Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup
Python简单爬虫入门一
上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素
首先回顾以下我们BeautifulSoup的基本结构如下
#!/usr/bin/env python
# -*-coding:utf-8 -*- from bs4 import BeautifulSoup
import requests headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
} url = "爬取网页的地址" web_data = requests.get(url,headers=headers)
soup = BeautifulSoup(web_data.text,"lxml")
重要事情再次强调这是我们开始爬取网页的一个基本结构,如同建楼的一个地基。
首先导入所需的工具也就是模块方法 from import
伪装浏览器headers向浏览器发出请求requests.get拿到返回结果在用BeautifulSoup以lxml格式解析网页代码
那么到这我们就开始取网页中我们想要的数据例如图片(一般都会放到标签img下的src内),标题(一般以title命名或者放入h3或a标签里),在就是内容也会放入和标题一样的
标签中怎么区分一般会通过CSS命名结构来区分。
1.先来抓去最直观的图片地址:
操作先鼠标右键也就是俗称反键--下一步点审查元素据可以找到你选取位置的元素地址:

是不是显示了图片的地址以及标签img src="这里放的连接就是图片地址"
那么我们接着我们上面的程序写如下代码来抓去图片地址标签:
from bs4 import BeautifulSoup
import requests headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
} url = "http://www.lotour.com/guoneiyou/" web_data = requests.get(url,headers=headers)
soup = BeautifulSoup(web_data.text,"lxml")
imgs = soup.select("img")
for img in imgs:
print img
大家其实只用在结构代码改变url地址,然后加入imgs = soup.select("img") 这写法就等于 变量名 = 赋值这个值是什么类型之类的
select是一个选择获取的方法如果大家用过mysql select * from table 是不是可以查看表内容一样的效果("img")就是获取哪标签,和mysql选取位置where类似
由于select是一次性获取返回列表,所以看起来很费劲再次我就用for循环去除每一个元素这样可以看到多行数据效果图如下:
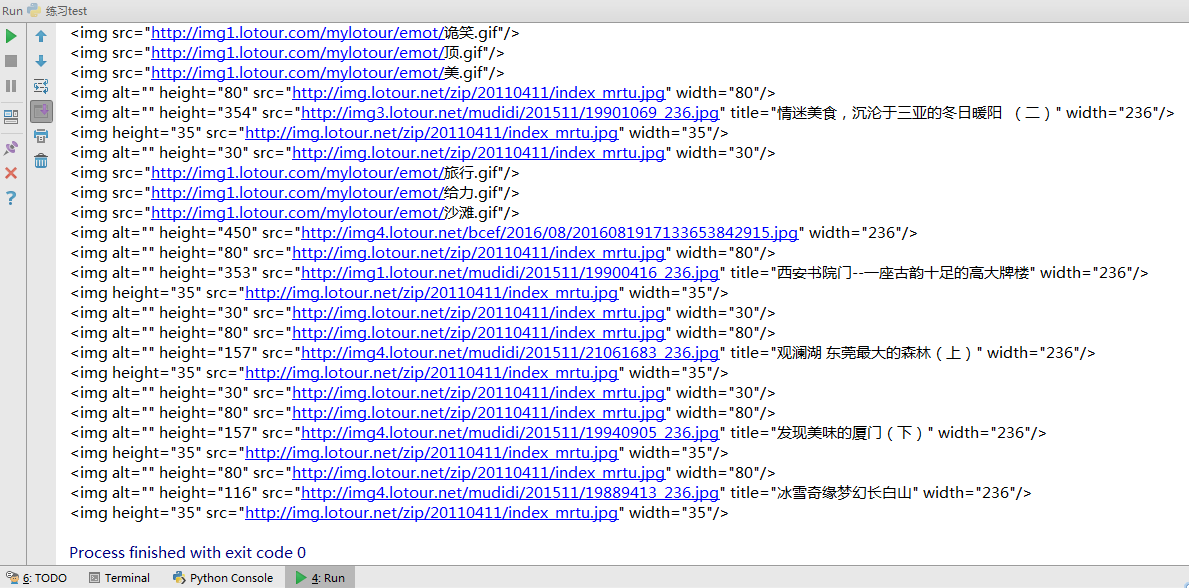
如何去除中间src方法有很几种其中例如正则匹配,不过我们有简单的内置方法想听结果如何下回分解。
无论工具多好用,得多用你才能熟练,现在我们继续抓去标题也可能是内容的当然还是一步步来熟练操作,
鼠标右键点击标题处或者是内容--点击审查元素效果如下:

这里一一对应了网页上的小标题以及源代码的位置及其标签 最后细心的朋友会发现html body div #container....div.auther p a这一行肯定会疑惑这是什么
其实这里就是网页标签的层级关系以及内容的定位作用想了解的去看我的HTML的基本组成结构与标签就会有所了解这里就不多介绍了
那么我们还是以基础结构添加以下代码来抓去网页的小标题,提醒网页的其它内容也同此原理,大家多练多想多总结很快就上手了。
titles = soup.select(" div.auther > p > a")
for title in titles:
print title
老规矩用select来选择获取的内容("div.auther > p > a")这就是网页定位标题的位置意思:在div标签CSS是auther中间用.点连接下的p标签下的a标签内
由于标签有层级结构我们要告诉代码去哪里找东西,打个比方BOSS要你去资料室,A柜里面的第三行中的马总公司资料拿来一样。
这里如过还是模糊我建议你试着去多练习抓去其它的元素多练习几次可能就有自己的理解见地,掩饰效果如下:

那么接下来就是大家自由发挥的事件了,是去爬各大购物网站的妹子也好,还是爬各大电影网站的电影名也好,只要多练习就熟练了,最后要提醒的是很多网站爬出来会
出现乱码当然这不是程序问题是网站的编码结构不一样需要去解码,对于解码不推荐小白去学,还是看了基础在研究,来叫大家怎么看网页的编码
还是右键-审查元素(有的网站会屏蔽此功能和查看源代码)查看网页中charset = "编码格式" 如果是标准utf-8还好 如果是gb2312或其它可能你抓的信息就会出现乱码
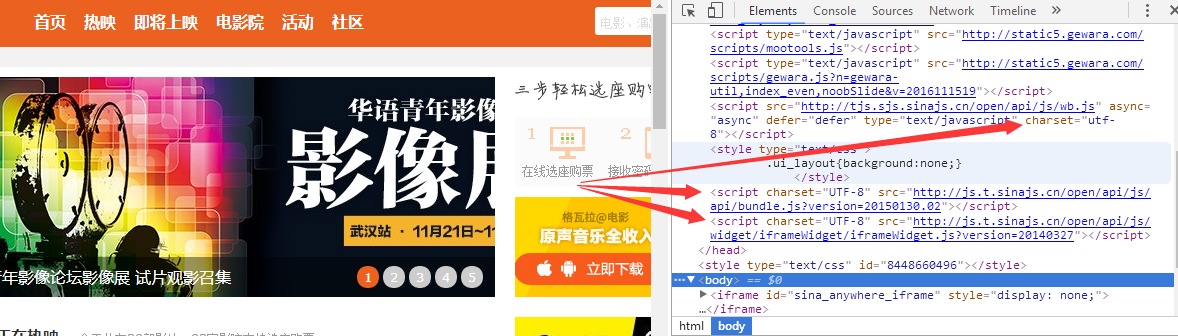
所以碰到此内问题 请小白绕道吧 因为如果你不学深入点很难解释,有基础的百度解决,我也会在以后专门写一次关于程序代码的标题(尽请期待)
最后你能独到这我只能说谢谢观看下次再会。。!
Python简单爬虫入门二的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题) 此工具在搜索 ...
- GJM : Python简单爬虫入门 (一) [转载]
版权声明:本文原创发表于 [请点击连接前往] ,未经作者同意必须保留此段声明!如有侵权请联系我删帖处理! 为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解 ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- 爬虫入门二 beautifulsoup
title: 爬虫入门二 beautifulsoup date: 2020-03-12 14:43:00 categories: python tags: crawler 使用beautifulsou ...
- python网络爬虫入门范例
python网络爬虫入门范例 Windows用户建议安装anaconda,因为有些套件难以安装. 安装使用pip install * 找出所有含有特定标签的HTML元素 找出含有特定CSS属性的元素 ...
随机推荐
- jQuery-1.9.1源码分析系列(六) 延时对象
首先我们需要明白延时对象有什么用? 第一个作用,解决时序以及动态添加执行函数的问题. function a(){alert(1)}; function b(){alert(2)}; function ...
- 数据结构Java实现01----算法概述
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
- Quartz.net 开源job调度框架(一)
Quartz.NET是一个开源的作业调度框架,非常适合在平时的工作中,定时轮询数据库同步,定时邮件通知,定时处理数据等. Quartz.NET允许开发人员根据时间间隔(或天)来调度作业.它实现了作业和 ...
- 模拟实现SQL Server字段列显示的数据类型
本文目录列表: 1.SQL Server表设计视图中的数据类型列展示效果 2.模拟实现类似的数据类型显示效果 3.测试效果 4.总结语 5.参考清单列表 1.SQL Server表设计视图中的数据 ...
- jquery css事件编程 位置 操作
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- assign()
- 用Spring Boot颠覆Java应用开发
Java开发概述: 使用Java做Web应用开发已经有近20年的历史了,从最初的Servlet1.0一步步演化到现在如此多的框架,库以及整个生态系统.经过这么长时间的发展,Java作为一个成熟的语言, ...
- HttpClient在HTTP协议接口测试中的使用
TTP协议的接口测试中,使用到最多的就是GET请求与POST请求,其中POST请求有FORM参数提交请求与RAW请求,下面我将结合HttpClient来实现一下这三种形式: 一.GET请求: GET请 ...
- GJM :异步Socket [转载]
原帖地址:http://blog.csdn.net/awinye/article/details/537264 原文作者:Awinye 目录(?)[-] 转载请原作者联系 Overview of So ...
- 基础算法(javascipt)总结
一.排序: 1.选择排序: 2.交换排序: 3.插入排序 二.查找: 三.节点遍历: 四.数组去重: 时间复杂度:找出算法中的基本语句->计算基本语句的执行次数的数量级->用大O记号表示算 ...