Flink 历史服务与连接器
History Server(历史服务)
Flink提供了记录历史任务运行情况的服务,可用于在关闭Flink群集后依然能够查询已完成作业的相关信息。
配置:
# 任务执行信息存储在hdfs目录
jobmanager.archive.fs.dir: hdfs:///completed-jobs # history serever服务读取历史任务信息的目录
historyserver.archive.fs.dir: hdfs:///completed-jobs # history serever服务每隔多久到历史任务目录中轮询查看
historyserver.archive.fs.refresh-interval: 10000
配置完后, 选择一台机器, 启动 history server服务:
bin/historyserver.sh start
访问历史服务器 8082端口
Connector(连接器)
介绍
link Flink内置了一些基本数据源(source)和接收器(sink)。
除此之外它还提供了其他的连接器用于与各种第三方系统进行连接。
目前支持如下系统的连接:
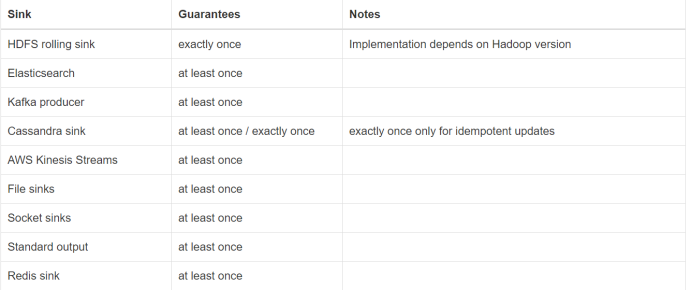
- Apache kafka (source/sink)
- ElasticSearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache NiFi (source/sink)
- Apache Cassandra (sink)
- Apache Kinesis Streams (source/sink)
- Twitter Streaming API (source)
在这些连接器中,当启动了Flink的容错机制之后,它分别能够保证不同的语义(at least once 和 exactly once)。
当连接器是 source 的时候

当连接器是 sink 的时候
Flink 历史服务与连接器的更多相关文章
- Hadoop 历史服务配置启动查看
历史服务配置启动查看 1)配置mapred-site.xml <property> <name>mapreduce.jobhistory.address</name> ...
- 配置spark历史服务(spark二)
1. 编辑spark-defaults.conf位置文件 添加spark.eventLog.enabled和spark.eventLog.dir的配置修改spark.eventLog.dir为我们之前 ...
- Apache Flink - 配置依赖,连接器,库
每个Flink程序都依赖于一组Flink库. 1.Flink核心和应用程序依赖项 Flink本身由一组类和运行需要的依赖组成.所有类和依赖的组合形成了Flink运行时的核心,并且当一个Flink程序运 ...
- Mapreduce 历史服务 配置启动查看
如果没有进行配置的话,那个History是不可以进行点击的,点击进去就会报错!所以需要进行配置一下 使用命令启动HistoryServer 就可以查看任务执行的进度了 命令: sbin/mr-jobh ...
- hadoop历史服务的启动与停止
a.配置项(在分布式环境中配置) 1.RPC访问地址 mapreduce.jobhistory.address 2.HTTP访问地址 mapreduce.jobhistory.webapp.addre ...
- Java_Activiti5_菜鸟也来学Activiti5工作流_之初识常用服务类和数据表(二)
/** * 代码清单中使用 ProcessEngines类加载默认的流程配置文件(activiti.cfg.xml),再获取各个服务组件的实例. * RepositoryService主要用于管理流程 ...
- 为PowerApps和Flow,Power BI开发自定义连接器
作者:陈希章 发表于 2017年12月20日 前言 我在之前用了几篇文章来介绍新一代微软商业应用平台三剑客(PowerApps,Microsoft Flow,Power BI),相信对于大家会有一种跃 ...
- How tomcat works 读书笔记十四 服务器组件和服务组件
之前的项目还是有些问题的,例如 1 只能有一个连接器,只能处理http请求,无法添加另外一个连接器用来处理https. 2 对容器的关闭只能是粗暴的关闭Bootstrap. 服务器组件 org.apa ...
- Hadoop基础-配置历史服务器
Hadoop基础-配置历史服务器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比 ...
随机推荐
- 十五 Spring的AOP的注解的通知类型,切入点的注解
Spring的注解的AOP的通知类型 @Before:前置通知 @AfterReturning:后置通知 @Around:环绕通知 @AfterThrowing:异常抛出通知 @After:最终通知 ...
- Ubuntu 安装MySQL并打开远程连接
首先使用su命令切换到root账户 在用apt-get install mysql-server命令获取到MySQL的服务 等待下载安装,按照提示输入MySQL的密码 安装完成后对mysqld.cnf ...
- 微信web版接口api(转)
安卓微信的api,个人微信开发API协议,微信 ipad sdk,微信ipad协议,微信web版接口api,微信网页版接口,微信电脑版sdk,微信开发sdk,微信开发API,微信协议,微信接口文档sd ...
- eclipse不能启动,An internal error occurred during: "reload maven project".
An internal error occurred during: "reload maven project". 这个错误是因为项目已经关闭,导致 导致此问题的原因是Sprin ...
- 跳蚤[BZOJ4310](后缀数组+二分答案传判定)
不知道后缀数组的请退回去! 题面: 题目描述 很久很久以前,森林里住着一群跳蚤.一天,跳蚤国王得到了一个神秘的字符串,它想进行研究.首先,他会把串分成不超过 k 个子串,然后对于每个子串 S,他会从S ...
- django 自定义模版过滤器
自定义的模版过滤器必须要放在app中,并且该app必须在INSTALLED_APPS中进行安装.然后再在这个app下面创建一个python包叫做templatetags(这个名字是固定的,不能随意更改 ...
- 超大数据量操作 java程序优化[转载]
一个表中有1000万以上的数据,要对其进行10万次以上的增删查改的操作,请问如何优化java程序对数据库的操作? 通过使用一些辅助性工具来找到程序中的瓶颈,然后就可以对瓶颈部分的代码进行优化. ...
- C++服务器与java进行socket通信案例
分类: [java]2012-10-08 12:03 14539人阅读 评论(46) 收藏 举报 注:本代码版权所有!!!转载时请声明源地址:http://blog.csdn.net/nuptboyz ...
- Task使用注意
1. CancellationTokenSource的使用 https://binary-studio.com/2015/10/23/task-cancellation-in-c-and-things ...
- 吴裕雄--天生自然JAVAIO操作学习笔记:字节流与字符流操作
import java.io.* ; public class Copy{ public static void main(String args[]){ if(args.length!=2){ // ...