springboot(4)Druid作为项目数据源(添加监控)
参考博客:恒宇少年:https://www.jianshu.com/p/e84e2709f383
Druid简介
Druid在监控、可扩展性、稳定性和性能方面具有明显的优势。
一、项目搭建,项目目录及数据库显示
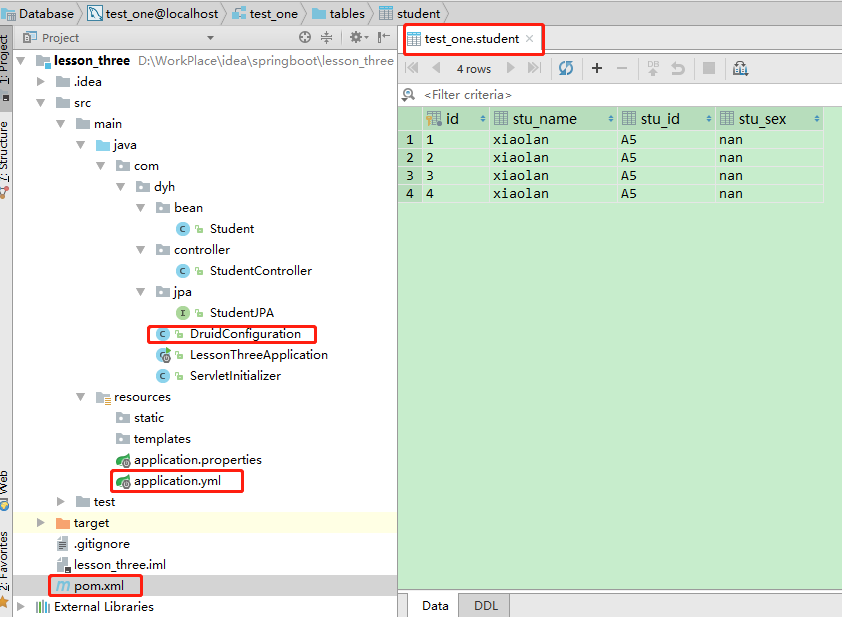
对应数据库的bean类
package com.dyh.bean; //import org.hibernate.annotations.Table; import javax.persistence.*;
import java.io.Serializable; @Entity
@Table(name = "student")
public class Student implements Serializable{
@Id
@GeneratedValue
@Column(name = "id")
private Long id; @Column(name = "stu_id")
private String sId; @Column(name = "stu_name")
private String name; @Column(name = "stu_sex")
private String sex; public Long getId() {
return id;
} public void setId(Long id) {
this.id = id;
} public String getsId() {
return sId;
} public void setsId(String sId) {
this.sId = sId;
} public String getName() {
return name;
} public void setName(String name) {
this.name = name;
} public String getSex() {
return sex;
} public void setSex(String sex) {
this.sex = sex;
} @Override
public String toString() {
return "Student{" +
"id=" + id +
", sId='" + sId + '\'' +
", name='" + name + '\'' +
", sex='" + sex + '\'' +
'}';
}
}
二、导入依赖
访问mvnrepository.com/artifact/com.alibaba/druid,选择依赖版本
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.2.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.dyh</groupId>
<artifactId>lesson_three</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>war</packaging>
<name>lesson_three</name>
<description>Demo project for Spring Boot</description> <properties>
<java.version>1.8</java.version>
</properties> <dependencies>
<dependency>
<!--spring-data-jpa-->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency> <dependency>
<!--ysql-connector-java的支持-->
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency> <dependency>
<!--如果使用的是内部Tomcat,那么应该注释掉<scope></scope>-->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
<!--<scope>provided</scope>-->
</dependency> <!--Druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.29</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency> </dependencies> <build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build> </project>
三、添加配置application.yml
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/test_one?serverTimezone=GMT%2B8
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: dyhroot
#最大活跃数
maxActive: 20
#初始化数量
initialSize: 1
#最大连接等待超时时间
maxWait: 60000
#打开PSCache,并且指定每个连接PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
#通过connectionProperties属性来打开mergeSql功能;慢SQL记录
#connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
minIdle: 1
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: select 1 from dual
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
#配置监控统计拦截的filters,去掉后监控界面sql将无法统计,'wall'用于防火墙
filters: stat, wall, log4j jpa:
database: MySQL
show-sql: true
hibernate:
# naming_strategy: org.hibernate.cfg.ImprovedNamingStrategy
# ddl-auto: create
format_sql: true
四、controller层代码及测试结果
@RestController
public class StudentController { @Autowired
private StudentJPA stuJPA; @RequestMapping(value = "/jpaList",method = RequestMethod.GET)
public List<Student> getStu(){
List<Student> all = stuJPA.findAll(); return stuJPA.findAll();
} @RequestMapping(value = "/jpaAddStu",method = RequestMethod.GET)
public Student addStu(Student student){
Student stu = new Student();
stu.setName("xiaolan");
stu.setSex("nan");
stu.setsId("A5");
Student save = stuJPA.save(stu);
return save;
}
}
启动后日志显示,证明SpringBoot已经把Druid当做dataSource加载到了项目中
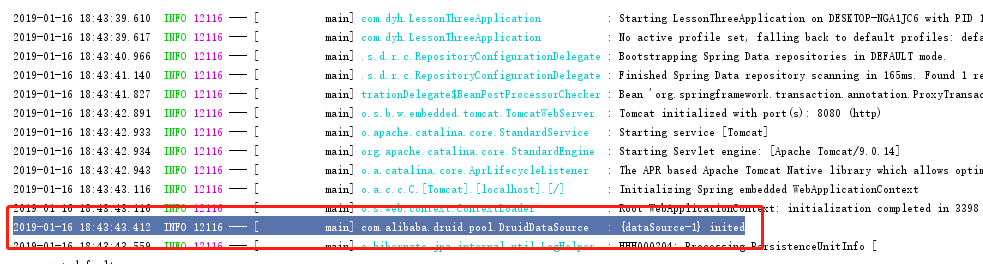
Druid监控功能
开启监控功能,可以在应用运行的过程中,通过监控提供的多维度数据来分析使用数据库的运行情况,从而可以调整程序设计,以便于优化数据库的访问性能。
一、实现Druid的访问Servlet以及Filter,实现代码如下:
package com.dyh; import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration; @Configuration
public class DruidConfiguration { @Bean
public ServletRegistrationBean statViewServlet(){
//创建servlet注册实体
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(),"/druid/*");
//设置ip白名单
servletRegistrationBean.addInitParameter("allow","127.0.0.1");
//设置ip黑名单,如果allow与deny共同存在时,deny优先于allow
servletRegistrationBean.addInitParameter("deny","192.168.0.19");
//设置控制台管理用户
servletRegistrationBean.addInitParameter("loginUsername","druid");
servletRegistrationBean.addInitParameter("loginPassword","123456");
//是否可以重置数据
servletRegistrationBean.addInitParameter("resetEnable","false");
return servletRegistrationBean;
} @Bean
public FilterRegistrationBean statFilter(){
//创建过滤器
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new WebStatFilter());
//设置过滤器过滤路径
filterRegistrationBean.addUrlPatterns("/*");
//忽略过滤的形式
filterRegistrationBean.addInitParameter("exclusions","*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
return filterRegistrationBean;
}
}
二、查看监控结果
项目运行成功后,我们要访问Druid的监控界面,访问地址:127.0.0.1:8080/druid/login.html,账户和密码是在我们代码中设定的:
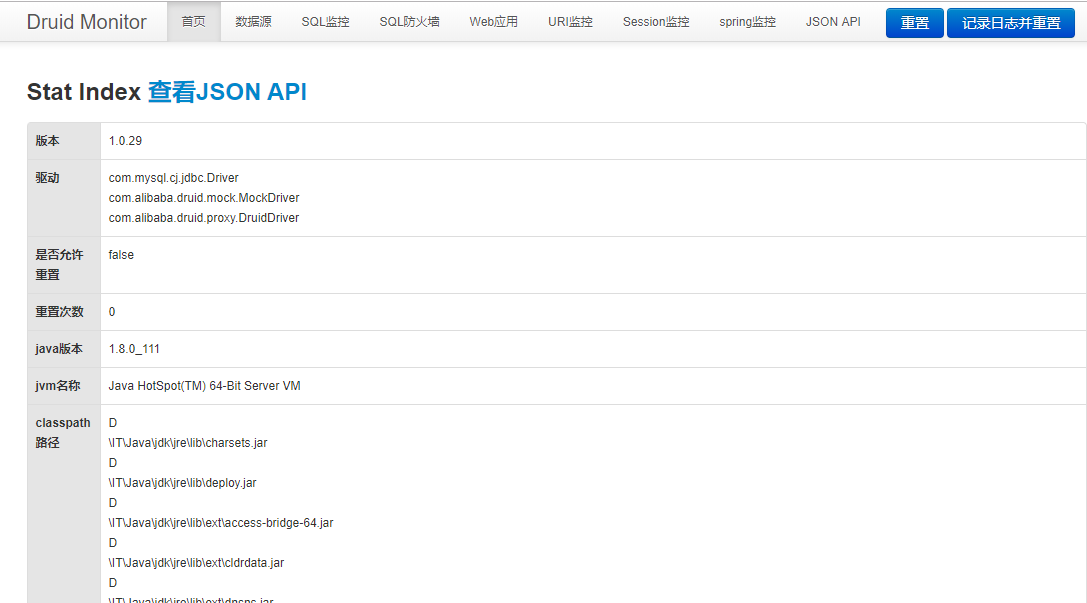
我们已经成功的访问到了监控首页,可以看到大致包含了如下几个模块:数据源、SQL监控、SQL防火墙、Web应用、URI监控、Session监控、JSONAPI等。
数据源
可以看到项目中管理的所有数据源配置的详细情况,除了密码没有显示外其他都在。
SQL监控
可以查看所有的执行sql语句
SQL防火墙
druid提供了黑白名单的访问,可以清楚的看到sql防护情况。
Web应用
可以看到目前运行的web程序的详细信息。
URI监控
可以监控到所有的请求路径的请求次数、请求时间等其他参数。
Session监控
可以看到当前的session状况,创建时间、最后活跃时间、请求次数、请求时间等详细参数。
JSONAPI
通过api的形式访问Druid的监控接口,api接口返回Json形式数据。
springboot(4)Druid作为项目数据源(添加监控)的更多相关文章
- SpringBoot 配置Druid:不显示SQL监控 —(*) property for user to setup
题外话: SpringBoot整合Druid 请查看https://www.cnblogs.com/JealousGirl/p/druid.html Druid登录后数据源页面.SQL监控等不显示数据 ...
- springboot整合druid数据库连接池并开启监控
简介 Druid是一个关系型数据库连接池,它是阿里巴巴的一个开源项目.Druid支持所有JDBC兼容的数据库,包括Oracle.MySQL.Derby.PostgreSQL.SQL Server.H2 ...
- Springboot+mybatis+druid 配置多数据源
项目结构 application.yml配置文件 spring: application: name: service datasource: primary: jdbc-url: jdbc:orac ...
- springboot和Druid整合配置数据源
@Configuration public class DruidConfiguration { @ConfigurationProperties(prefix = "spring.data ...
- springBoot(13)---整合Druid实现多数据源和可视化监控
SpringBoot整合Druid实现多数据源和可视化监控 先献上github代码地址:https://github.com/yudiandemingzi/springboot-manydatasou ...
- Springboot整合druid
目录 Springboot整合druid application.yml DruidConfig 数据监控地址:http://localhost:8080/druid Springboot整合drui ...
- Springboot+Druid 动态数据源配置监控
一.引入maven依赖,使用 starter 与原生 druid 依赖配置有所不同 <dependency> <groupId>com.alibaba</groupId& ...
- springboot配置Druid监控
整体步骤: (1) —— Druid简单介绍,具体看官网: (2) —— 在pom.xml配置druid依赖包: (3) —— 配置application.propertie ...
- 在Springboot2.0项目中使用Druid配置多数据源
在Springboot出现之前配置数据源以及相关的事物,缓存等内容一直是个繁琐的工作,但是Springboot出现后这些基本都可以靠默认配置搞定,就变得很轻松了.这就是现在推崇模板>配置的原因, ...
随机推荐
- Freemarker在replace替换是对NULL值的处理
freemarker的对象调用内建函数时,比如userInfo对象的birthDay函数,页面${userInfo.birthDay}调用,当我想将birthDay值中的“-”替换为“/”时,${us ...
- 【Model Log】模型评估指标可视化,自动画Loss、Accuracy曲线图工具,无需人工参与!
1. Model Log 介绍 Model Log 是一款基于 Python3 的轻量级机器学习(Machine Learning).深度学习(Deep Learning)模型训练评估指标可视化工具, ...
- 深入理解JVM(③)Java的模块化
前言 JDK9引入的Java模块化系统(Java Platform Module System ,JPMS)是 对Java技术的一次重要升级,除了像之前JAR包那样充当代码的容器之外,还包括: 依赖其 ...
- Linux虚拟机下安装Oracle 11G教程图文解说
1.安装环境 操作系统:Red hat 6.5 内存:内存最低要求256M (使用:grep MemTotal /proc/meminfo 命令查看) 交换空间:SWAP交换空间大小根据内存大小决定( ...
- Flutter轮播图
前端开发当中最有意思的就是实现动画特效,Flutter提供的各种动画组件可以方便实现各种动画效果.Flutter中的动画组件主要分为两类: 隐式动画控件:只需设置组件开始值,结束值,执行时间,比如An ...
- 什么是EL表达式?
1.什么是EL表达式? EL(Expression Language) 是为了使JSP写起来更加简单.表达式语言的灵感来自于 ECMAScript 和 XPath 表达式语言,它提供了在 JSP 中简 ...
- Python3笔记007 - 2.4 数据类型
第2章 python语言基础 python语法特点 保留字与标识符 变量 数据类型 运算符 输入和输出 2.4 数据类型 数据类型分为:空类型.布尔类型.数字类型.字节类型.字符串类型.元组类型.列表 ...
- Demo_2:Qt实现猜字小游戏
1 环境 系统:windows 10 代码编写运行环境:Qt Creator 4.4.1 (community) Github: 2 简介 参考视频:https://www.bilibili.co ...
- css transparent属性_css 透明颜色transparent的使用
在css中 transparent到底是什么意思呢? transparent 它代表着全透明黑色,即一个类似rgba(0,0,0,0)这样的值. 例如在css属性中定义:background:tran ...
- 阿里P7岗位面试,面试官问我:为什么HashMap底层树化标准的元素个数是8
前言 先声明一下,本文有点标题党了,像我这样的菜鸡何德何能去面试阿里的P7岗啊,不过,这确实是阿里p7级岗位的面试题,当然,参加面试的人不是我,而是我部门的一个大佬.他把自己的面试经验分享给了我,也让 ...