:这个问题确实是由较高版本的JDK编译的java class文件试图在较低版本的JVM上运行产生的错误. 以下是报错截图: 1.解决措施就是保证jvm(java命令)和jdk(javac命令)版本 ...
- 浅析C#中new、override、virtual关键字的区别
Virtual : virtual 关键字用于修饰方法.属性.索引器或事件声明,并使它们可以在派生类中被重写. 默认情况下,方法是非虚拟的.不能重写非虚方法. virtual 修饰符不能与 stati ...
- js操作文章、字符串换行
操作前: 操作后: 第一步: 把中英文的逗号和顿号置换为 '\n’ support_unit = support_unit.replace(/,|,|./g, '\n') 第二步: //为了使\n ...
- ztree 为节点添加点击触发事件
<SCRIPT type="text/javascript"> var setting = { data : { key : { title : "code& ...
- mysql查询order by 指定字段排序
当MySQL查询时排序的字段不是数字时而是汉字的时候也可以用when then 来指定排序. 列如yewu_check表的status 字段不是0,1,2而是汉字待办,已办,退回.可以如下写法: S ...