[转载]布隆过滤器(Bloom Filter)
[转载]布隆过滤器(Bloom Filter)
这部分学习资料来源:https://www.youtube.com/watch?v=v7AzUcZ4XA4
Filter判断不在,那就是肯定不在;Filter判断在,那只能说有一定几率在
有点乱啊,意思就是:布隆过滤器会倾向于判断在,这就是它的误差:它把可能不在的都说成是在。


用一个函数将元素映射到一个二进制数组中。当需要插入时,将插入元素映射为二进制位,如果数组中有至少对应的一个位不是1,就说明不在。
一个更完整的例子:

误差就是B!B本来不存在,但是判断就是存在了,所以就是判断失误了:它会将一些本来不存在的情况判断为存在。
正是因为这个误识别率,所以它被称为Filer,也就是“过滤器”,它的过滤效果不是100%的。
使用案例:

比特币网络:
PS,我个人是不相信区块链的,详见https://www.zhihu.com/question/43572793里大佬有理有据的解释,这里就是个例子

附上各个节点的含义:

SPV节点:快速判断是否有交易记录,说没有就是没有,用以提升效率

如果判断说存在,再去响应的区块中查。
来源:https://zhuanlan.zhihu.com/p/43263751
布隆过滤器数据结构
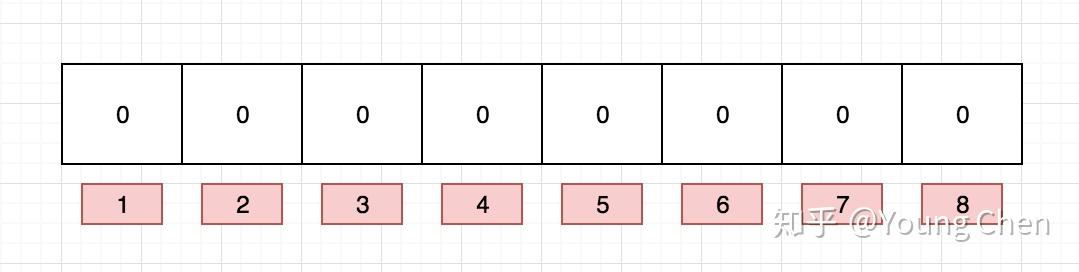
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
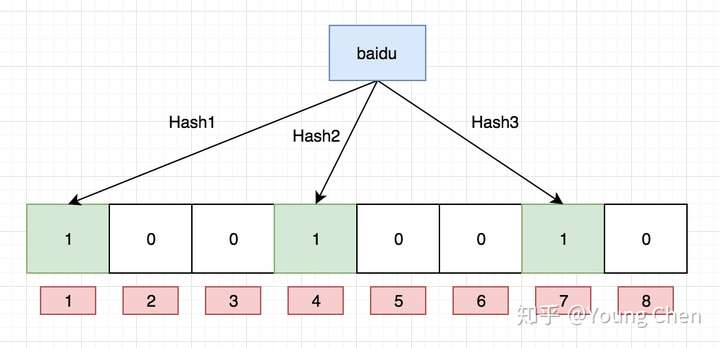
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
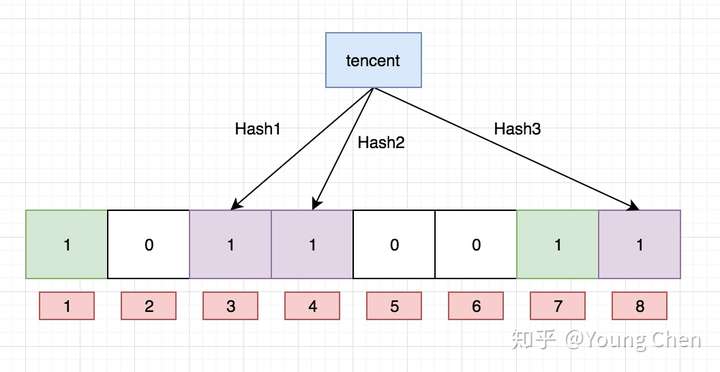
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
没有什么玄妙的,只是构建了多个哈希函数和一个二进制数组而已。每一个哈希函数将传入的对象映射为一个整数
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
支持删除么
目前我们知道布隆过滤器可以支持 add 和 isExist 操作,那么 delete 操作可以么,答案是不可以,例如上图中的 bit 位 4 被两个值共同覆盖的话,一旦你删除其中一个值例如 “tencent” 而将其置位 0,那么下次判断另一个值例如 “baidu” 是否存在的话,会直接返回 false,而实际上你并没有删除它。
布隆过滤器本身是不支持删除的,因为它违反了“说不在就不在”的原则
如何解决这个问题,答案是计数删除。但是计数删除需要存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。这样的话,增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于0。
如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率
如何计算布隆过滤器的误判率:
来源:https://www.zhihu.com/question/38573286
错误率
假设 Hash 函数以等概率条件选择并设置 Bit Array 中的某一位,假定由每个 Hash 计算出需要设置的位(bit) 的位置是相互独立, m 是该位数组的大小,k 是 Hash 函数的个数.
- 位数组中某一特定的位在进行元素插入时的 Hash 操作中没有被置位的概率是:
- 在所有 k 次 Hash 操作后该位都没有被置 "1" 的概率是:
- 如果我们插入了 n 个元素,那么某一位仍然为 "0" 的概率是:
- 该位为 "1"的概率是:
检测某一元素是否在该集合中。标明某个元素是否在集合中所需的 k 个位置都按照如上的方法设置为 "1",但是该方法可能会使算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positives),该概率由以下公式确定:
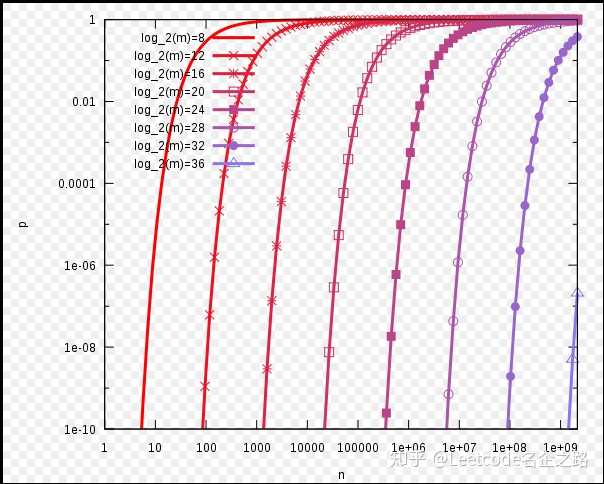
如何使得错误率最小,对于给定的m和n,当
的时候取值最小(求导就能算出来)。关系如下图所示:
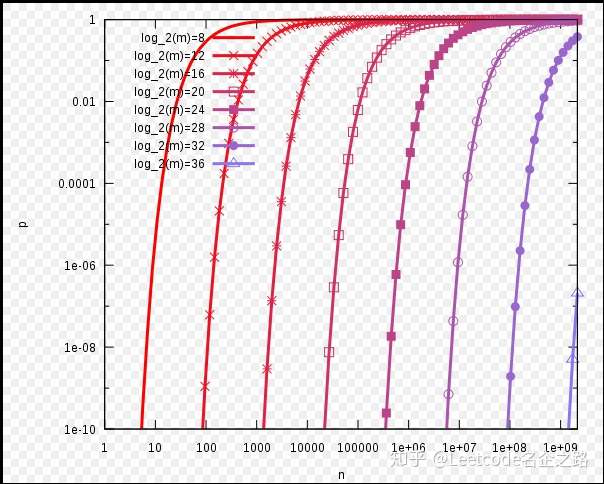
最佳实践
常见的适用常见有,*利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
另外,既然你使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,推荐 MurmurHash、Fnv 这些。
大Value拆分
Redis 因其支持 setbit 和 getbit 操作,且纯内存性能高等特点,因此天然就可以作为布隆过滤器来使用。但是布隆过滤器的不当使用极易产生大 Value,增加 Redis 阻塞风险,因此生成环境中建议对体积庞大的布隆过滤器进行拆分。
拆分的形式方法多种多样,但是本质是不要将 Hash(Key) 之后的请求分散在多个节点的多个小 bitmap 上,而是应该拆分成多个小 bitmap 之后,对一个 Key 的所有哈希函数都落在这一个小 bitmap 上。
[转载]布隆过滤器(Bloom Filter)的更多相关文章
- [转载] 布隆过滤器(Bloom Filter)详解
转载自http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- 布隆过滤器(Bloom Filter)详解——基于多hash的概率查找思想
转自:http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- 布隆过滤器(Bloom Filter)的原理和实现
什么情况下需要布隆过滤器? 先来看几个比较常见的例子 字处理软件中,需要检查一个英语单词是否拼写正确 在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上 在网络爬虫里,一个网址是否被访问过 yahoo, ...
- 布隆过滤器(Bloom Filter)详解
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中.和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一 ...
- 浅谈布隆过滤器Bloom Filter
先从一道面试题开始: 给A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL. 这个问题的本质在于判断一个元素是否在一个集合中.哈希表以O(1) ...
- 【面试突击】-缓存击穿(布隆过滤器 Bloom Filter)
原文地址:https://blog.csdn.net/fouy_yun/article/details/81075432 前面的文章介绍了缓存的分类和使用的场景.通常情况下,缓存是加速系统响应的一种途 ...
- 布隆过滤器 Bloom Filter 2
date: 2020-04-01 17:00:00 updated: 2020-04-01 17:00:00 Bloom Filter 布隆过滤器 之前的一版笔记 点此跳转 1. 什么是布隆过滤器 本 ...
- 布隆过滤器(Bloom Filter)-学习笔记-Java版代码(挖坑ing)
布隆过滤器解决"面试题: 如何建立一个十亿级别的哈希表,限制内存空间" "如何快速查询一个10亿大小的集合中的元素是否存在" 如题 布隆过滤器确实很神奇, 简单 ...
- 探索C#之布隆过滤器(Bloom filter)
阅读目录: 背景介绍 算法原理 误判率 BF改进 总结 背景介绍 Bloom filter(后面简称BF)是Bloom在1970年提出的二进制向量数据结构.通俗来说就是在大数据集合下高效判断某个成员是 ...
随机推荐
- (十九)C语言之指针
- TCP层close系统调用的实现分析
在调用close系统调用关闭套接字时,如果套接字引用计数已经归零,则需继续向上层调用其close实现,tcp为tcp_close:本文仅介绍tcp部分,前置部分请参考本博关于close系统调用的文章: ...
- CSS标签详解
CSS3标签 Css3概述 从2010年开始,HTML5与CSS3就一直是互联网技术中最受关注的两个话题.从前端技术的角度可以把互联网的发展分为三个阶段:第一阶段是web1.0以内容为主的网络,前端主 ...
- python基础_0623
命名的规则: project name package name python file name 1. 不能以数字开头,不能使用中文 2. 不能使用关键字 3. 英文 字母 ...
- FinalCutPro快捷键
FinalCutPro快捷键使用 FinalCutPro的快捷键使用十分有用,特对一些基本的快捷键进行了总结 1)i:截取片段开始Initial 2)o: 截取片段结束Over i和o可以在一个素材片 ...
- spark streaming 与 storm的对比
feature strom (trident) spark streaming 说明 并行框架 基于DAG的任务并行计算引擎(task parallel continuous computati ...
- 手机APP流量的发送与获取功能的实现
package com.loaderman.trafficdemo; import android.content.Context; import android.content.Intent; im ...
- JMeter4.0以上 分布式测试报错 "server failed start Listen failed on port"
使用JMeter4.0做分布式测试的是否,我的电脑作为肉鸡(执行机),双击jmeter-server.bat后显示失败 Found ApacheJMeter_core.jarUsing local p ...
- 深入理解红黑树及C++实现
介绍 红黑树是一种特殊的平衡二叉树(AVL),可以保证在最坏的情况下,基本动态集合操作的时间复杂度为O(logn).因此,被广泛应用于企业级的开发中. 红黑树的性质 在一棵红黑树中,其每个结点上增加了 ...
- GitLab 架构
GitLab 架构官方文档 GitLab 中文文档 版本 一般使用的是社区版(Community Edition,CE),此外还有企业版(Enterprise Edition,EE)可以使用. EE ...