MapReduce编程之Map Join多种应用场景与使用
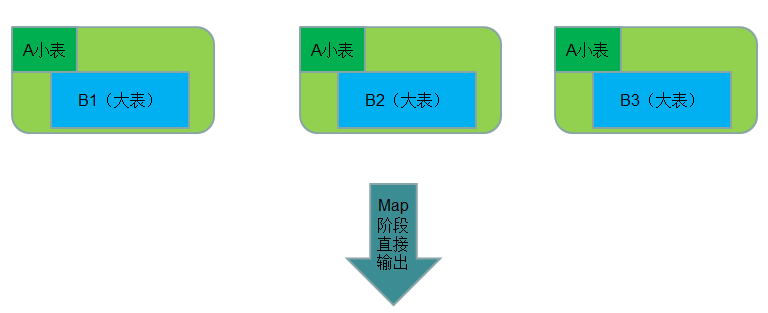
Map Join 实现方式一:分布式缓存
● 使用场景:一张表十分小、一张表很大。
● 用法:
在提交作业的时候先将小表文件放到该作业的DistributedCache中,然后从DistributeCache中取出该小表进行join (比如放到Hash Map等等容器中)。然后扫描大表,看大表中的每条记录的join key /value值是否能够在内存中找到相同join key的记录,如果有则直接输出结果。
DistributedCache是分布式缓存的一种实现,它在整个MapReduce框架中起着相当重要的作用,他可以支撑我们写一些相当复杂高效的分布式程序。说回到这里,JobTracker在作业启动之前会获取到DistributedCache的资源uri列表,并将对应的文件分发到各个涉及到该作业的任务的TaskTracker上。另外,关于DistributedCache和作业的关系,比如权限、存储路径区分、public和private等属性。
代码实现
package com.hadoop.reducejoin.test; import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Hashtable; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; /*
* 通过分布式缓存实现 map join
* 适用场景:一个小表,一个大表
*/
public class MapJoinByDistributedCache extends Configured implements Tool { /*
* 直接在map 端进行join合并
*/
public static class MapJoinMapper extends
Mapper<LongWritable, Text, Text, Text> {
private Hashtable<String, String> table = new Hashtable<String, String>();// 定义Hashtable存放缓存数据 /**
* 获取分布式缓存文件
*/
@SuppressWarnings("deprecation")
protected void setup(Context context) throws IOException,
InterruptedException {
Path[] localPaths = (Path[]) context.getLocalCacheFiles();// 返回本地文件路径
if (localPaths.length == 0) {
throw new FileNotFoundException(
"Distributed cache file not found.");
}
FileSystem fs = FileSystem.getLocal(context.getConfiguration());// 获取本地
// FileSystem
// 实例
FSDataInputStream in = null; in = fs.open(new Path(localPaths[0].toString()));// 打开输入流
BufferedReader br = new BufferedReader(new InputStreamReader(in));// 创建BufferedReader读取器
String infoAddr = null;
while (null != (infoAddr = br.readLine())) {// 按行读取并解析气象站数据
String[] records = infoAddr.split("\t");
table.put(records[0], records[1]);// key为stationID,value为stationName
}
} public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] valueItems = line.split("\\s+");
// 使用下面一行将没有数据, StringUtils不能接正则,只能接分隔符
// String[] valueItems = StringUtils.split(value.toString(), "\\s+");
String stationName = table.get(valueItems[0]);// 天气记录根据stationId
// 获取stationName
if (null != stationName)
context.write(new Text(stationName), value);
} } public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration(); Path out = new Path(args[2]);
FileSystem hdfs = out.getFileSystem(conf);// 创建输出路径
if (hdfs.isDirectory(out)) {
hdfs.delete(out, true);
}
Job job = Job.getInstance();// 获取一个job实例
job.setJarByClass(MapJoinByDistributedCache.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
// 添加分布式缓存文件 station.txt
job.addCacheFile(new URI(args[1]));
job.setMapperClass(MapJoinMapper.class); job.setOutputKeyClass(Text.class);// 输出key类型
job.setOutputValueClass(Text.class);// 输出value类型
return job.waitForCompletion(true) ? 0 : 1;
} public static void main(String[] args0) throws Exception {
String[] args = { "hdfs://sparks:9000/middle/reduceJoin/records.txt",
"hdfs://sparks:9000/middle/reduceJoin/station.txt",
"hdfs://sparks:9000/middle/reduceJoin/MapJoinByDistributedCache-out" }; int ec = ToolRunner.run(new Configuration(),
new MapJoinByDistributedCache(), args);
System.exit(ec);
}
}
MapJoinByDistributedCache
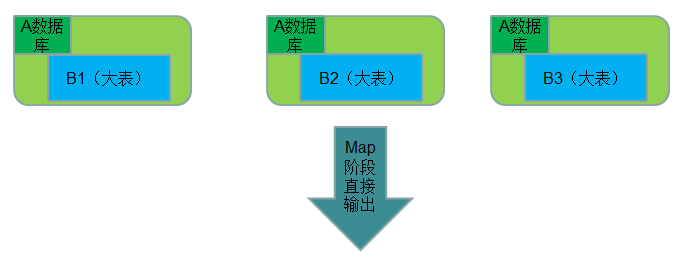
Map Join 实现方式二:数据库 join
● 使用场景:一张表在数据库、一张表很大。
另外还有一种比较变态的Map Join方式,就是结合HBase来做Map Join操作。这种方式完全可以突破内存的控制,使你毫无忌惮的使用Map Join,而且效率也非常不错。
MapReduce编程之Map Join多种应用场景与使用的更多相关文章
- MapReduce编程之Semi Join多种应用场景与使用
Map Join 实现方式一 ● 使用场景:一个大表(整张表内存放不下,但表中的key内存放得下),一个超大表 ● 实现方式:分布式缓存 ● 用法: SemiJoin就是所谓的半连接,其实仔细一看就是 ...
- MapReduce编程之Reduce Join多种应用场景与使用
在关系型数据库中 Join 是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求, 例如在数据分析时需要连接从不同的数据源中获取到数据.不同于传统的单机模式 ...
- MapReduce编程之wordcount
实践 MapReduce编程之wordcount import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Fi ...
- Swift函数编程之Map、Filter、Reduce
在Swift语言中使用Map.Filter.Reduce对Array.Dictionary等集合类型(collection type)进行操作可能对一部分人来说还不是那么的习惯.对于没有接触过函数式编 ...
- Python函数式编程之map()
Python函数式编程之map() Python中map().filter().reduce()这三个都是应用于序列的内置函数. 格式: map(func, seq1[, seq2,…]) 第一个参数 ...
- mapReduce编程之Recommender System
1 协同过滤算法 协同过滤算法是现在推荐系统的一种常用算法.分为user-CF和item-CF. 本文的电影推荐系统使用的是item-CF,主要是由于用户数远远大于电影数,构建矩阵的代价更小:另外,电 ...
- mapReduce编程之auto complete
1 n-gram模型与auto complete n-gram模型是假设文本中一个词出现的概率只与它前面的N-1个词相关.auto complete的原理就是,根据用户输入的词,将后续出现概率较大的词 ...
- mapReduce编程之google pageRank
1 pagerank算法介绍 1.1 pagerank的假设 数量假设:每个网页都会给它的链接网页投票,假设这个网页有n个链接,则该网页给每个链接平分投1/n票. 质量假设:一个网页的pagerank ...
- 并发编程之Fork/Join
并发与并行 并发:多个进程交替执行. 并行:多个进程同时进行,不存在线程的上下文切换. 并发与并行的目的都是使CPU的利用率达到最大.Fork/Join就是为了尽可能提高硬件的使用率而应运而生的. 计 ...
随机推荐
- 【LG3722】[HNOI2017]影魔
[LG3722][HNOI2017]影魔 题面 洛谷 题解 先使用单调栈求出\(i\)左边第一个比\(i\)大的位置\(lp_i\),和右边第一个比\(i\)大的位置\(rp_i\). 考虑\(i\) ...
- Oracle Database Link 连接数据库复制数据
--1. 创建dblink连接 create database link mdm66 connect to lc019999 identified by aaaaaa using '10.24.12. ...
- AJAX其实就是一个异步网络请求
AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML).其实就是一个异步网络请求. 一.创建对象 var xmlhttp; if (w ...
- unittest—selenium自动化登录百度绕过校验
这个脚本融合了unittest的校验,以及selenium的自动化,并且通过派发cookie信息成功绕过百度的验证码,并且利用装饰器成功只打开一次浏览器 #encoding=utf-8 from se ...
- ThreadPoolExecutor 使用说明
它是一个ExecutorService,使用线程池中的线程执行提交的任务.通常我们使用Executors框架,定义使用. 线程池主要用来解决两类问题:通过缓存一定数量的可用线程,避免频繁的线程创建,销 ...
- RabbitMQ入门:发布/订阅(Publish/Subscribe)
在前面的两篇博客中 RabbitMQ入门:Hello RabbitMQ 代码实例 RabbitMQ入门:工作队列(Work Queue) 遇到的实例都是一个消息只发送给一个消费者(工作者),他们的消息 ...
- 打包一个传统的ASP.NET web app作为Docker镜像
(1)针对NerdDinner应用的Dockerfile内容如下 PS E:\DockeronWindows\Chapter02\ch02-nerd-dinner> cat .\Dockerfi ...
- PytorchZerotoAll学习笔记(一)
Pytorch的安装请参考torch的官方文档,传送门:https://pytorch.org/get-started/locally/ Numpy的复习 如果你之前没有学过Numpy的话,建议去看看 ...
- MySQL基础(一)
首先需要安装MySOL,这里我是在windows环境下安装的,具体教程可以参考https://www.cnblogs.com/xsmile/p/7753984.html,不过要注意安装过程可能会不太顺 ...
- 亚马逊如何变成 SOA(面向服务的架构)
. 亚马逊公司不仅是世界最大的网络书店,还是世界最大的云服务商.它是怎么实现从电商到云商的转变呢? 一切都是CEO杰夫·贝索斯促成的,他对市场有着超乎常人的理解和预见. 2. 2000年前后,贝索斯有 ...