【SpringBoot1.x】SpringBoot1.x 检索
SpringBoot1.x 检索
概念
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;Elastic Stack 是适用于数据采集、充实、存储、分析和可视化的一组开源工具。人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
以 员工文档 的形式存储为例:一个 文档 代表一个员工数据。存储数据到 ElasticSearch 的行为叫做 索引 ,但在索引一个文档之前,需要确定将文档存储在哪里。
一个 ElasticSearch 集群可以 包含多个 索引 ,相应的每个索引可以包含多个 类型 。 这些不同的类型存储着多个 文档 ,每个文档又有多个 属性。
Elasticsearch 的用途:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
Elasticsearch 的工作原理:原始数据会从多个来源(包括日志、系统指标和网络应用程序)输入到 Elasticsearch 中。数据采集指在 Elasticsearch 中进行索引之前解析、标准化并充实这些原始数据的过程。这些数据在 Elasticsearch 中索引完成之后,用户便可针对他们的数据运行复杂的查询,并使用聚合来检索自身数据的复杂汇总。在 Kibana 中,用户可以基于自己的数据创建强大的可视化,分享仪表板,并对 Elastic Stack 进行管理。
整合 Elasticsearch
SpringBoot 默认支持两种技术来和 ES 交互:
- Jest,它默认不生效
- 使用它需要导入 jest 工具包,
io.searchbox.client.JestClient;
- 使用它需要导入 jest 工具包,
- SpringData Elasticsearch,默认生效,推荐使用它
- 使用 Client 节点,配置属性 clusterNodes、clusterName
- 用 ElasticsearchTemplate 操作 ES,或者
- 编写 ElasticsearchRepository 的子接口 来 操作 ES
安装测试
- Docker 安装 Elasticsearch:
docker pull elasticsearch:6.8.13 - 启动 Elasticsearch:
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -d elasticsearch:6.8.13,注意分配内存,默认为 2GB - 输入
http://localhost:9200/,若显示内容,则代表安装启动成功
Jest
导入依赖
<!-- https://mvnrepository.com/artifact/io.searchbox/jest -->
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>6.3.1</version>
</dependency>
编写配置文件
# 这也是默认值
spring.elasticsearch.jest.uris=http://localhost:9200
编写 Article 实体类:
public class Article { @JestId
private Integer id;
private String author;
private String title;
private String content; // constructor setter getter toString
}
编写测试文件:
@RunWith(SpringRunner.class)
@SpringBootTest
public class IntegrationSearchApplicationTests { @Autowired
JestClient jestClient; // Jest 操作 ES // 创建一个索引 http://localhost:9200/parzulpan/tips/1001
@Test
public void testJestCreate() {
// 给 ES 中 索引(保存)一个文档
Article article = new Article(1001, "消息通知", "zs", "Hello World"); // 构建一个索引
Index index = new Index.Builder(article).index("parzulpan").type("tips").build(); try {
// 执行
DocumentResult result = jestClient.execute(index);
System.out.println(result.getJsonString());
} catch (IOException e) {
e.printStackTrace();
}
} // 全文搜索
@Test
public void testJestSearch() {
// 全文搜索 查询表达式
String json = "{\n" +
" \"query\" : {\n" +
" \"match\" : {\n" +
" \"content\" : \"Hello\"\n" +
" }\n" +
" }\n" +
"}"; // 构建一个搜索
Search search = new Search.Builder(json).addIndex("parzulpan").addType("tips").build(); try {
// 执行
SearchResult result = jestClient.execute(search);
System.out.println(result.getJsonString());
} catch (IOException e) {
e.printStackTrace();
}
}
}
SpringData Elasticsearch
导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
注意,Spring1.5.22.RELEASE 默认使用的 elasticsearch 版本为 2.4.6。有可能和安装的 ES 版本不合适,可以参考官方说明,解决这个问题有两种方法:
升级 SpringBoot
安装对应的 Elasticsearch,安装:
docker pull elasticsearch:2.4.6,运行:docker run --name elasticsearch2 -p 9201:9200 -p 9301:9300 -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d elasticsearch:2.4.6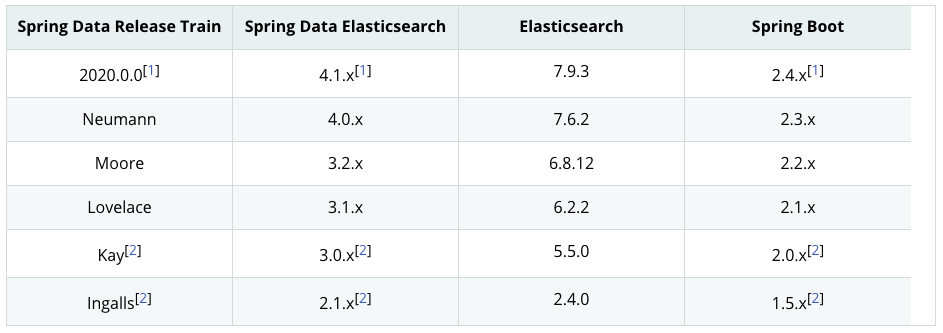
编写配置文件
# 这也是默认值
spring.elasticsearch.jest.uris=http://localhost:9200 ## elasticsearch:6.8.13
#spring.data.elasticsearch.cluster-name=docker-cluster
#spring.data.elasticsearch.cluster-nodes=localhost:9300 # elasticsearch:2.4.6
spring.data.elasticsearch.cluster-name=elasticsearch
spring.data.elasticsearch.cluster-nodes=localhost:9301
编写 Book 实体类
编写 ElasticsearchRepository 的子接口
/**
* @Author : parzulpan
* @Time : 2021-01
* @Desc : 操作 ES
*/ public interface BookRepository extends ElasticsearchRepository<Book, Integer> { // 更多可参考:https://docs.spring.io/spring-data/elasticsearch/docs/2.1.23.RELEASE/reference/html/#reference
public List<Book> findByBookNameLike(String bookName); // 自定义方法,按书名模糊查询
}
编写测试文件:
@RunWith(SpringRunner.class)
@SpringBootTest
public class IntegrationSearchApplicationTests { @Autowired
BookRepository bookRepository; // 编写 ElasticsearchRepository 的子接口 来 操作 ES // http://localhost:9201/parzulpan/book/1
@Test
public void testElasticsearchRepositoryCreate() {
Book book = new Book(1, "Elasticsearch 实战", "parzulpan");
Book index = bookRepository.index(book);
System.out.println(index);
} @Test
public void testElasticsearchRepositorySearch() {
List<Book> books = bookRepository.findByBookNameLike("实战");
System.out.println(books);
}
}
练习和总结
【SpringBoot1.x】SpringBoot1.x 检索的更多相关文章
- 【SpringBoot1.x】 Docker
SpringBoot1.x Docker 核心概念 Docker 是一个开源的应用容器引擎,是一个轻量级容器技术.Docker 支持将软件编译成一个镜像,然后在镜像中各种软件做好配置,将镜像发布出去, ...
- 记 SpringBoot1.* 转 Springoot2.0 遇到的问题
1.拦截器问题 到2.0之后在配置文件中写 static-path-pattern: /static/** 已经不起作用(2.0需要在方法中配置) SpringBoot1.*写法 @Configura ...
- SpringBoot1.x与监控(六)
由于2.x和1.x的监控不一样,此处先讲1.x 一 SpringBoot1.x监控 pom.xml <dependency> <groupId>org.springframew ...
- SpringBoot1.x升级SpringBoot2.x踩坑之文件上传大小限制
SpringBoot1.x升级SpringBoot2.x踩坑之文件上传大小限制 前言 LZ最近升级SpringBoo框架到2.1.6,踩了一些坑,这里介绍的是文件上传大小限制. 升级前 #文件上传配置 ...
- 使用SpringBoot1.4.0的一个坑
时隔半年,再次使用Spring Boot快速搭建微服务,半年前使用的版本是1.2.5,如今看官网最新的release版本是1.4.0,那就用最新的来构建,由于部署环境可能有多套所以使用maven-fi ...
- springboot1.5和jpa利用HikariCP实现多数据源的使用
背景 现在已有一个完整的项目,需要引入一个新的数据源,其实也就是分一些请求到从库上去 技术栈 springboot1.5 (哎,升不动啊) 思路 两个数据源,其中一个设置为主数据源 两个事物管理器,其 ...
- 【SpringBoot1.x】SpringBoot1.x 开发热部署和监控管理
SpringBoot1.x 开发热部署和监控管理 热部署 在开发中我们修改一个 Java 文件后想看到效果不得不重启应用,这导致大量时间花费,我们希望不重启应用的情况下,程序可以自动部署(热部署). ...
- 【SpringBoot1.x】SpringBoot1.x 分布式
SpringBoot1.x 分布式 分布式应用 Zookeeper&Dubbo ZooKeeper 是用于分布式应用程序的高性能协调服务.它在一个简单的界面中公开了常见的服务,例如命名,配置管 ...
- 【SpringBoot1.x】SpringBoot1.x 安全
SpringBoot1.x 安全 文章源码 环境搭建 SpringSecurity 是针对 Spring 项目的安全框架,也是 SpringBoot 底层安全模块默认的技术选型.他可以实现强大的 we ...
随机推荐
- javascript中 fn() 和 return fn() 的区别
在js中用return和不用return,输出结果有的时候傻傻搞不清,之前在网上看到个例子挺经典,不过讲的不清楚,上例子: var i = 0; function fn(){ i++; if ...
- Social Infrastructure Information Systems Division, Hitachi Programming Contest 2020 D题题解
将题意转换为一开始\(t = 0\),第\(i\)个操作是令\(t \leftarrow (a_i + 1) t + (a_i + b_i + 1)\).记\(A_i = a_i + 1, B_i = ...
- 【AtCoder AGC023F】01 on Tree(贪心)
Description 给定一颗 \(n\) 个结点的树,每个点有一个点权 \(v\).点权只可能为 \(0\) 或 \(1\). 现有一个空数列,每次可以向数列尾部添加一个点 \(i\) 的点权 \ ...
- springcloud gateway解决跨域问题
/** * 跨域允许 */ @Configuration public class CorsConfig { @Bean public WebFilter corsFilter() { return ...
- git+pycharm结合使用
Pycharm + git 进行结合使用 第一步:Pycharm配置本地安装的Git 测试框架的负责人: 编写好一套能用的基础框架代码 --- > 上传到公司远程仓库 --- 设置团队协作成员 ...
- 用 shell 脚本做日志清洗
问题的提出 公司有一个用户行为分析系统,可以记录用户在使用公司产品过程中的一系列操作轨迹,便于分析产品使用情况以便优化产品 UI 界面布局.这套系统有点类似于 Google Analyse(GA),所 ...
- day109:MoFang:好友列表显示&添加好友页面初始化&添加好友后端接口
目录 1.好友列表 2.添加好友-前端 3.服务端提供添加好友的后端接口 1.好友列表 1.在用户中心页面添加好友列表点击入口 html/user.html,用户中心添加好友列表点击入口,代码: &l ...
- Vue - 与后端交互
零:与后端交互 - ajax 版本1 - 出现了跨域问题 前端:index.html <!DOCTYPE html> <html lang="en"> &l ...
- 个人微信公众号搭建Python实现 -开发配置和微信服务器转入-配置说明(14.1.2)
@ 目录 1.查看基本配置 2.修改服务器配置 3.当上面都配置好,点击提交 4.配置如下 1.查看基本配置 登录到微信公众号控制面板后点击基本配置 这里要讲的就是订阅号 前往注册微信公众号 2.修改 ...
- 这个 bug 让我更加理解 Spring 单例了
我是风筝,公众号「古时的风筝」,一个兼具深度与广度的程序员鼓励师,一个本打算写诗却写起了代码的田园码农! 文章会收录在 JavaNewBee 中,更有 Java 后端知识图谱,从小白到大牛要走的路都在 ...