1.scrapy框架
Scrapy 是一个基于 Twisted 的异步处理框架。异步就是说调用在发出之后,这个调用就直接返回,不管有没有结果。(非阻塞关注的是程序在等待调用结果(消息、返回值)时的状态,指在不能立刻得到结果之前,不会阻塞当前线程。)
1.scrapy架构
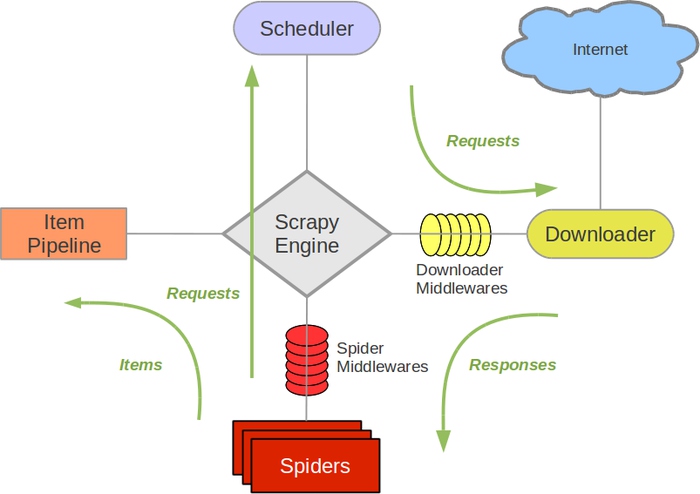
Engine,引擎,用来处理整个系统的数据流处理,触发事务,是整个框架的核心。引擎相当于总指挥,负责数据和信号在不同模块之间的传递。
Scheduler, 调度器,用来接受引擎发过来的请求并加入队列中,并在引擎再次请求的时候提供给引擎。调度器本质是个队列,存放引擎发过来的requestq请求。
Downloader,下载器,用于下载网页内容(request请求来源于引擎),并返回给引擎。
Item,项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该对象。
Spiders,蜘蛛,其内定义了爬取的逻辑和网页的解析规则,处理引擎发来的response,提取数据和url,并返回给引擎。
Item Pipeline,项目管道,负责处理引擎传来的数据,它的主要任务是清洗、验证和存储数据。
Downloader Middlewares,下载器中间件,位于引擎和下载器之间的钩子框架,主要是处理引擎与下载器之间的请求及响应。可以自定义下载扩展,比如设置代理。
Spider Middlewares, 蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛输入的响应和输出的结果及新的请求。可以自定义request请求和过滤response。
2.工作流程
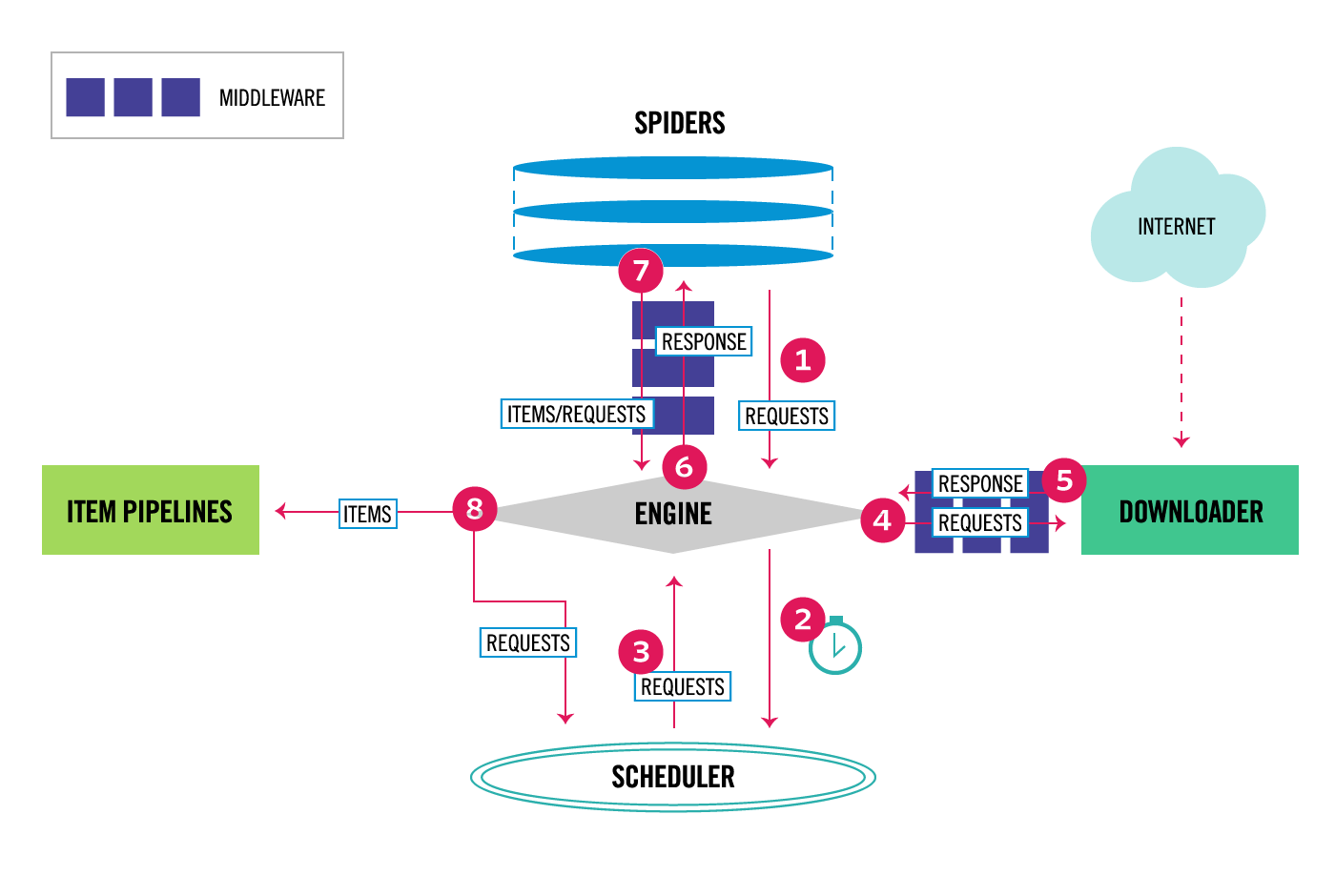
Engine 首先打开一个网站,找到处理该网站的 Spider 并向该 Spider 请求初始URL。
Spider将需要发送请求的url经ScrapyEngine(引擎)交给Scheduler(调度器)。
Scheduler(排序,入队)处理后,返回下一个要爬取的 URL 给 Engine,Engine 将 URL 通过 Downloader Middlewares 转发给 Downloader 下载。
一旦页面下载完毕, Downloader 生成一个该页面的 Response,并将其通过 Downloader Middlewares 发送给 Engine。
Engine 从下载器中接收到 Response 并通过 Spider Middlewares 发送给 Spider 处理。
Spider 处理 Response 并返回爬取到的 Item 及新的 Request 给 Engine。
Engine 将 Spider 返回的 Item 给 Item Pipeline,将新的 Request 给 Scheduler。
重复以上步骤,直到 Scheduler 中没有更多的 Request,Engine 关闭该网站,爬取结束
1.scrapy框架的更多相关文章
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Scrapy框架使用—quotesbot 项目(学习记录一)
一.Scrapy框架的安装及相关理论知识的学习可以参考:http://www.yiibai.com/scrapy/scrapy_environment.html 二.重点记录我学习使用scrapy框架 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 一个scrapy框架的爬虫(爬取京东图书)
我们的这个爬虫设计来爬取京东图书(jd.com). scrapy框架相信大家比较了解了.里面有很多复杂的机制,超出本文的范围. 1.爬虫spider tips: 1.xpath的语法比较坑,但是你可以 ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- 利用scrapy框架进行爬虫
今天一个网友问爬虫知识,自己把许多小细节都忘了,很惭愧,所以这里写一下大概的步骤,主要是自己巩固一下知识,顺便复习一下.(scrapy框架有一个好处,就是可以爬取https的内容) [爬取的是杨子晚报 ...
随机推荐
- 【集群实战】共享存储实时备份(解决nfs共享存储的单点问题)
1. nfs存储的单点问题 如果nfs服务器宕机了,则所有的nfs客户机都会受到影响.一旦宕机,会丢失部分用户的数据.为了解决单点问题,需要实现共享存储的实时备份,即:将nfs服务端共享目录下的数据实 ...
- Clustered和Nonclustered Indexes 各自得特点和区别及长短处
1 簇索引 簇索引对表的物理数据页中的数据按列进行排序然后再重新存储到磁盘上即簇索 引与数据是混为一体的它的叶节点中存储的是实际的数据由于簇索引对表中的数据一 一进行了排序因此用簇索引查找数据很快但由 ...
- openlayers3中Overlay用法
Overlay 从名字看,是覆盖图.覆盖物的意思,主要的用途就是在地图之上再覆盖一层,用以显示额外的可见元素,可见元素一般是 HTML 元素,利用 overlay,可以将可见元素放置到地图的任意位置, ...
- 基于HTML Canvas实现“指纹识别”技术
https://browserleaks.com/canvas 说明所谓指纹识别是指为每个设备标识唯一标识符(以下简称UUID).诸如移动原生的APP都可以通过调用相关设备API来获取相应的UUID. ...
- Blockchain
一.中心化 中心化原则是我们日常比较常见的支付手段. 科普文章喜欢用网购举例: 1.你在某宝支付了一件商品,钱先到马云爸爸手中,通知商家发货: 2.商家发货,你收货后确认无误,点击确认收货: 3.马云 ...
- 贪心--HDU 2021 发工资咯
Description 作为杭电的老师,最盼望的日子就是每月的8号了,因为这一天是发工资的日子,养家糊口就靠它了,呵呵,但是对于学校财务处的工作人员来说,这一天则是很忙碌的一天,财务处的小胡老师最近就 ...
- RF(scalar/list/dict变量)
一.scalar 变量 ${} 定义 scalar 变量 ${} 还用来取值 1.set variable 设置变量 ${name} Set Variable zhangsan log ${nam ...
- shell之路 Linux核心命令【第一篇】管道符与重定向
输出重定向 命令输出重定向的语法为: command > file 或 command >> file 这样,输出到显示器的内容就可以被重定向到文件.果不希望文件内容被覆盖,可以使用 ...
- Web前端基础第一天
Web标准的构成 结构:结构对于网页元素进行整理和分类,现阶段主要学的是html 表现:表现用于设置元素的板式.颜色.大小等外观样式,主要指的是CSS 行为:行为是指网页模型的定义及交互的编写,现阶段 ...
- Springboot邮件发送思路分析
毕业设计里需要邮件发送,所以学习,总的来讲,我考虑以下几点, 代码量少,代码简单.配置少,一看就懂,使用 JavaMail 太麻烦了. 异步执行,添加员工之后会发送入职邮件, 多线程处理,设计里有一个 ...