OpenCL入门:(二:用GPU计算两个数组和)
本文编写一个计算两个数组和的程序,用CPU和GPU分别运算,计算运算时间,并且校验最后的运算结果。文中代码偏多,原理建议阅读下面文章,文中介绍了OpenCL相关名词概念。
http://opencl.codeplex.com/wikipage?title=OpenCL%20Tutorials%20-%201 (英文版)
http://www.cnblogs.com/leiben/archive/2012/06/05/2536508.html (博友翻译的中文版)
一、创建工程
按照OpenCL入门:(一:Intel核心显卡OpenCL环境搭建)的创建一个名为OpenCLSum的工程,并且添加一个OpenCLSum.cpp文件,一个OpenCLSum.cl文件(添加时选择添加OpenCL文件)。
二、CPU计算代码
用CPU求两个数组和的代码如下:
void RunAsCpu(
const float *nums1,
const float *nums2,
float* sum,
const int num)
{
for (int i = 0; i < num; i++)
{
sum[i] = nums1[i] + nums2[i];
}
}
三、GPU计算代码
在cl文件中添加如下代码,
//因为运行这个kernel时需要设置一个线程数目,
//所以每个线程都会调用一次这个函数,只需要使
//用get_global_id获取它的线程id就可以求和了
__kernel void RunAsGpu(
__global const float *nums1,
__global const float *nums2,
__global float* sum)
{
int id = get_global_id(0);
sum[id] = nums1[id] + nums2[id];
}
四、主函数流程
流程请参考本文开始推荐的文章,有详细说明,下面只在注释中简单说明
//计时函数
double time_stamp()
{
LARGE_INTEGER curclock;
LARGE_INTEGER freq;
if (
!QueryPerformanceCounter(&curclock) ||
!QueryPerformanceFrequency(&freq)
)
{
return -1;
} return double(curclock.QuadPart) / freq.QuadPart;
}
#define OPENCL_CHECK_ERRORS(ERR) \
if(ERR != CL_SUCCESS) \
{ \
cerr \
<< "OpenCL error with code " << ERR \
<< " happened in file " << __FILE__ \
<< " at line " << __LINE__ \
<< ". Exiting...\n"; \
exit(1); \
}
int main(int argc, const char** argv)
{
cl_int error = 0; // Used to handle error codes
cl_context context;
cl_command_queue queue;
cl_device_id device; // 遍历系统中所有OpenCL平台
cl_uint num_of_platforms = 0;
// 得到平台数目
error = clGetPlatformIDs(0, 0, &num_of_platforms);
OPENCL_CHECK_ERRORS(error);
cout << "可用平台数: " << num_of_platforms << endl; cl_platform_id* platforms = new cl_platform_id[num_of_platforms];
// 得到所有平台的ID
error = clGetPlatformIDs(num_of_platforms, platforms, 0);
OPENCL_CHECK_ERRORS(error);
//遍历平台,选择一个Intel平台的
cl_uint selected_platform_index = num_of_platforms;
for (cl_uint i = 0; i < num_of_platforms; ++i)
{
size_t platform_name_length = 0;
error = clGetPlatformInfo(
platforms[i],
CL_PLATFORM_NAME,
0,
0,
&platform_name_length
);
OPENCL_CHECK_ERRORS(error); // 调用两次,第一次是得到名称的长度
char* platform_name = new char[platform_name_length];
error = clGetPlatformInfo(
platforms[i],
CL_PLATFORM_NAME,
platform_name_length,
platform_name,
0
);
OPENCL_CHECK_ERRORS(error); cout << " [" << i << "] " << platform_name; if (
strstr(platform_name, "Intel") &&
selected_platform_index == num_of_platforms // have not selected yet
)
{
cout << " [Selected]";
selected_platform_index = i;
} cout << endl;
delete[] platform_name;
}
if (selected_platform_index == num_of_platforms)
{
cerr
<< "没有找到Intel平台\n";
return 1;
}
// Device
cl_platform_id platform = platforms[selected_platform_index];
error = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);
OPENCL_CHECK_ERRORS(error) // Context
context = clCreateContext(0, 1, &device, NULL, NULL, &error);
OPENCL_CHECK_ERRORS(error) // Command-queue
queue = clCreateCommandQueue(context, device, 0, &error);
OPENCL_CHECK_ERRORS(error) //下面初始化测试数据(主机数据)
const int size = 38888888;//大小和内存有关,仅作示例
float* nums1_h = new float[size];
float* nums2_h = new float[size];
float* sum_h = new float[size];
// Initialize both vectors
for (int i = 0; i < size; i++) {
nums1_h[i] = nums2_h[i] = (float)i;
}
//初始化设备数据
const int mem_size = sizeof(float)*size;
// 标志位表示数据只读,并且从nums1_h和nums2_h复制数据
cl_mem nums1_d = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, mem_size, nums1_h, &error);
OPENCL_CHECK_ERRORS(error)
cl_mem nums2_d = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, mem_size, nums2_h, &error);
OPENCL_CHECK_ERRORS(error)
cl_mem sum_d = clCreateBuffer(context, CL_MEM_WRITE_ONLY, mem_size, NULL, &error);
OPENCL_CHECK_ERRORS(error) //读取OpenCLSum.cl文件内容 FILE* fp = fopen("OpenCLSum.cl", "rb");
fseek(fp, 0, SEEK_END);
size_t src_size = ftell(fp);
fseek(fp, 0, SEEK_SET);
const char* source = new char[src_size];
fread((void*)source, 1, src_size, fp);
fclose(fp); //创建编译运行kernel函数
cl_program program = clCreateProgramWithSource(context, 1, &source, &src_size, &error);
OPENCL_CHECK_ERRORS(error)
delete[] source; // Builds the program
error = clBuildProgram(program, 1, &device, NULL, NULL, NULL);
OPENCL_CHECK_ERRORS(error) // Shows the log
char* build_log;
size_t log_size;
// First call to know the proper size
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0, NULL, &log_size);
build_log = new char[log_size + 1];
// Second call to get the log
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, log_size, build_log, NULL);
build_log[log_size] = '\0';
cout << build_log << endl;
delete[] build_log; // Extracting the kernel
cl_kernel run_as_gpu = clCreateKernel(program, "RunAsGpu", &error);
OPENCL_CHECK_ERRORS(error) //运行kernel程序 // Enqueuing parameters
// Note that we inform the size of the cl_mem object, not the size of the memory pointed by it
error = clSetKernelArg(run_as_gpu, 0, sizeof(cl_mem), &nums1_d);
error |= clSetKernelArg(run_as_gpu, 1, sizeof(cl_mem), &nums2_d);
error |= clSetKernelArg(run_as_gpu, 2, sizeof(cl_mem), &sum_d);
OPENCL_CHECK_ERRORS(error) // Launching kernel
size_t global_work_size = size;
cout << "GPU 运行开始:" << time_stamp() << endl;
error = clEnqueueNDRangeKernel(queue, run_as_gpu, 1, NULL, &global_work_size, NULL, 0, NULL, NULL);
cout << "GPU 运行结束:" << time_stamp() << endl;
OPENCL_CHECK_ERRORS(error) //取得kernel返回值
float* gpu_sum = new float[size];
clEnqueueReadBuffer(queue, sum_d, CL_TRUE, 0, mem_size, gpu_sum, 0, NULL, NULL); cout << "CPU 运行开始:" << time_stamp() << endl;
RunAsCpu(nums1_h, nums2_h, sum_h, size);
cout << "CPU 运行结束:" << time_stamp() << endl; assert(memcmp(sum_h, gpu_sum, size * sizeof(float)) == 0); delete[] nums1_h;
delete[] nums2_h;
delete[] sum_h;
delete[] gpu_sum;
delete[] platforms;
clReleaseKernel(run_as_gpu);
clReleaseCommandQueue(queue);
clReleaseContext(context);
clReleaseMemObject(nums1_d);
clReleaseMemObject(nums2_d);
clReleaseMemObject(sum_d);
return 0;
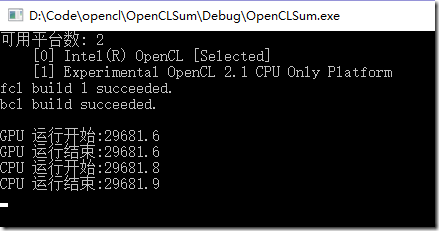
四、运行结果
由于运算比较简单,CPU和GPU几乎没差别,在后续复杂运算中应该是会有差别的。
五、相关下载
六、后续
看了几篇文章后似乎简单使用OpenCL还是不复杂的,OpenCL关键应该在于如何优化性能,如何调用kernel函数,可以将GPU效果最优化。以后的文章一部分涉及OpenCL原理,一部分涉及到更复杂的运算,当然了,博主也是学习阶段,没有练手项目,只能从官方demos中找找了。
OpenCL入门:(二:用GPU计算两个数组和)的更多相关文章
- CUDA学习(三)之使用GPU进行两个数组相加
传入两个数组,在GPU中将两个数组对应索引位置相加 #include "cuda_runtime.h" #include "device_launch_parameter ...
- JS - 计算两个数组的交集、差集、并集、补集(多种实现方式)
方法一:最普遍的做法 使用 ES5 语法来实现虽然会麻烦些,但兼容性最好,不用考虑浏览器 JavaScript 版本.也不用引入其他第三方库. 1,直接使用 filter.concat 来计算 var ...
- vue入门(二)----模板与计算属性
其实这部分内容我也是参考的官网:http://cn.vuejs.org/v2/guide/syntax.html,但是我还是想把自己不懂的知识记录一下,加深印象,也可以帮助自己以后查阅.所谓勤能补拙. ...
- ES6入门(二)
目录 ES6入门(二) es6之解构赋值 数组的解构赋值 对象的解构赋值 字符串的解构赋值 数值和布尔值的解构赋值 函数参数的解构赋值 圆括号问题 ES6入门(二) es6之解构赋值 数组的解构赋值 ...
- php获取两个数组相同的元素(交集)以及比较两个数组中不同的元素(差集)
(一)php获取两个数组相同元素 array array_intersect(array $array1, array $array2, [, array $...]) array array_ ...
- php判断两个数组是否相等
php判断两个数组是否相等 一.总结 一句话总结: php判断两个数组是否相等可以直接上==或者===号 二.php 判断两个数组是否相等 转自或参考:php 判断两个数组是否相等https://ww ...
- 函数bsxfun,两个数组间元素逐个计算的二值操作
转自http://www.cnblogs.com/rong86/p/3559616.html 函数功能:两个数组间元素逐个计算的二值操作 使用方法:C=bsxfun(fun,A,B) 两个数组A合B间 ...
- OpenCL入门:(一:Intel核心显卡OpenCL环境搭建)
组装的电脑没带独立显卡,用的是CPU自带的核显,型号是Intel HD Graphics 530,关于显卡是否可以使用OpenCL,可以下载GPU-Z软件查看. 本文在Windows 10 64位系统 ...
- GPU计算的十大质疑—GPU计算再思考
http://blog.csdn.NET/babyfacer/article/details/6902985 原文链接:http://www.hpcwire.com/hpcwire/2011-06-0 ...
随机推荐
- C#网络Socket编程
1.什么是Socket Sockets 是一种进程通信机制,是一个通信链的句柄(其实就是两个程序通信用的) 2.分类 流式套接字(SOCK_STREAM):提供了一种可靠的.面向连接的双向数据传输服务 ...
- Gradle Goodness: Run a Build Script With a Different Name
Normally Gradle looks for a build script file with the name build.gradle in the current directory to ...
- iOS学小程序从0到发布(适合iOS开发看)
Emmmm,最近一波失业潮.富某康.某团.摩某.京某.知某.某浪.58 某大面积裁员,那么在这个千钧一发之际,单纯iOS开发也着实不好过,回过头看一下,裁掉的都是单一选手,为了节约成本公司留下的都是身 ...
- iOS之在本地搭建IPv6环境测试你的app
IPv6的简介 IPv4 和 IPv6的区别就是 IP 地址前者是 .(dot)分割,后者是以 :(冒号)分割的(更多详细信息自行搜索). PS:在使用 IPv6 的热点时候,记得手机开 飞行模式 哦 ...
- 一个百度MAP导航的基础封装
项目中需要根据点击时候点击的内容,输入百度地图查找并展示规划等相关功能 于是封装了一个单独的百度map的html页面以供调用 功能包括了 ①展示底图 ②切换卫星图,切换卫星路线图,切换普通地图 ③通过 ...
- Java中的引用:强引用、软引用、弱引用、幻象引用(虚引用)
Java语言中,除了原始数据类型的变量(八大基本数据类型),其他都是引用类型,指向各种不同的对象. 理解引用对于我们掌握Java对象生命周期和JVM内部相关机制都是有帮助的. 不同的应用类型,不同之处 ...
- leyer不写content参数直接传递给子页面数据
function btnAddClickownfund(){ //获取数据 var actual = $("#actual_capitals").html().trim(); // ...
- php无限极分类处理
/** * 无限极分类处理(通过递归方式实现) * @param $section 原始数据Array * @param $html 界面显示前缀,比如 |- * @param $spear 分级中所 ...
- 怎样在Win7系统中搭建Web服务器
一.搭建web服务 1.打开控制面板,选择并进入“程序”,双击“打开或关闭Windows服务”,在弹出的窗口中选择“Internet信息服务”下面所有的选项,点击确定后,开始更新服务. 2.更新完成后 ...
- 【Linux】Linux文件跟目录管理
熟悉Linux的大家都知道,在Linux中,一切皆文件,可能在有些人的理解中,Linux跟我们的Windows差不多,是都具有图形操作界面的一种操作系统,但是更深入的来说,Linux更偏向于用命令操作 ...