【原创】大数据基础之Flink(1)简介、安装、使用
Flink 1.7

官方:https://flink.apache.org/
一 简介

Apache Flink is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
Flink是一个开源的分布式流式和批处理平台;Flink核心是流式数据流引擎,然后在流式引擎的基础上实现批处理。和spark正好相反,spark核心是批处理引擎,然后在批处理引擎的基础上实现流式处理;
1 集群部署结构视图
理解flink中的集群级别概念:master-slave,即JobManager-TaskManager(task slot)
master-worker结构-1
master-worker结构-2
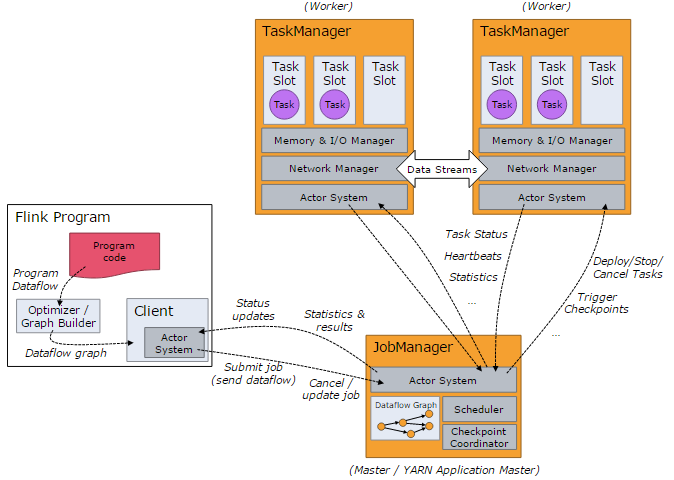
角色
1 JobManager -- 即master
The JobManagers (also called masters) coordinate the distributed execution. They schedule tasks, coordinate checkpoints, coordinate recovery on failures, etc.
There is always at least one Job Manager. A high-availability setup will have multiple JobManagers, one of which one is always the leader, and the others are standby.
JobManager,负责协调分布式执行,包括调度任务、协调检查点、协调错误恢复等;至少需要一个JobManager,如果有多个(ha),只能有一个是leader,其他是standby;
2 TaskManager -- 即worker
The TaskManagers (also called workers) execute the tasks (or more specifically, the subtasks) of a dataflow, and buffer and exchange the data streams.
There must always be at least one TaskManager.
TaskManager,负责具体执行数据流中的任务;至少需要一个TaskManager;
2.1 Task Slot
Each worker (TaskManager) is a JVM process, and may execute one or more subtasks in separate threads. To control how many tasks a worker accepts, a worker has so called task slots (at least one).
Each task slot represents a fixed subset of resources of the TaskManager. A TaskManager with three slots, for example, will dedicate 1/3 of its managed memory to each slot. Slotting the resources means that a subtask will not compete with subtasks from other jobs for managed memory, but instead has a certain amount of reserved managed memory. Note that no CPU isolation happens here; currently slots only separate the managed memory of tasks.
每个worker(TaskManager)都是一个JVM进程,每个worker划分为多个task slot,一个task slot表示worker中的一部分独立资源(即内存),这样在不同task slot中的子任务之间就没有内存竞争;
3 client
The client is not part of the runtime and program execution, but is used to prepare and send a dataflow to the JobManager. After that, the client can disconnect, or stay connected to receive progress reports. The client runs either as part of the Java/Scala program that triggers the execution, or in the command line process ./bin/flink run ....
client负责提交数据流到JobManager,提交完成之后,client就可以断开;client通常这样启动 ./bin/flink run ....
2 Hello World应用-词频统计
下面通过代码和图示来理解flink中的几个应用级别概念:dataflow、task、operator(subtask)、stream(partition)、task slot
批处理代码
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]) {
val env = ExecutionEnvironment.getExecutionEnvironment
val text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?")
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
counts.print()
}
}
流式代码
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time object WindowWordCount {
def main(args: Array[String]) { val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("localhost", 9999) val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1) counts.print() env.execute("Window Stream WordCount")
}
}
图示执行过程-1
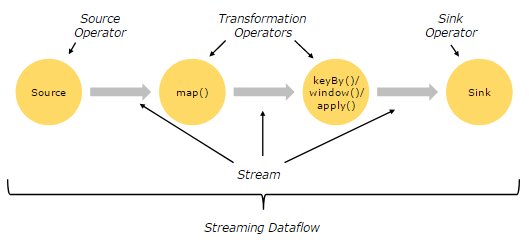
解释:应用代码实际上描述了一个dataflow,一个dataflow由多个operator组成:Source Operator、Transformation Operator、Sink Operator,operator之间形成stream;
图示执行过程-2
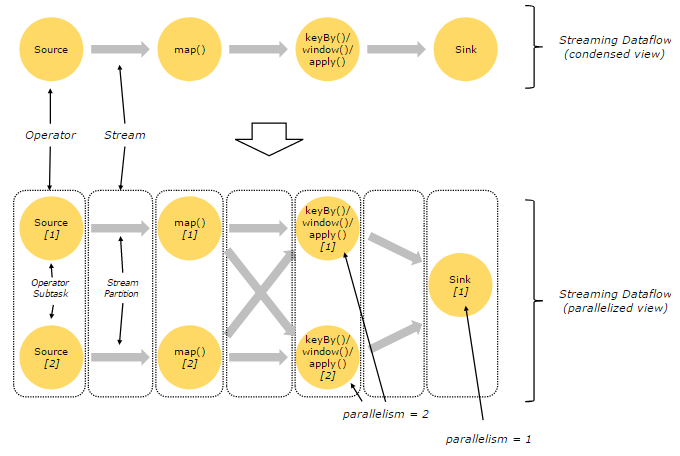
解释:每个operator可以拆分为多个subtask执行,这样operator之后的stream也形成多个partition;另外有些operator之间需要shuffle;
Programs in Flink are inherently parallel and distributed. During execution, a stream has one or more stream partitions, and each operator has one or more operator subtasks. The operator subtasks are independent of one another, and execute in different threads and possibly on different machines or containers.
The number of operator subtasks is the parallelism of that particular operator. The parallelism of a stream is always that of its producing operator. Different operators of the same program may have different levels of parallelism.
flink执行过程中,一个stream有一个或多个partition,每个operator都有一个或多个subtask,一个operator下的subtask之间彼此独立(在不同的线程中执行并且尽可能的在不同的机器或者容器中执行);
Streams can transport data between two operators in a one-to-one (or forwarding) pattern, or in a redistributing pattern:
- One-to-one streams (for example between the Source and the map() operators in the figure above) preserve the partitioning and ordering of the elements. That means that subtask[1] of the map() operator will see the same elements in the same order as they were produced by subtask[1] of the Source operator.
- Redistributing streams (as between map() and keyBy/window above, as well as between keyBy/window and Sink) change the partitioning of streams. Each operator subtask sends data to different target subtasks, depending on the selected transformation. Examples are keyBy() (which re-partitions by hashing the key), broadcast(), or rebalance() (which re-partitions randomly). In a redistributing exchange the ordering among the elements is only preserved within each pair of sending and receiving subtasks (for example, subtask[1] of map() and subtask[2] of keyBy/window). So in this example, the ordering within each key is preserved, but the parallelism does introduce non-determinism regarding the order in which the aggregated results for different keys arrive at the sink.
operator分为两种,一种是一对一(one-to-one或者forwarding),一种是重新分布(redistributing,即shuffle);
flink中forwarding operator类似于spark中trasformation的map,redistributing operator类似于spark中transformation的reduceByKey(需要shuffle),sink operator类似于spark中的action;
图示执行过程-3
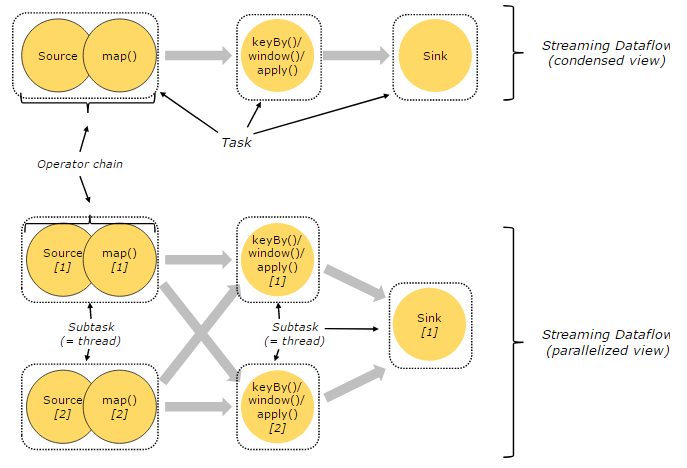
解释:多个operator可以chain(链接)起来形成一个task;
For distributed execution, Flink chains operator subtasks together into tasks. Each task is executed by one thread. Chaining operators together into tasks is a useful optimization: it reduces the overhead of thread-to-thread handover and buffering, and increases overall throughput while decreasing latency.
将operation链接起来组成task是一个非常有用的优化:减少了线程间的数据交换、增加吞吐量同时减少延迟;
图示执行过程-4
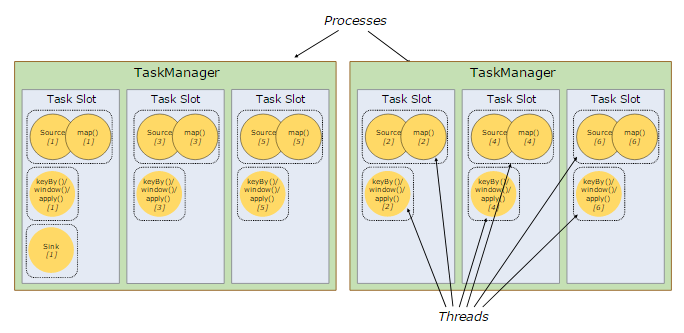
解释:一个task的subtask会被分配到不同的task slot执行,不同task的subtask可以共享一个task slot;
By default, Flink allows subtasks to share slots even if they are subtasks of different tasks, so long as they are from the same job. The result is that one slot may hold an entire pipeline of the job. Allowing this slot sharing has two main benefits:
A Flink cluster needs exactly as many task slots as the highest parallelism used in the job. No need to calculate how many tasks (with varying parallelism) a program contains in total.
It is easier to get better resource utilization. Without slot sharing, the non-intensive source/map() subtasks would block as many resources as the resource intensive window subtasks. With slot sharing, increasing the base parallelism in our example from two to six yields full utilization of the slotted resources, while making sure that the heavy subtasks are fairly distributed among the TaskManagers.
flink默认允许一个job下不同task的subtask可以共享一个task slot;共享task slot有两个好处:1)task slot数量表示一个job的最高并发数;2)合理利用资源;
As a rule-of-thumb, a good default number of task slots would be the number of CPU cores. With hyper-threading, each slot then takes 2 or more hardware thread contexts.
通常task slot数量设置为cpu的核数;
3 API
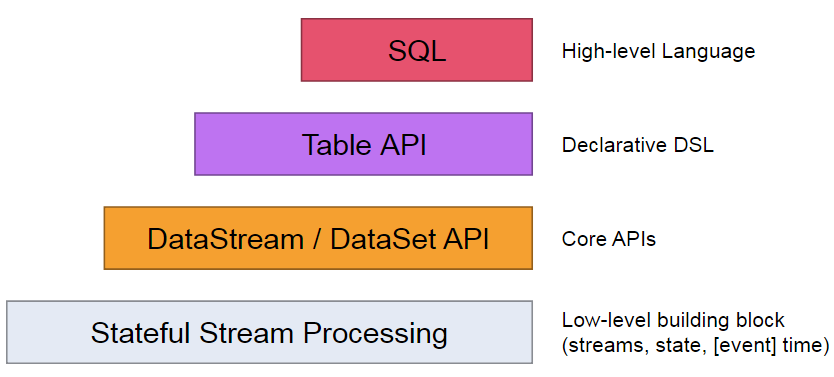
四层抽象(API)说明:
- The lowest level abstraction simply offers stateful streaming. It is embedded into the DataStream API via the Process Function. It allows users freely process events from one or more streams, and use consistent fault tolerant state. In addition, users can register event time and processing time callbacks, allowing programs to realize sophisticated computations.
- In practice, most applications would not need the above described low level abstraction, but would instead program against the Core APIs like the DataStream API (bounded/unbounded streams) and the DataSet API (bounded data sets). These fluent APIs offer the common building blocks for data processing, like various forms of user-specified transformations, joins, aggregations, windows, state, etc. Data types processed in these APIs are represented as classes in the respective programming languages.
- The Table API is a declarative DSL centered around tables, which may be dynamically changing tables (when representing streams). The Table API follows the (extended) relational model: Tables have a schema attached (similar to tables in relational databases) and the API offers comparable operations, such as select, project, join, group-by, aggregate, etc. Table API programs declaratively define what logical operation should be done rather than specifying exactly how the code for the operation looks. Though the Table API is extensible by various types of user-defined functions, it is less expressive than the Core APIs, but more concise to use (less code to write). In addition, Table API programs also go through an optimizer that applies optimization rules before execution.
- The highest level abstraction offered by Flink is SQL. This abstraction is similar to the Table API both in semantics and expressiveness, but represents programs as SQL query expressions. The SQL abstraction closely interacts with the Table API, and SQL queries can be executed over tables defined in the Table API.
DataStream常用api:https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/stream/operators/index.html
DataSet常用api:https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/batch/index.html#dataset-transformations
类似于spark中的transformation算子
参考:
https://ci.apache.org/projects/flink/flink-docs-release-1.7/concepts/programming-model.html
https://ci.apache.org/projects/flink/flink-docs-release-1.7/concepts/runtime.html
二 安装
下载
# wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.7.1/flink-1.7.1-bin-hadoop28-scala_2.11.tgz
# tar xvf flink-1.7.1-bin-hadoop28-scala_2.11.tgz
# cd flink-1.7.1
集群环境ssh免登陆(单机请跳过)
详见:https://www.cnblogs.com/barneywill/p/10271679.html
启动
1 单机standalone方式启动
启动
# bin/start-cluster.sh
详见:https://ci.apache.org/projects/flink/flink-docs-release-1.7/tutorials/local_setup.html
2 单master多worker方式启动
配置
# cat conf/flink-conf.yaml
jobmanager.rpc.address: $master_server
jobmanager.rpc.port: 6123
同步flink-conf.yaml到所有节点
# cat conf/slaves
$slave1
$slave2
$slave3
启动
# bin/start-cluster.sh
详见:https://ci.apache.org/projects/flink/flink-docs-release-1.7/ops/deployment/cluster_setup.html
3 ha方式启动(多master多worker)
配置
# cat conf/flink-conf.yaml
#jobmanager.rpc.address: $master_server
#jobmanager.rpc.port: 6123high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha/
high-availability.zookeeper.quorum: $zk_server1:2181rest.port: 8081
同步flink-conf.yaml到所有节点
主要修改为:打开high-availability相关配置,同时将jobmanager.rpc.address和jobmanager.rpc.port注释掉,官方解释如下:
The config parameter defining the network address to connect to for communication with the job manager. This value is only interpreted in setups where a single JobManager with static name or address exists (simple standalone setups, or container setups with dynamic service name resolution). It is not used in many high-availability setups, when a leader-election service (like ZooKeeper) is used to elect and discover the JobManager leader from potentially multiple standby JobManagers.
# cat conf/masters
$master1:8081
$master2:8081
# cat conf/slaves
$slave1
$slave2
$slave3
启动
# bin/start-cluster.sh
另外也可以逐个启动
# bin/jobmanager.sh start
# bin/taskmanager.sh start
4 其他(Yarn、Mesos等)
在yarn上启动flink集群
./bin/yarn-session.sh -n 4 -jm 1024m -tm 4096m
访问 http://$master1:8081
三 使用
提交任务
$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
提交任务到yarn
./bin/flink run -m yarn-cluster -yn 4 -yjm 1024m -ytm 4096m ./examples/batch/WordCount.jar
【原创】大数据基础之Flink(1)简介、安装、使用的更多相关文章
- 大数据基础环境--jdk1.8环境安装部署
1.环境说明 1.1.机器配置说明 本次集群环境为三台linux系统机器,具体信息如下: 主机名称 IP地址 操作系统 hadoop1 10.0.0.20 CentOS Linux release 7 ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
随机推荐
- 使用Roslyn脚本化C#代码,C#动态脚本实现方案
[前言] Roslyn 是微软公司开源的 .NET 编译器. 编译器支持 C# 和 Visual Basic 代码编译,并提供丰富的代码分析 API. Roslyn不仅仅可以直接编译输出,难能可贵的就 ...
- docker 小技巧 docker network create br-name 指定IP地址
在某些情况下,使用 docker network create br-name 命令创建网络的时候,会创建一个新的网桥,该网桥的默认IP地址为172.18.0.0\16(或相临的IP地址段) 这个ip ...
- H5 基于Web Storage 的客户端留言板
<!DOCTYPE html> <html> <head> <meta name="author" content="Yeeku ...
- 论PHP框架设计模式及MVC的缺陷
目前主流的PHP框架设计模式均为MVC模式,比如yii或codeigniter,均是由控制器接收页面请求,并沟通模型与视图的交互.如果我们把网站整体看作一个矩阵,把网站接收用户请求并处理看作是网站的竖 ...
- css清除默认样式,stylus学习
reset.css html, body, div, span, applet, object, iframe, h1, h2, h3, h4, h5, h6, p, blockquote, pre, ...
- rxjs一句话描述一个操作符(1)
之前一直在写LINQ之类的东西,对于函数式的面向对象还是有一些功底,所以对于rxjs,感觉上不是很难,但是每次看完过几天就忘,还是记一下笔记吧,好记性不如烂笔头真不是盖的. 首先介绍几个重要的概念. ...
- centos django Failed to load resource: net::ERR_INCOMPLETE_CHUNKED_ENCODING
os环境 centos python2.7.5 django1.10.8 class AdminAutoRunTask(View): """ 自动跑外放任务 " ...
- 4月11日java多线程4
继昨天学习了线程池之后,今天学习了多线程内的锁Lock. 定义方法: ReentrantLock queueLock = new ReentrantLock(); //可重入锁 ReentrantRe ...
- tomcat配置详解
Tomcat Server的结构图如下: 该文件描述了如何启动Tomcat Server <Server> <Listener /> <GlobaNaming ...
- BSGS算法
BSGS算法 我是看着\(ppl\)的博客学的,您可以先访问\(ppl\)的博客 Part1 BSGS算法 求解关于\(x\)的方程 \[y^x=z(mod\ p)\] 其中\((y,p)=1\) 做 ...