理解MapReduce计算构架
用Python编写WordCount程序任务
|
程序 |
WordCount |
|
输入 |
一个包含大量单词的文本文件 |
|
输出 |
文件中每个单词及其出现次数(频数),并按照单词字母顺序排序,每个单词和其频数占一行,单词和频数之间有间隔 |
1、编写map函数,reduce函数
(1)首先创建一个文件夹
mkdir wc
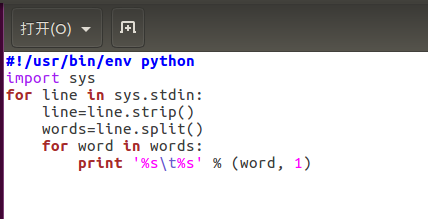
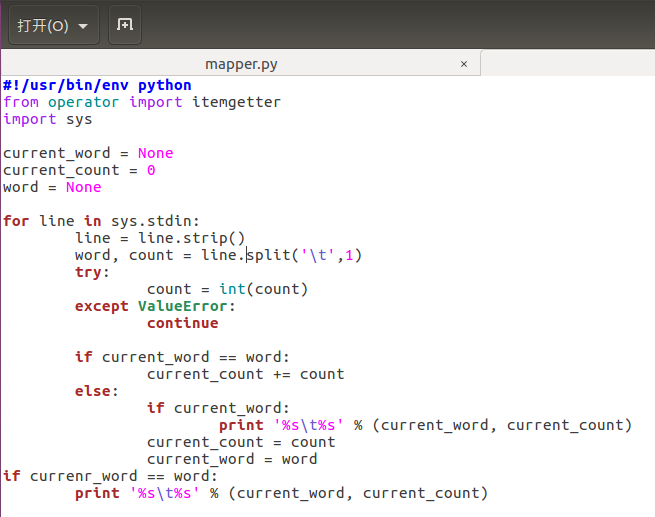
(2)编写两个mapper函数
2、将其权限作出相应修改

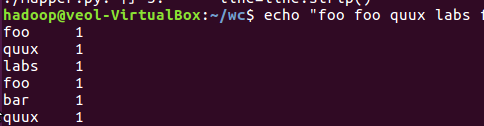
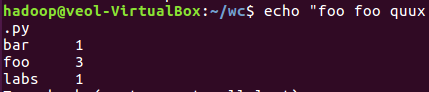
3、本机上测试运行代码
4、放到HDFS上运行,下载并上传文件到hdfs上



5、用Hadoop Streaming命令提交任务



理解MapReduce计算构架的更多相关文章
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之一:从WordCount理解MapReduce的几个阶段
WordCount是一个入门的MapReduce程序(从src\examples\org\apache\hadoop\examples粘贴过来的): package org.apache.hadoop ...
- 理解MapReduce哲学
Google工程师将MapReduce定义为一般的数据处理流程.一直以来不能完全理解MapReduce的真义,为什么MapReduce可以“一般”? 最近在研究Spark,抛开Spark核心的内存计算 ...
- 彻底理解MapReduce shuffle过程原理
彻底理解MapReduce shuffle过程原理 MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapR ...
- 简述MapReduce计算框架原理
1. MapReduce基本编程模型和框架 1.1 MapReduce抽象模型 大数据计算的核心思想是:分而治之.如下图所示.把大量的数据划分开来,分配给各个子任务来完成.再将结果合并到一起输出.注: ...
- MapReduce计算模型二
之前写过关于Hadoop方面的MapReduce框架的文章MapReduce框架Hadoop应用(一) 介绍了MapReduce的模型和Hadoop下的MapReduce框架,此文章将进一步介绍map ...
- 【CDN+】 Spark入门---Handoop 中的MapReduce计算模型
前言 项目中运用了Spark进行Kafka集群下面的数据消费,本文作为一个Spark入门文章/笔记,介绍下Spark基本概念以及MapReduce模型 Spark的基本概念: 官网: http://s ...
- 理解MapReduce
理解MapReduce Hadoop的MapReduce过程具有如下形式: 1) map: (K1, V1) => list(K2, V2) 2) redu ...
- MapReduce计算模型
MapReduce计算模型 MapReduce两个重要角色:JobTracker和TaskTracker. MapReduce Job 每个任务初始化一个Job,没个Job划分为两个阶段:Map和 ...
随机推荐
- 7-31 jmu-分段函数l (20 分)
本题目要求计算以下分段函数的值(x为从键盘输入的一个任意实数): 如果输入非数字,则输出“Input Error!” 输入格式: 在一行中输入一个实数x. 输出格式: 在一行中按”y=result”的 ...
- Asp.Net Core Endpoint 终结点路由之中间件应用
一.概述 这篇文章主要分享Endpoint 终结点路由的中间件的应用场景及实践案例,不讲述其工作原理,如果需要了解工作原理的同学, 可以点击查看以下两篇解读文章: Asp.Net Core EndPo ...
- 有史以来最全的CMD命令
说在前面的话: 本篇是博主通过网上查找整理而成的,且都是亲测可以的一些cmd命令,可以说是很齐全了,当然,如果有不可以运行的代码,欢迎大家留言指出,我会不断完善的,谢谢. CMD作用: 掌握一些基本的 ...
- Core + Vue 后台管理基础框架2——认证
1.前言 这块儿当时在IdentityServer4和JWT之间犹豫了一下,后来考虑到现状,出于3个原因,暂时放弃了IdentityServer4选择了JWT: (1)目前这个前端框架更适配JWT: ...
- linux最常用命令记录(一)
一.vim个人最常用设置: vim .vimrc 然后添加以下内容 set nu set tabstop=4 set encoding=utf-8 二.查看磁盘空间相关命令 1.df -h 查看硬 ...
- plist 图集 php 批量提取 PS 一个个切
最近,迷上了用 cocos2d 做游戏开发.由于是新入门,很多东西从头开始学. 在使用 sprite 的 Rect 裁剪显示的时候,显示总是多一块.所以,要从图集中提取一张张图,这样就省了裁剪. 原图 ...
- JavaFX之FXML+CSS创建窗体以及透明窗体添加阴影
前言 开通博客园有一段日子了,一直没空也没想好该写点什么.最近正好在做一个桌面程序,初次接触JavaFX,体验下来确实比swing好用不少.索性便记记学习笔记吧,虽然FX好像挺没存在感,没人用的感觉. ...
- js 实现简单的导航下拉列表
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 【Weiss】【第03章】增补附注
基本上每章到增补附注这里就算是结束了. 根据设想,每章的这一篇基本上会注明这一章哪些题没有做,原因是什么,如果以后打算做了也会在这里补充. 还有就是最后会把有此前诸多习题的代码和原数据结构放整理后,以 ...
- Python-生成器实现简单的"生产者消费者"模型
一.使用生成器实现简单的生产者消费者模型, 1.效果截屏 代码如下: import time def consumer(name): print('%s 开始买手机' %name) while Tru ...