深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
在tf第一个例子的时候需要很多预备知识。
tf基本知识
香农熵
交叉熵代价函数cross-entropy
卷积神经网络
softmax
这里用到的tf基本知识
- tf.tensor-张量,其实就是矩阵。官方说法是原料
- tf.Varible-变量,用来记录数据,参数。其实也是个矩阵。不过要初始化后才有具体的值
- tf.Session()-会话,就是个模型,我们可以在里面添加数据流动方向,运算节点
香农熵
香农熵是计算信息复杂度的公式。
公式如下

要理解这个公式不难。举例是最好的方法。首先是硬币,正面概率1/2反面1/2
那么H(x)=-(1/2log(1/2)+1/2log(1/2))=1
假如有在某种情况下有4种可能就是
H(x)=-(1/4log(1/4)+1/4log(1/4)+1/4log(1/4)+1/4log(1/4))=2
可以明显看出,问题的分类越多,结果越多,那么复杂度越高。不确定性越高,比如我们在决策树中要做的就是每次都把信息熵最高的选出来然后递归决策
交叉熵代价函数cross-entropy
这是个更优化的损失函数比起常规的cost function.
机器学习中第一个遇见的是sigmod函数,这个函数在开始时梯度小,学习速率慢。我们看下图就知道
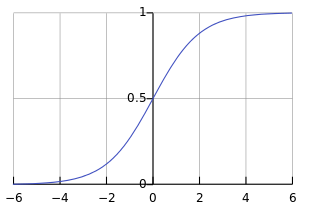
CROSS-ENTROPY解决了初时时学习速率过小的问题
cross-entropy和香农熵的公式有点像,但是千万不要搞混。
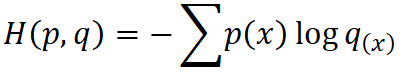
这里的p是样本的真实分布
q是带估计的模型,也就是我们的预测。
同样举例是最好理解公式的方法。
(1)我们假设硬币抛100次正面1/3反面2/3.我们预测是1/2 1/2
然后h(x)=-(1/3*-1+2/3*-1)=1
我们再假设硬币抛100次是正面1/3反2/3 我们预测是正0.001 反0.999
h(x)=-(1/3*负无穷+2/3*0)=正无穷
(2)再假设某种概率都是1/4我们预测也都是1/4
h(x)=-(1/4*-2*4)=2
如果我们预测为1/8 1/4 1/8 1/2
h(x)=-(1/4*-3+1/4*-2+1/4*-3+1/4*-1)=2.25
对比两个例子可以发现,当预测越准时候,交叉熵越小,反之交叉熵越大,(1)中可以看到对于离谱的预测,交叉熵也会变得非常之大
卷积神经网络-以下内容全部来自https://my.oschina.net/u/876354/blog/1620906 一篇超级好的blog
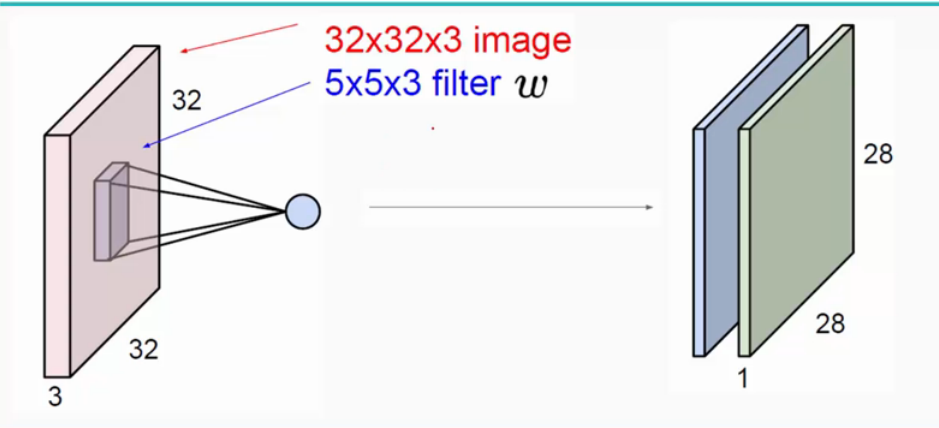
如图卷积层就是图中的filter-它的作用是提取特征值-参考卷积公式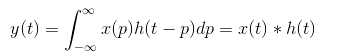 可以知道就是对图像的遍历操作
可以知道就是对图像的遍历操作
这里的卷积层是5*5*3(3是深度这里也就是rgb)所以-一次卷积后得到28*28*3 两次后是24*24*3

发现一遍超级好文:放下地址
https://my.oschina.net/u/876354/blog/1620906 超级详细的cnn解释
池化层
作用:将图片缩小,减少像素保留特征值,以便后来加快计算。我这里COPY了上面BLOG的部分内容。万一那个BLOG炸了我还有备份
(5)池化(Pooling)
为了有效地减少计算量,CNN使用的另一个有效的工具被称为“池化(Pooling)”。池化就是将输入图像进行缩小,减少像素信息,只保留重要信息。
池化的操作也很简单,通常情况下,池化区域是2*2大小,然后按一定规则转换成相应的值,例如取这个池化区域内的最大值(max-pooling)、平均值(mean-pooling)等,以这个值作为结果的像素值。
下图显示了左上角2*2池化区域的max-pooling结果,取该区域的最大值max(0.77,-0.11,-0.11,1.00),作为池化后的结果,如下图: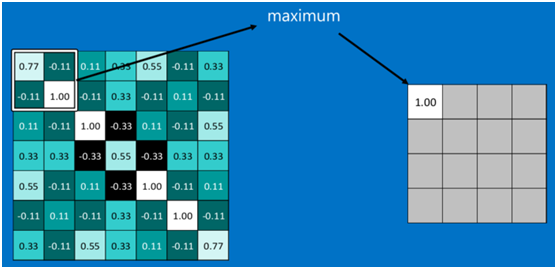
池化区域往左,第二小块取大值max(0.11,0.33,-0.11,0.33),作为池化后的结果,如下图: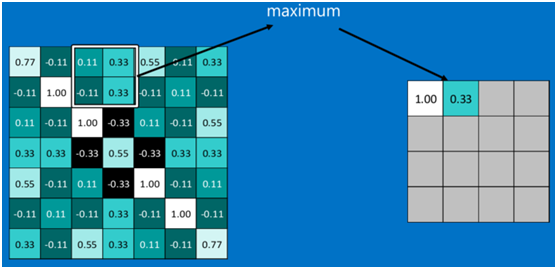
其它区域也是类似,取区域内的最大值作为池化后的结果,最后经过池化后,结果如下: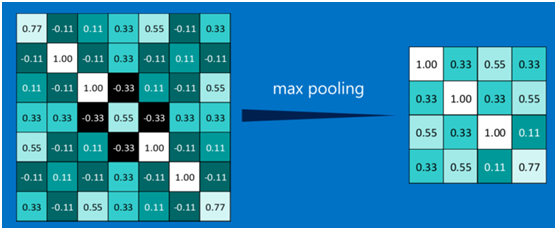
对所有的feature map执行同样的操作,结果如下:
最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。
通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。
softmax
这是个回归函数,不同于logistic回归解决的二分问题,sotfmax用于多类别问题。
算是激励函数
首先和sigmod一样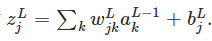
然后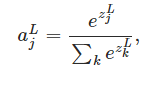
分母是把所有神经元的值加起来
分子是第L层第j个神经元的输出
就是某个神经元输出占所有神经元输出的比值
意义:当它占的比值越大,这个样本的损失越小

深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识的更多相关文章
- 深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版 这是tf入门的第一个例子.minst应该是内置的数据集. 前置知识在学习笔记(1)里面讲过了 这里直接上代码 # -*- ...
- 【OpenCV】opencv3.0中的SVM训练 mnist 手写字体识别
前言: SVM(支持向量机)一种训练分类器的学习方法 mnist 是一个手写字体图像数据库,训练样本有60000个,测试样本有10000个 LibSVM 一个常用的SVM框架 OpenCV3.0 中的 ...
- TensorFlow—多层感知器—MNIST手写数字识别
1 import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data import ...
- 第二节,mnist手写字体识别
1.获取mnist数据集,得到正确的数据格式 mnist = input_data.read_data_sets('MNIST_data',one_hot=True) 2.定义网络大小:图片的大小是2 ...
- mnist手写数字识别——深度学习入门项目(tensorflow+keras+Sequential模型)
前言 今天记录一下深度学习的另外一个入门项目——<mnist数据集手写数字识别>,这是一个入门必备的学习案例,主要使用了tensorflow下的keras网络结构的Sequential模型 ...
- 深度学习之 mnist 手写数字识别
深度学习之 mnist 手写数字识别 开始学习深度学习,先来一个手写数字的程序 import numpy as np import os import codecs import torch from ...
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 http://phunter.farbox.com/post/mxnet-tutorial1 用MXnet实战深度学 ...
- 深度学习---手写字体识别程序分析(python)
我想大部分程序员的第一个程序应该都是“hello world”,在深度学习领域,这个“hello world”程序就是手写字体识别程序. 这次我们详细的分析下手写字体识别程序,从而可以对深度学习建立一 ...
- Android+TensorFlow+CNN+MNIST 手写数字识别实现
Android+TensorFlow+CNN+MNIST 手写数字识别实现 SkySeraph 2018 Email:skyseraph00#163.com 更多精彩请直接访问SkySeraph个人站 ...
随机推荐
- Java并发编程--5.信号量和障碍器
Semaphore信号量 简介 它本质上是一个共享锁,限制访问公共资源的线程数目,它也被称为计数信号量acquire()许可一个线程, Semaphore – 1; 没有可用的许可时,Semaphor ...
- Day5 JavaScript(三)事件、表单验证以及初识jQuery
事件 1)鼠标事件 mousedown mouseup 2)键盘事件 a) keydown:键被按下 b) keyup:键抬起 c) keypress:按下可打印字符的键时. document.onk ...
- virtualbox+vagrant学习-2(command cli)-9-vagrant Plugin命令
Plugin 格式: vagrant plugin <command> [<args>] 这是用来管理插件的命令. 1)Plugin Expunge 格式: vagrant p ...
- Docker实战(五)之端口映射与容器互联
除了网络访问外,Docker还提供了两个很方便的功能来满足服务访问的基本需求:一个是允许映射容器内应用的服务端口到本地宿主主机;另一个是互联机制实现多个容器间通过容器名来快速访问. 1.端口映射实现访 ...
- gitblit server windows搭建
环境配置: windows64bit 系统 jdk1.8安装配置环境变量,这个不说了百度有 gitblit官网下载对应操作系统位数64bit包解压:http://www.gitblit.com/ ...
- ZooKeeper(二)Java API使用
ZooKeeper官网提供了Java和C的API. 本文使用Java API来实现ZooKeeper的基本操作. 前言 下图中的Replicated Database是包含完整数据树(entire d ...
- JavaScript小例子
1. alert.html <html> <head> <title></title> <script type="text/javas ...
- B. Our Tanya is Crying Out Loud
http://codeforces.com/problemset/problem/940/B Right now she actually isn't. But she will be, if you ...
- Hdu4952 - Number Transformation - 数论(2014 Multi-University Training Contest 8)
寻找1~k内i的倍数.则这个数能够看成i*x,则下一个数为(i+1)*y,(i+1)*y>=i*x,那么能够推出.y=x-x/(i+1); 那么当x<i+1时,y==x.之后的循环也不会改 ...
- 【SAPUI5】ODataとは
はじめに SAPUI5でアプリケーションを作るにあたり.ODataは避けては通れないトピックです.結構広いテーマなので.5-7回くらいに分けて書きたいと思います.1回目はODataの概要について説明し ...