重要 | Spark分区并行度决定机制
最近经常有小伙伴在本公众号留言,核心问题都比较类似,就是虽然接触Spark有一段时间了,但是搞不明白一个问题,为什么我从HDFS上加载不同的文件时,打印的分区数不一样,并且好像spark.default.parallelism这个参数时不是一直起作用?其实笔者之前的文章已有相关介绍,想知道为什么,就必须了解Spark在加载不同的数据源时分区决定机制以及调用不用算子时并行度决定机制以及分区划分。
其实之前的文章《Spark的分区》、《通过spark.default.parallelism谈Spark并行度》已有所介绍,笔者今天再做一次详细的补充,建议大家在对Spark有一定了解的基础上,三篇文章结合一起看。
大家都知道Spark job中最小执行单位为task,合理设置Spark job每个stage的task数是决定性能好坏的重要因素之一,但是Spark自己确定最佳并行度的能力有限,这就要求我们在了解其中内在机制的前提下,去各种测试、计算等来最终确定最佳参数配比。
Spark任务在执行时会将RDD划分为不同的stage,一个stage中task的数量跟最后一个RDD的分区数量相同。之前已经介绍过,stage划分的关键是宽依赖,而宽依赖往往伴随着shuffle操作。对于一个stage接收另一个stage的输入,这种操作通常都会有一个参数numPartitions来显示指定分区数。最典型的就是一些ByKey算子,比如groupByKey(numPartitions: Int),但是这个分区数需要多次测试来确定合适的值。首先确定父RDD中的分区数(通过rdd.partitions().size()可以确定RDD的分区数),然后在此基础上增加分区数,多次调试直至在确定的资源任务能够平稳、安全的运行。
对于没有父RDD的RDD,比如通过加载HDFS上的数据生成的RDD,它的分区数由InputFormat切分机制决定。通常就是一个HDFS block块对应一个分区,对于不可切分文件则一个文件对应一个分区。
对于通过SparkContext的parallelize方法或者makeRDD生成的RDD分区数可以直接在方法中指定,如果未指定,则参考spark.default.parallelism的参数配置。下面是默认情况下确定defaultParallelism的源码:
override def defaultParallelism(): Int = {
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
}
通常,RDD的分区数与其所依赖的RDD的分区数相同,除非shuffle。但有几个特殊的算子:
1. coalesce和repartition算子
笔者先放两张关于该coalesce算子分别在RDD和DataSet中的源码图:(DataSet是Spark SQL中的分布式数据集,后边说到Spark时再细讲)
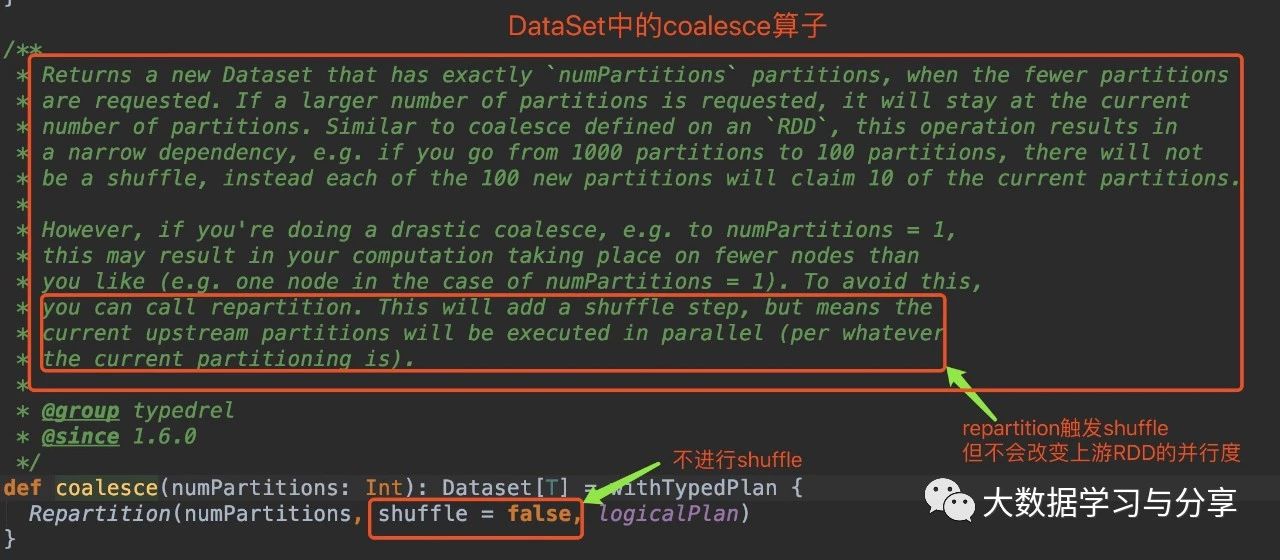
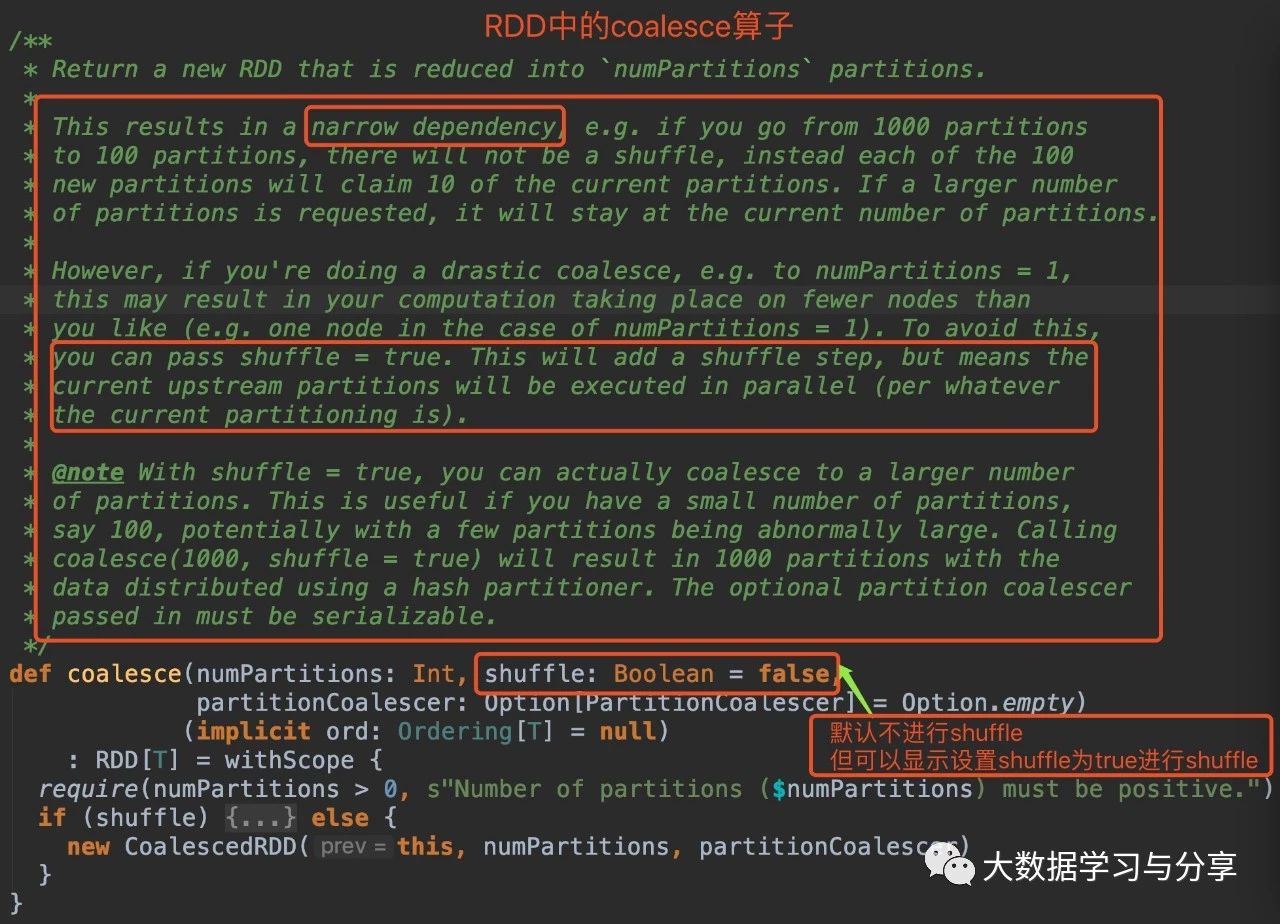
通过coalesce源码分析,无论是在RDD中还是DataSet,默认情况下coalesce不会产生shuffle,此时通过coalesce创建的RDD分区数小于等于父RDD的分区数。
笔者这里就不放repartition算子的源码了,分析起来也比较简单,图中我有所提示。但笔者建议,如下两种情况,请使用repartition算子:
1)增加分区数repartition触发shuffle,shuffle的情况下可以增加分区数。
coalesce默认不触发shuffle,即使调用该算子增加分区数,实际情况是分区数仍然是当前的分区数。
2)极端情况减少分区数,比如将分区数减少为1调整分区数为1,此时数据处理上游stage并行度降,很影响性能。此时repartition的优势即不改变原来stage的并行度就体现出来了,在大数据量下,更为明显。但需要注意,因为repartition会触发shuffle,而要衡量好shuffle产生的代价和因为用repartition增加并行度带来的效益。
2. union算子
还是直接看源码:
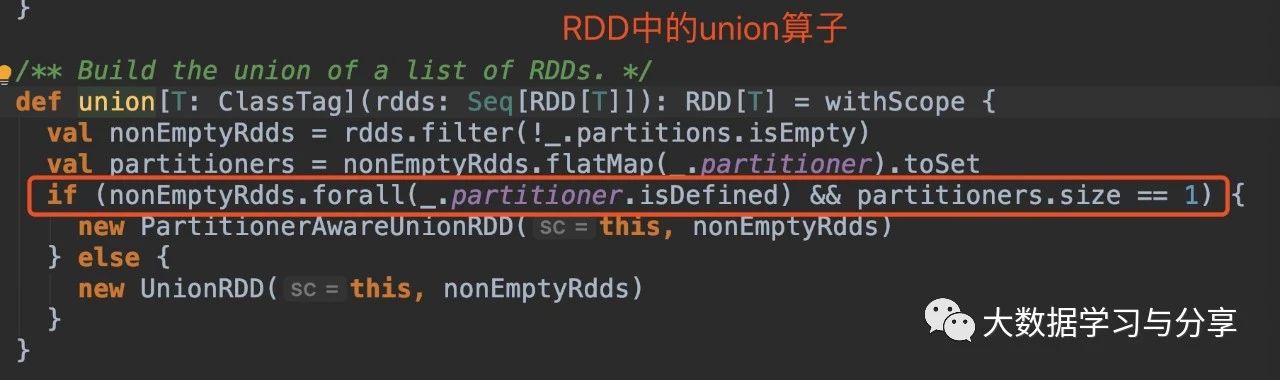

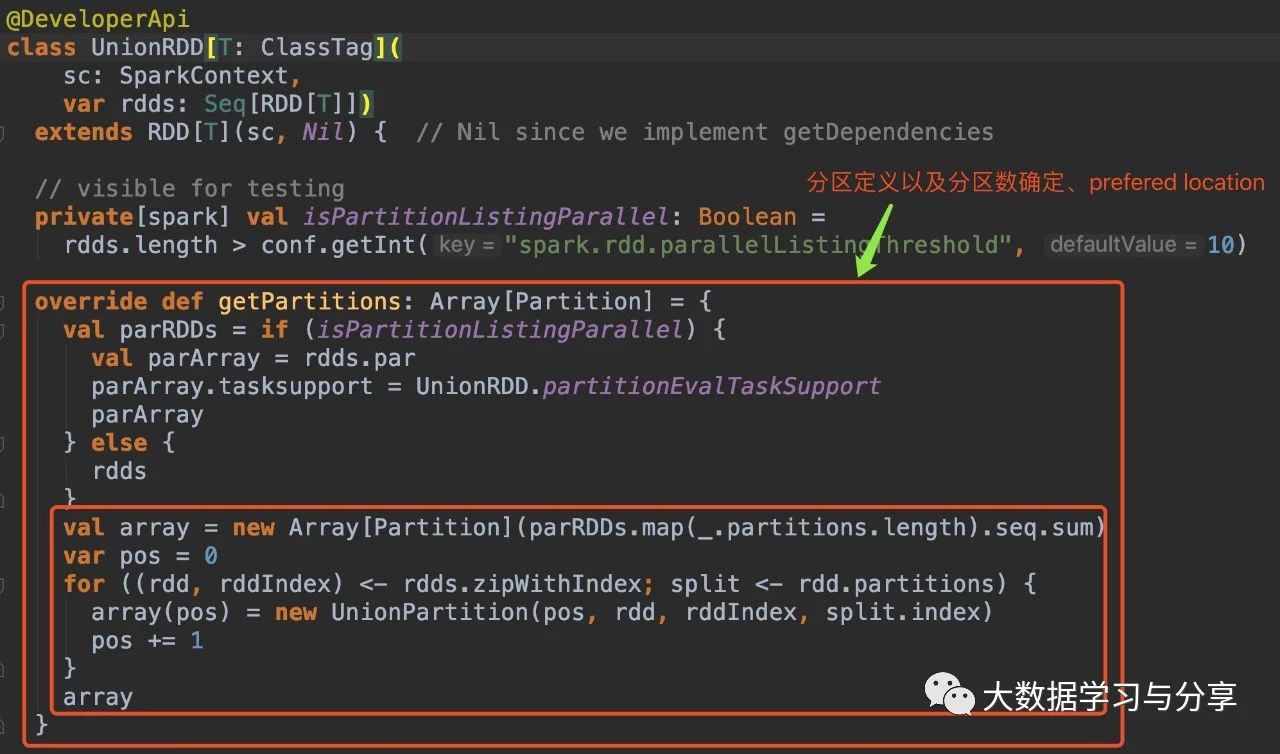
通过分析源码,RDD在调用union算子时,最终生成的RDD分区数分两种情况:1)union的RDD分区器已定义并且它们的分区器相同
多个父RDD具有相同的分区器,union后产生的RDD的分区器与父RDD相同且分区数也相同。比如,n个RDD的分区器相同且是defined,分区数是m个。那么这n个RDD最终union生成的一个RDD的分区数仍是m,分区器也是相同的
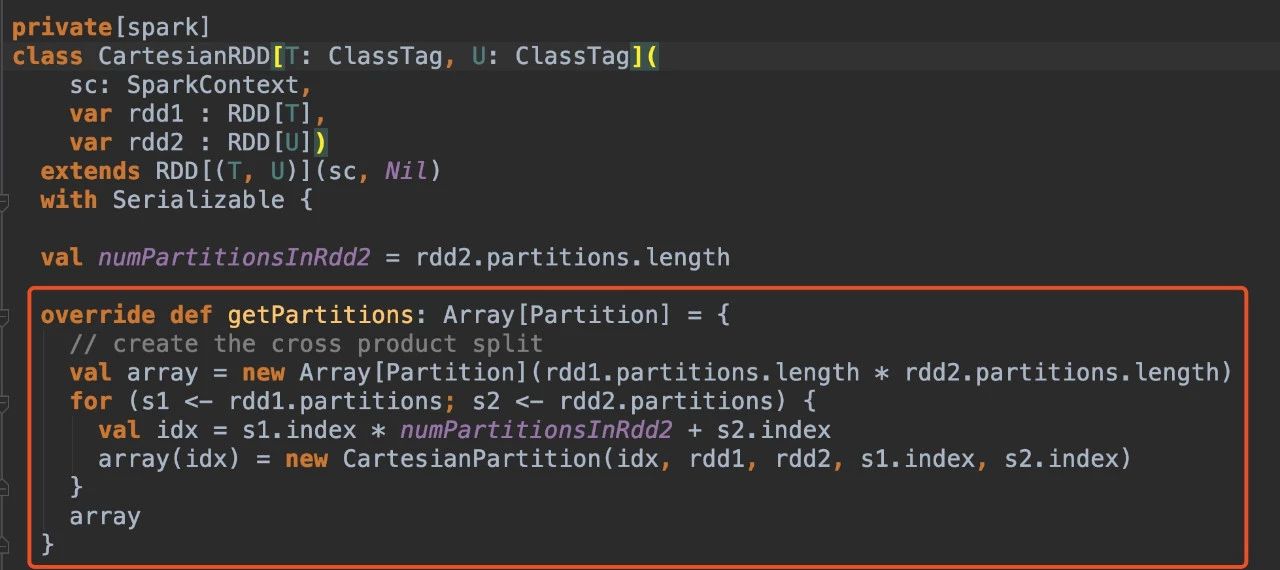
2)不满足第一种情况,则通过union生成的RDD的分区数为父RDD的分区数之和4.cartesian算子
通过上述coalesce、repartition、union算子介绍和源码分析,很容易分析cartesian算子的源码。通过cartesian得到RDD分区数是其父RDD分区数的乘积。
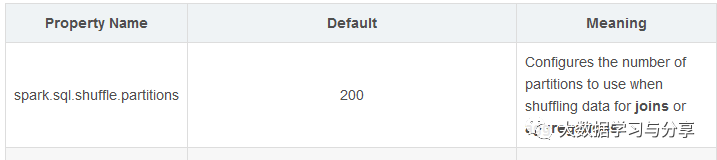
在Spark SQL中,任务并行度参数则要参考spark.sql.shuffle.partitions,笔者这里先放一张图,详细的后面讲到Spark SQL时再细说:
看下图在Spark流式计算中,通常将SparkStreaming和Kafka整合,这里又分两种情况:
1. Receiver方式生成的微批RDD即BlockRDD,分区数就是block数
2. Direct方式生成的微批RDD即kafkaRDD,分区数和kafka分区数一一对应
等说到Spark流式处理时再详细阐述。
关注微信公众号:大数据学习与分享,获取更对技术干货
重要 | Spark分区并行度决定机制的更多相关文章
- Hive和Spark分区策略
1.概述 离线数据处理生态系统包含许多关键任务,最大限度的提高数据管道基础设施的稳定性和效率是至关重要的.这边博客将分享Hive和Spark分区的各种策略,以最大限度的提高数据工程生态系统的稳定性和效 ...
- [Spark内核] 第35课:打通 Spark 系统运行内幕机制循环流程
本课主题 打通 Spark 系统运行内幕机制循环流程 引言 通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是從后往前划分的,执行的时候是從前往后执行的,每 ...
- 【Spark 深入学习-08】说说Spark分区原理及优化方法
本节内容 ------------------ · Spark为什么要分区 · Spark分区原则及方法 · Spark分区案例 · 参考资料 ------------------ 一.Spark为什 ...
- Spark学习之路 (十七)Spark分区
一.分区的概念 分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务 ...
- Spark cache、checkpoint机制笔记
Spark学习笔记总结 03. Spark cache和checkpoint机制 1. RDD cache缓存 当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出 ...
- Spark(十一)Spark分区
一.分区的概念 分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务 ...
- 打通 Spark 系统运行内幕机制循环流程
本课主题 打通 Spark 系统运行内幕机制循环流程 引言 通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是从后往前划分的,执行的时候是從前往后执行的,每 ...
- spark分区
spark默认的partition的分区数是和本机CPU的核数保持一致: bucket的数量和reduce的数量一致:buket的概念是map会将计算获得数据放到各个buket中,每个bucket和一 ...
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
随机推荐
- ubuntu vi编辑器上下左右为ABCD的解决办法
这个ubuntu系统自带的vi版本太老导致的,所以解决办法就是安装新版的vi编辑器: 首先卸载旧版本的vi编辑器: $sudo apt-get remove vim-common 然后安装新版的vi: ...
- Spark核心组件通识概览
在说Spark之前,笔者在这里向对Spark感兴趣的小伙伴们建议,想要了解.学习.使用好Spark,Spark的官网是一个很好的工具,几乎能满足你大部分需求.同时,建议学习一下scala语言,主要基于 ...
- linux(centos8):使用cgroups做资源限制
一,什么是cgroups? 1,cgroups是资源的控制组,它提供了一套机制用于控制一组特定进程对资源的使用. cgroups绑定一个进程集合到一个或多个限制资源使用的子系统上. 2, cg ...
- PHP程序员必须会的 45 个PHP 面试题
Q1: == 和 === 之间有什么区别? 话题: PHP困难: 如果是两个不同的类型,运算符 == 则在两个不同的类型之间进行强制转换 === 操作符执行'类型安全比较' 这意味着只有当两个操作数具 ...
- pv操作是否会造成死锁呢?
看了一些pv操作的例子,有一些基本原理不是想得很清楚. 有一个进程 while(true) { p(s); ...... v(s); } s的初值为1. 那么我的问题是,当多个该进程需要执行时,是否会 ...
- JAVA 基于Jusup爬虫
java爬虫核心:httpclient slf4j jsoup slf4j 配置文件log4j.properties log4j.rootlogger=DEBUG,A1log4j.logger.cn. ...
- C#番外篇-SpinWait
SpinWait封装常见旋转逻辑.在单处理器计算机上,始终使用 "生成" 而不是 "繁忙等待",在装有超线程技术的 Intel 处理器的计算机上,这有助于防止硬 ...
- maven 是什么
- 「IDEA插件精选」安利一个IDEA骚操作:一键生成方法的序列图
在平时的学习/工作中,我们会经常面临如下场景: 阅读别人的代码 阅读框架源码 阅读自己很久之前写的代码. 千万不要觉得工作就是单纯写代码,实际工作中,你会发现你的大部分时间实际都花在了阅读和理解已有代 ...
- 《SQL 必知必会》读书笔记
第1课 了解 SQL 这章主要介绍了数据库,表,字段类型,行,列,主键和SQL等基本概念. 数据库:以某种形式存储的数据集合,在计算机上的表现形式可能是一个文件或者一组文件.我们平时所说的数据库,往往 ...